Trabalhar com o editor de consultas v2
O editor de consultas v2 é usado principalmente para editar e executar consultas, visualizar resultados e compartilhar seu trabalho com sua equipe. Com o editor de consultas v2, é possível criar bancos de dados, esquemas, tabelas e funções definidas pelo usuário (UDFs). Em um painel de exibição em árvore, é possível visualizar os esquemas de cada um de seus bancos de dados. É possível visualizar tabelas, exibições, UDFs e procedimentos armazenados de cada esquema.
Tópicos
Abrir o editor de consultas v2
Para abrir o editor de consultas v2
Faça login no AWS Management Console e abra o console do Amazon Redshift em https://console.aws.amazon.com/redshiftv2/
. No menu do navegador, selecione Editor e Query editor V2 (Editor de consultas V2). O editor de consultas v2 é aberto em uma nova guia do navegador.
A página do editor de consultas tem um menu do navegador no qual você escolhe uma exibição da seguinte maneira:
- Editor
Você gerencia e consulta os dados organizados como tabelas e contidos em um banco de dados. O banco de dados pode conter dados armazenados ou uma referência a dados armazenados em outro lugar, como o Amazon S3. Você se conecta a um banco de dados contido em um cluster ou em um grupo de trabalho com tecnologia sem servidor.
Ao trabalhar na visualização Editor, você tem os seguintes controles:
O campo Cluster ou Workgroup (Grupo de trabalho) exibe o nome ao qual você está conectado no momento. O campo Database (Banco de dados) exibe os bancos de dados dentro do cluster ou grupo de trabalho. As ações que você executa na visualização Database (Banco de dados) padrão para atuar no banco de dados selecionado.
Uma visualização hierárquica de exibição em árvore de seus clusters ou grupos de trabalho, bancos de dados e esquemas. Em esquemas, é possível trabalhar com suas tabelas, exibições, funções e procedimentos armazenados. Cada objeto na exibição em árvore oferece suporte a um menu de contexto para executar ações associadas, como Refresh(Atualizar) ou Drop (Descartar), para o objeto.
Uma ação Create (Criar)
 para criar bancos de dados, esquemas, tabelas e funções.
para criar bancos de dados, esquemas, tabelas e funções.Uma ação
 Carregar dados para carregar dados do Amazon S3 ou de um arquivo local para o banco de dados.
Carregar dados para carregar dados do Amazon S3 ou de um arquivo local para o banco de dados.Um ícone Save (Salvar)
 para salvar sua consulta.
para salvar sua consulta. Um ícone Shortcuts (Atalhos)
 para exibir atalhos de teclado para o editor.
para exibir atalhos de teclado para o editor. Um ícone
 Mais para exibir mais ações no editor. Como:
Mais para exibir mais ações no editor. Como: Compartilhar com minha equipe: para compartilhar um caderno com sua equipe. Para ter mais informações, consulte Compartilhar e trabalhar em equipe.
Atalhos: para exibir atalhos de teclado para o editor.
Histórico de guias: para exibir o histórico de guias de uma guia no editor.
Atualizar preenchimento automático: para atualizar as sugestões exibidas ao criar SQL.
Uma área
 Editor na qual você pode digitar e executar uma consulta.
Editor na qual você pode digitar e executar uma consulta. Depois de executar uma consulta, é exibida a guia Result (Resultado) com os resultados. Aqui é onde você pode ativar Chart (Gráfico) para visualizar seus resultados. Você também pode Export (Exportar) os resultados.
Uma área
Notebook (Caderno) na qual você pode adicionar seções para inserir e executar SQL ou adicionar Markdown. Depois de executar uma consulta, é exibida a guia Result (Resultado) com os resultados. Aqui é lugar em que você pode Export (Exportar) os resultados.
- Consultas

Uma consulta contém os comandos SQL para gerenciar e consultar dados em um banco de dados. Ao usar o editor de consultas v2 para carregar dados de exemplo, ele também cria e salva consultas de exemplo para você.
Ao escolher uma consulta salva, é possível abri-la, renomeá-la e excluí-la usando o menu de contexto (clique com o botão direito do mouse). Você pode visualizar atributos, como o ARN da consulta, de uma consulta salva escolhendo Detalhes da consulta. Você também pode ver o histórico de versões, editar as etiquetas anexadas à consulta e compartilhá-la com sua equipe.
