As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Crie e use um fluxo do Data Wrangler
Use um fluxo do Amazon SageMaker Data Wrangler, ou um fluxo de dados, para criar e modificar um pipeline de preparação de dados. O fluxo de dados conecta os conjuntos de dados, as transformações e as análises, ou etapas, que você cria e pode ser usado para definir seu pipeline.
Instâncias
Quando você cria um fluxo do Data Wrangler no Amazon SageMaker Studio Classic, o Data Wrangler usa uma EC2 instância da Amazon para executar as análises e transformações no seu fluxo. Por padrão, o Data Wrangler usa a instância m5.4xlarge. As instâncias m5 são instâncias de uso geral que fornecem um equilíbrio entre computação e memória. Você pode usar instâncias m5 para uma variedade de workloads computacionais.
O Data Wrangler também oferece a opção de usar instâncias r5. As instâncias r5 são projetadas para oferecer desempenho rápido que processa grandes conjuntos de dados na memória.
Recomendamos que você escolha uma instância que seja melhor otimizada para suas workloads. Por exemplo, o r5.8xlarge pode ter um preço mais alto do que o m5.4xlarge, mas o r5.8xlarge pode ser melhor otimizado para suas workloads. Com instâncias mais otimizadas, você pode executar seus fluxos de dados em menos tempo e a um custo menor.
A tabela a seguir mostra as instâncias que você pode usar para executar seu fluxo do Data Wrangler.
| Instâncias padrão | vCPU | Memória |
|---|---|---|
| ml.m5.4xlarge | 16 | 64 GiB |
| ml.m5.8xlarge | 32 | 128 GiB |
| ml.m5.16xlarge | 64 |
256 GiB |
| ml.m5.24xlarge | 96 | 384 GiB |
| r5.4xlarge | 16 | 128 GiB |
| r