- Cadernos

Um caderno SQL contém células SQL e Markdown. Use cadernos SQL para organizar, anotar e compartilhar vários comandos SQL em um único documento.
Ao escolher um caderno salvo, é possível abri-lo, renomeá-lo, duplicá-lo e excluí-lo usando o menu de contexto (clique com o botão direito do mouse). Você pode visualizar atributos, como o ARN do caderno, de um caderno salvo escolhendo Detalhes do caderno. Você também pode ver o histórico de versões, editar as etiquetas anexadas ao caderno, exportá-lo e compartilhá-lo com sua equipe. Para ter mais informações, consulte Autorizar e executar blocos de anotações.
- Gráficos

Gráfico é uma representação visual dos dados. O editor de consultas v2 fornece ferramentas para criar vários tipos de gráfico e salvá-los.
Ao escolher um gráfico salvo, é possível abri-lo, renomeá-lo e excluí-lo usando o menu de contexto (clique com o botão direito do mouse). Você pode visualizar atributos, como o ARN do gráfico, de um gráfico salvo escolhendo Detalhes do gráfico. Você também pode editar as etiquetas anexadas ao gráfico e exportá-lo. Para ter mais informações, consulte Visualizar resultados da consulta.
- Histórico

O histórico de consultas é uma lista das consultas que você executou usando o editor de consultas v2 do Amazon Redshift. Essas consultas foram executadas como consultas individuais ou como parte de um caderno SQL. Para ter mais informações, consulte Visualizar o histórico de consultas e guias.
- Consultas programadas

Uma consulta programada é uma consulta configurada para iniciar em horários específicos.
Todas as visualizações do editor de consultas v2 têm os seguintes ícones:
Um ícone
 Visual mode (Modo visual) para alternar entre o modo claro e o modo escuro.
Visual mode (Modo visual) para alternar entre o modo claro e o modo escuro.Um ícone
 Settings (Configurações) para mostrar um menu das diferentes telas de configurações.
Settings (Configurações) para mostrar um menu das diferentes telas de configurações.Um ícone
 Editor preferences (Preferências do editor) para editar suas preferências ao usar o editor de consultas v2. Aqui você pode Editar configurações do espaço de trabalho para alterar o tamanho da fonte, o tamanho da guia e outras configurações de exibição. Você também pode ativar (ou desativar) o Preenchimento automático para mostrar sugestões ao inserir SQL.
Editor preferences (Preferências do editor) para editar suas preferências ao usar o editor de consultas v2. Aqui você pode Editar configurações do espaço de trabalho para alterar o tamanho da fonte, o tamanho da guia e outras configurações de exibição. Você também pode ativar (ou desativar) o Preenchimento automático para mostrar sugestões ao inserir SQL.Um ícone
 Connections (Conexões) para visualizar as conexões usadas pelas guias do editor.
Connections (Conexões) para visualizar as conexões usadas pelas guias do editor.A conexão é usada para recuperar dados de um banco de dados. Ela é criada para um banco de dados específico. Com uma conexão isolada, os resultados de um comando SQL que altera o banco de dados, como a criação de uma tabela temporária em uma guia do editor, não são visíveis em outra guia. Quando você abre uma guia no editor de consultas v2, o padrão é uma conexão isolada. Quando você cria uma conexão compartilhada, ou seja, desativa o botão Isolated session (Sessão isolada), os resultados em outras conexões compartilhadas com o mesmo banco de dados são visíveis entre si. No entanto, as guias do editor que usam uma conexão compartilhada com um banco de dados não são executadas em paralelo. As consultas que usam a mesma conexão devem aguardar até que a conexão esteja disponível. Uma conexão com um banco de dados não pode ser compartilhada com outro banco de dados e, portanto, os resultados SQL não são visíveis em diferentes conexões de banco de dados.
O número de conexões ativas que qualquer usuário na conta pode ter é controlado por um administrador do editor de consultas v2.
Um ícone
 Account settings (Configurações da conta) usado por um administrador para alterar determinadas configurações de todos os usuários na conta. Para obter mais informações, consulte Alterar as configurações da conta.
Account settings (Configurações da conta) usado por um administrador para alterar determinadas configurações de todos os usuários na conta. Para obter mais informações, consulte Alterar as configurações da conta.
Conectar-se a um banco de dados do Amazon Redshift
Para se conectar a um banco de dados, escolha o nome do cluster ou grupo de trabalho no painel de exibição em árvore. Caso seja solicitado, insira os parâmetros de conexão.
Ao se conectar a um cluster ou grupo de trabalho e a seus bancos de dados, você geralmente fornece um nome ao Database (Banco de dados). Você também fornece parâmetros necessários para um destes métodos de autenticação:
- IAM Identity Center
-
Com esse método, conecte-se ao data warehouse do Amazon Redshift usando as credenciais de logon único do provedor de identidades (IdP). O cluster ou o grupo de trabalho deve estar habilitado para o IAM Identity Center no console do Amazon Redshift. Para obter ajuda na configuração de conexões com o Centro de Identidade do IAM, consulte Conectar o Redshift ao IAM Identity Center para proporcionar aos usuários uma experiência de logon único.
- Usuário federado
-
Com esse método, as tags de entidades principais do usuário ou perfil do IAM devem fornecer os detalhes da conexão. Você configura essas etiquetas no AWS Identity and Access Management ou no provedor de identidades (IdP). O editor de consultas v2 se baseia nas etiquetas a seguir.
RedshiftDbUser: essa etiqueta define o usuário do banco de dados usado pelo editor de consultas v2. Essa etiqueta é obrigatória.RedshiftDbGroups: essa etiqueta define os grupos de banco de dados que são unidos ao se conectar ao editor de consultas v2. Essa etiqueta é opcional e seu valor deve ser uma lista separada por dois pontos, comogroup1:group2:group3. Valores vazios são ignorados, ou seja,group1::::group2é interpretado comogroup1:group2.
Essas etiquetas são encaminhadas à API do
redshift:GetClusterCredentialsa fim de obter credenciais para o cluster. Para ter mais informações, consulte Configuração de etiquetas de entidade principal para se conectar a um cluster ou a um grupo de trabalho pelo editor de consultas v2. - Credenciais temporárias usando um nome de usuário do banco de dados
-
Essa opção só está disponível ao se conectar a um cluster. Com esse método, o editor de consultas v2 fornece um User name (Nome de usuário) para o banco de dados. O editor de consultas v2 gera uma senha temporária para se conectar ao banco de dados como o nome de usuário do banco de dados. Um usuário que usa esse método para se conectar deve ter permissão do IAM para
redshift:GetClusterCredentials. Para impedir que os usuários usem esse método, modifique o perfil ou usuário do IAM para negar essa permissão. - Credenciais temporárias usando sua identidade do IAM
-
Essa opção só está disponível ao se conectar a um cluster. Com esse método, o editor de consultas v2 mapeia um nome de usuário para a identidade do IAM e gera uma senha temporária para se conectar ao banco de dados como a identidade do IAM. Um usuário que usa esse método para se conectar deve ter permissão do IAM para
redshift:GetClusterCredentialsWithIAM. Para impedir que os usuários usem esse método, modifique o perfil ou usuário do IAM para negar essa permissão. - Nome de usuário e senha do banco de dados
-
Com esse método, forneça também um User name (Nome de usuário) e uma Password (Senha) para o banco de dados ao qual você está se conectando. O editor de consultas v2 cria um segredo em seu nome armazenado em AWS Secrets Manager. Este segredo contém credenciais para se conectar ao seu banco de dados.
- AWS Secrets Manager
-
Com esse método, em vez de um nome de banco de dados, forneça um Secret (Segredo) armazenado no Secrets Manager que contém seu banco de dados e credenciais de login. Para obter informações sobre como criar um segredo, consulte Criar um segredo para credenciais de conexão de banco de dados.
Ao selecionar um cluster ou grupo de trabalho com o editor de consultas v2, dependendo do contexto, é possível criar, editar e excluir conexões usando o menu de contexto (clique com o botão direito do mouse). Você pode visualizar atributos, como o ARN da conexão, escolhendo Detalhes da conexão. Você também pode editar as etiquetas anexadas à conexão.
Navegar por um banco de dados do Amazon Redshift
Em um banco de dados, você pode gerenciar esquemas, tabelas, visualizações, funções e procedimentos armazenados no painel de exibição em árvore. Cada objeto da exibição tem ações associadas a ele em um menu de contexto (clique com o botão direito do mouse).
O painel de exibição em árvore hierárquica exibe objetos do banco de dados. Para atualizar o painel de visualização em árvore a fim de exibir objetos do banco de dados que possam ter sido criados após a última exibição da visualização em árvore, selecione o ícone
 . Abra o menu de contexto (clique com o botão direito do mouse) de um objeto para ver quais ações você pode executar.
. Abra o menu de contexto (clique com o botão direito do mouse) de um objeto para ver quais ações você pode executar.
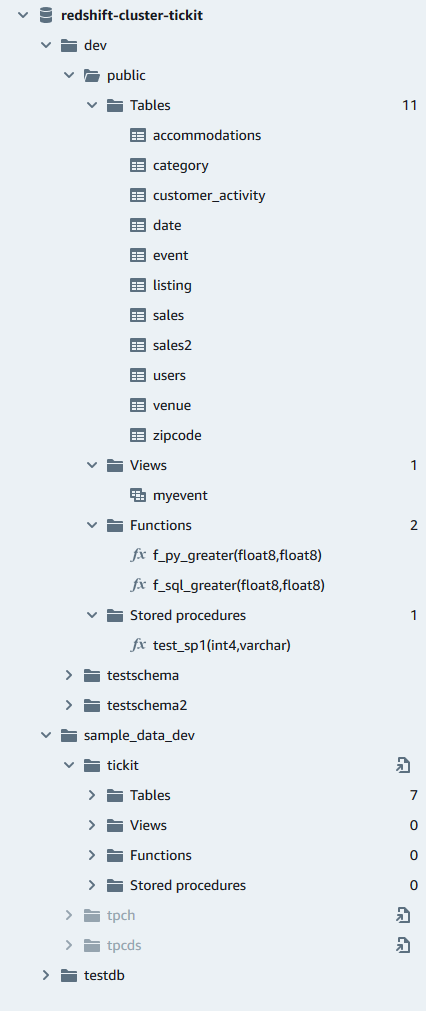
Depois de escolher uma tabela, você pode fazer o seguinte:
Para iniciar uma consulta no editor com uma instrução SELECT que consulta todas as colunas da tabela, use Select table (Selecionar tabela).
Para ver os atributos ou uma tabela, use Show table definition (Exibir definição de tabela). Use isso para ver nomes de colunas, tipos de coluna, codificação, chaves de distribuição, chaves de classificação e verificar se uma coluna pode conter valores nulos. Para obter mais informações sobre atributos de tabela, consulte CREATE TABLE no Guia do desenvolvedor de banco de dados do Amazon Redshift.
Para excluir uma tabela, use Delete (Excluir). Você também pode usar Truncate table (Truncar tabela) para excluir todas as linhas da tabela ou Drop table (Descartar tabela) para remover a tabela do banco de dados. Para obter mais informações, consulte TRUNCATE e DROP TABLE no Guia do desenvolvedor de banco de dados do Amazon Redshift.
Escolha um esquema para Refresh (Atualizar) ou Drop schema (Descartar esquema).
Escolha uma visualização para Show view definition (Exibir definição de visualização) ou Drop view (Descartar visualização).
Escolha uma função para Show function definition (Exibir definição de função) ou Drop function (Descartar função).
Escolha um procedimento armazenado para Show procedure definition (Exibir definição de procedimento) ou Drop procedure (Descartar procedimento).
Criar objetos de banco de dados
É possível criar objetos de banco de dados, inclusive bancos de dados, esquemas, tabelas e funções definidas pelo usuário (UDFs). Você deve estar conectado a um cluster ou grupo de trabalho e a um banco de dados para criar objetos de banco de dados.
Criar bancos de dados
É possível usar o editor de consultas v2 para criar bancos de dados no cluster ou grupo de trabalho.
Para criar um banco de dados
Para obter informações sobre bancos de dados, consulte CREATE DATABASE no Guia do desenvolvedor de banco de dados do Amazon Redshift.
Selecione
Create (Criar) e escolha Database (Banco de dados).Insira um Database name (Nome do banco de dados).
(Opcional) Selecione Users and groups (Usuários e grupos) e escolha um Database user (Usuário do banco de dados).
(Opcional) Você pode criar o banco de dados por meio da unidade de compartilhamento de dados ou do AWS Glue Data Catalog. Para obter mais informações sobre o AWS Glue, consulte O que é o AWS Glue? no Guia do desenvolvedor do AWS Glue.
(Opcional) Selecione Criar usando uma unidade de compartilhamento de dados e escolha Selecione uma unidade de compartilhamento de dados. A lista inclui unidades de compartilhamento de dados do produtor que podem ser usadas para criar uma unidade de compartilhamento de dados do consumidor no cluster ou grupo de trabalho atual.
(Opcional) Selecione Criar usando o AWS Glue Data Catalog e Selecione um banco de dados do AWS Glue. Em Esquema do catálogo de dados, insira o nome que será usado para o esquema ao se referir aos dados em um nome de três partes (database.schema.table).
Selecione Criar banco de dados.
O novo banco de dados é exibido no painel de exibição em árvore.
Ao passar pela etapa opcional de consultar um banco de dados criado por uma unidade de compartilhamento de dados, conecte-se a um banco de dados do Amazon Redshift no cluster ou grupo de trabalho (por exemplo, o banco de dados padrão
dev) e use a notação de três partes (database.schema.table) que faça referência ao nome do banco de dados que você criou quando selecionou Criar usando uma unidade de compartilhamento de dados. O banco de dados da unidade de compartilhamento de dados está listado na guia “Editor” do editor de consultas v2 mas não está habilitado para conexão direta.Ao passar pela etapa opcional de consultar um banco de dados criado por meio de um AWS Glue Data Catalog, conecte-se ao banco de dados do Amazon Redshift no cluster ou grupo de trabalho (por exemplo, o banco de dados padrão
dev) e use a notação de três partes (database.schema.table) que faça referência ao nome do banco de dados que você criou quando selecionou Criar usando o AWS Glue Data Catalog, o esquema que você nomeou em Esquema do catálogo de dados e a tabela no AWS Glue Data Catalog. Similar a:SELECT * FROMglue-database.glue-schema.glue-tablenota
Confirme se conexão com o banco de dados padrão está utilizando o método de conexão Credenciais temporárias usando sua identidade do IAM e se as credenciais do IAM receberam privilégios de uso para o banco de dados do AWS Glue.
GRANT USAGE ON DATABASEglue-databaseto "IAM:MyIAMUser"O banco de dados do AWS Glue está listado na guia “Editor” do editor de consultas v2 mas não está habilitado para conexão direta.
Para obter mais informações sobre como consultar um AWS Glue Data Catalog, consulte Trabalhar com unidades de compartilhamento de dados gerenciadas pelo Lake Formation como consumidor e Trabalhar com unidades de compartilhamento de dados gerenciadas pelo Lake Formation como produtor no Guia do desenvolvedor de banco de dados do Amazon Redshift.
Exemplo de criação de um banco de dados como consumidor da unidade de compartilhamento de dados
O exemplo a seguir descreve um cenário específico que foi usado para criar um banco de dados com base em uma unidade de compartilhamento de dados usando o editor de consultas v2. Analise esse cenário para saber como você pode criar um banco de dados com base em uma unidade de compartilhamento de dados em seu ambiente. Esse cenário usa dois clusters: cluster-base (o cluster do produtor) e cluster-view (o cluster do consumidor).
Use o console do Amazon Redshift para criar uma unidade de compartilhamento de dados para a tabela
category2no clustercluster-base. A unidade de compartilhamento de dados do produtor é chamadadatashare_base.Para obter informações sobre como criar unidades de compartilhamento de dados, consulte Compartilhar dados entre clusters no Amazon Redshift no Guia do desenvolvedor de banco de dados do Amazon Redshift.
Use o console do Amazon Redshift para aceitar a unidade de compartilhamento de dados
datashare_basecomo consumidor para a tabelacategory2no clustercluster-view.Exiba o painel de visualização em árvore no editor de consultas v2, que mostra a hierarquia de
cluster-basecomo:Cluster:
cluster-baseBanco de dados:
devEsquema:
publicTabelas:
category2
Selecione
Create (Criar) e escolha Database (Banco de dados).Insira
see_datashare_baseem Nome do banco de dados.Selecione Criar usando uma unidade de compartilhamento de dados e escolha Selecione uma unidade de compartilhamento de dados. Escolha
datashare_basepara usar como fonte do banco de dados que você está criando.O painel de visualização em árvore no editor de consultas v2 mostra a hierarquia de
cluster-viewcomo:Cluster:
cluster-viewBanco de dados:
see_datashare_baseEsquema:
publicTabelas:
category2
Ao consultar os dados, conecte-se ao banco de dados padrão do cluster
cluster-view(normalmente chamadodev), mas faça referência ao banco de dados da unidade de compartilhamento de dadossee_datashare_baseno SQL.nota
Na visualização do editor de consultas v2, o cluster selecionado é
cluster-view. O banco de dados selecionado édev. O banco de dadossee_datashare_baseestá listado mas não está habilitado para conexão direta. Você escolhe o banco de dadosdeve faz referência asee_datashare_baseno SQL que executa.SELECT * FROM "see_datashare_base"."public"."category2";A consulta recupera dados da unidade de compartilhamento de dados
datashare_baseno clustercluster_base.
Exemplo de criação de um banco de dados por meio de um AWS Glue Data Catalog
O exemplo a seguir descreve um cenário específico que foi usado para criar um banco de dados por meio de um AWS Glue Data Catalog usando o editor de consultas v2. Analise esse cenário para saber como você pode criar um banco de dados por meio de um AWS Glue Data Catalog em seu ambiente. Esse cenário usa um cluster, cluster-view, para conter o banco de dados que você cria.
Selecione
Create (Criar) e escolha Database (Banco de dados).Insira
data_catalog_databaseem Nome do banco de dados.Selecione Criar usando um AWS Glue Data Catalog e escolha Selecione um banco de dados do AWS Glue. Escolha
glue_dbpara usar como fonte do banco de dados que você está criando.Escolha Esquema do catálogo de dados e insira
myschemacomo o nome do esquema a ser usado na notação de três partes.O painel de visualização em árvore no editor de consultas v2 mostra a hierarquia de
cluster-viewcomo:Cluster:
cluster-viewBanco de dados:
data_catalog_databaseEsquema:
myschemaTabelas:
category3
Ao consultar os dados, conecte-se ao banco de dados padrão do cluster
cluster-view(normalmente chamadodev), mas faça referência ao banco de dadosdata_catalog_databaseno SQL.nota
Na visualização do editor de consultas v2, o cluster selecionado é
cluster-view. O banco de dados selecionado édev. O banco de dadosdata_catalog_databaseestá listado mas não está habilitado para conexão direta. Você escolhe o banco de dadosdeve faz referência adata_catalog_databaseno SQL que executa.SELECT * FROM "data_catalog_database"."myschema"."category3";A consulta recupera dados catalogados pelo AWS Glue Data Catalog.
Criar esquemas
É possível usar o editor de consultas v2 para criar esquemas no cluster ou grupo de trabalho.
Para criar um esquema
Para obter informações sobre esquemas, consulte Esquemas no Guia do desenvolvedor de banco de dados do Amazon Redshift.
Selecione
Create (Criar) e escolha Schema (Esquema).Digite um Schema name (Nome do esquema).
Escolha Local ou External (Externo) como Schema type (Tipo de esquema).
Para obter mais informações sobre esquemas, consulte CREATE SCHEMA no Guia do desenvolvedor de banco de dados do Amazon Redshift. Para obter mais informações sobre esquemas, consulte EXTERNAL SCHEMA no Guia do desenvolvedor de banco de dados do Amazon Redshift.
Se escolher External (Externo), você terá as opções de um esquema externo a seguir.
Glue Data Catalog: para criar um esquema externo no Amazon Redshift que se refira a tabelas no AWS Glue. Além de escolher o banco de dados do AWS Glue, selecione o perfil do IAM associado ao cluster e o perfil do IAM associado ao catálogo de dados.
PostgreSQL: para criar um esquema externo no Amazon Redshift que se refira a um banco de dados do Amazon RDS para PostgreSQL ou do Amazon Aurora compatível com PostgreSQL. Forneça também as informações de conexão com o banco de dados. Para obter mais informações sobre consultas federadas, consulte Querying data with federated queries (Consultar dados com consultas federadas) no Guia do .de banco de dados do Amazon Redshift.
MySQL: para criar um esquema externo no Amazon Redshift que se refira a um banco de dados do Amazon RDS para MySQL ou do Amazon Aurora compatível com MySQL. Forneça também as informações de conexão com o banco de dados. Para obter mais informações sobre consultas federadas, consulte Querying data with federated queries (Consultar dados com consultas federadas) no Guia do .de banco de dados do Amazon Redshift.
Selecione Create schema (Criar esquema).
O novo esquema aparece no painel de exibição em árvore.
Criar tabelas
Você pode usar o editor de consultas v2 para criar tabelas no cluster ou grupo de trabalho.
Para criar uma tabela do
É possível criar uma tabela com base em um arquivo de valores separados por vírgulas (CSV) especificado ou define cada coluna da tabela. Para obter mais informações, consulte Design de tabelas e CREATE TABLE no Guia do desenvolvedor de banco de dados do Amazon Redshift.
Selecione Open query in editor (Abrir consulta no editor) para visualizar e editar a instrução CREATE TABLE antes de executar a consulta para criar a tabela.
Escolha
Create (Criar) Table (Tabela).Escolha um esquema.
Escolha um nome da tabela.
Selecione
Add field (Adicionar campo) para adicionar uma coluna. Use um arquivo CSV como modelo para a definição da tabela:
Selecione Load from CSV (Carregar do CSV).
Navegue até o local do arquivo.
Se você usar um arquivo CSV, certifique-se de que a primeira linha do arquivo contém os cabeçalhos da coluna.
Escolha o arquivo selecione Open (Abrir). Confirme que os nomes das colunas e os tipos de dados são os que você deseja.
Para cada coluna, escolha a coluna e as opções que deseja:
Escolha um valor para Encoding (Codificação).
Escolha um Default value (Valor padrão).
Ative Automatically increment (Incrementar automaticamente), se quiser que os valores da coluna sejam incrementados. Em seguida, especifique um valor para o Auto increment seed (Incrementar seed automaticamente) e Auto increment step (Etapa de incremento automático).
Ative Not NULL (Não NULL), se a coluna deve sempre conter um valor.
Digite o valor de Size (Tamanho) para a coluna.
Ative Primary key (Chave primária), se quiser que a coluna seja uma chave primária.
Ative Unique key (Chave exclusiva), se quiser que a coluna seja uma chave exclusiva.
(Opcional) Escolha Table details (Detalhes da tabela) e selecione uma das opções a seguir:
Coluna e estilo da chave de distribuição.
Coluna de chave de classificação e tipo de classificação.
Ative Backup para incluir a tabela em snapshots.
Ative Temporary table (Tabela temporária) para criar a tabela como uma tabela temporária.
Selecione Open query in editor (Abrir consulta no editor) para continuar especificando opções para definir a tabela ou escolha Create table (Criar tabela) para criar a tabela.
Criar funções
É possível usar o editor de consultas v2 para criar funções no cluster ou grupo de trabalho.
Como criar uma função do
Selecione
Create (Criar) e escolha Function (Função).Em Type (Tipo), escolha SQL ou Python.
Escolha um valor para Schema (Esquema).
Insira um valor para Name (Nome) da função.
Insira um valor para Volatility (Volatilidade) da função.
Selecione Parameters (Parâmetros) por tipos de dados na ordem dos parâmetros de entrada.
Em Returns (Retornos), escolha um tipo de dados.
Insira o código do programa SQL ou programa Python da função.
Escolha Criar.
Para obter mais informações sobre funções definidas pelo usuário (UDFs), consulte Criar funções definidas pelo usuário no Guia do desenvolvedor de banco de dados do Amazon Redshift.
Visualizar o histórico de consultas e guias
É possível ver seu histórico de consultas com o editor de consultas v2. Somente as consultas que você executou usando o editor de consultas v2 aparecem no histórico de consultas. Tanto as consultas executadas usando uma guia Editor ou uma guia Notebook (Caderno) são exibidas. É possível filtrar a lista exibida por um período, como This week, em que uma semana é definida como de segunda a domingo. A lista de consultas retorna 25 linhas de consultas por vez que correspondem ao seu filtro. Selecione Load more (Carregar mais) para ver o próximo conjunto. Selecione uma consulta. No menu Actions (Ações), As ações disponíveis dependem de a consulta escolhida ter sido salva. É possível selecionar as seguintes operações:
View query details (Visualizar detalhes da consulta): exibe uma página de detalhes da consulta com mais informações sobre a consulta executada.
Open query in a new tab (Abrir consulta em uma nova guia): abre uma nova guia do editor e a prepara com a consulta escolhida. Se ainda estiver conectado, o cluster ou o grupo de trabalho e o banco de dados serão selecionados automaticamente. Para executar a consulta, primeiro confirme se o cluster ou grupo de trabalho e o banco de dados corretos foram escolhidos.
Open source tab (Aba de código aberto): se ainda estiver aberta, acessa a guia do editor ou do caderno que continha a consulta quando ela foi executada. O conteúdo do editor ou do caderno pode ter mudado após a execução da consulta.
Open saved query (Abrir consulta salva): acessa a guia do editor ou do caderno e abre a consulta.
Também é possível visualizar o histórico das consultas executadas em uma guia Editor ou o histórico das consultas executadas em uma guia Notebook (Caderno). Para ver um histórico de consultas em uma guia, selecione Tab history (Histórico da guia). No histórico da guia, é possível executar as seguintes operações:
Copy query (Copiar consulta): copia o conteúdo SQL da versão da consulta para a área de transferência.
Open query in a new tab (Abrir consulta em uma nova guia): abre uma nova guia do editor e a prepara com a consulta escolhida. Para executar a consulta, você deve escolher o cluster ou o grupo de trabalho e o banco de dados.
View query details (Visualizar detalhes da consulta): exibe uma página de detalhes da consulta com mais informações sobre a consulta executada.
Considerações ao trabalhar com o editor de consultas v2
Considere o seguinte ao trabalhar com o editor de consultas v2:
O tamanho máximo do resultado da consulta é 5 MB ou 100 mil linhas, o que for menor.
É possível salvar uma consulta de até 300 mil caracteres.
É possível salvar uma consulta de até 30 mil caracteres.
Por padrão, o editor de consultas v2 confirma automaticamente cada comando SQL individual executado. Quando uma instrução BEGIN é fornecida, as instruções no bloco BEGIN-COMMIT ou BEGIN-ROLLBACK são executadas como uma única transação. Para obter mais informações sobre transações, consulte BEGIN no Guia do desenvolvedor de banco de dados do Amazon Redshift.
O número máximo de avisos que o editor de consultas v2 exibe ao executar uma instrução SQL é
10. Por exemplo, quando um procedimento armazenado é executado, não mais de dez instruções RAISE são exibidas.O editor de consultas v2 não é compatível com um
RoleSessionNamedo IAM que contenha vírgula (,). Você pode ver um erro semelhante ao seguinte:Mensagem de erro: “‘AROA123456789EXAMPLE:mytext,yourtext’ is not a valid value for TagValue - it contains illegal characters”. Esse problema surge quando você define umRoleSessionNamedo IAM que inclui uma vírgula e usa o editor de consultas v2 com esse perfil do IAM.Para obter mais informações sobre um
RoleSessionNamedo IAM, consulte Atributo SAML RoleSessionName no Guia do usuário do IAM.
Alterar as configurações da conta
Um usuário com as permissões corretas do IAM pode visualizar e alterar Account settings (Configurações da conta) para outros usuários na mesma Conta da AWS. Esse administrador pode exibir ou definir o seguinte:
O máximo de conexões simultâneas de banco de dados por usuário na conta. Isso inclui conexões para Isolated sessions (Sessão isoladas). Quando você altera esse valor, pode levar 10 minutos para que a mudança tenha efeito.
Permita que os usuários da conta exportem um conjunto inteiro de resultados de um comando SQL para um arquivo.
Carregue e exiba bancos de dados de exemplo com algumas consultas salvas correspondentes.
Especifique um caminho do Amazon S3 usado pelos usuários da conta para carregar dados de um arquivo local.
Visualize o ARN da chave do KMS a ser usada para criptografar os recursos do editor de consultas v2.
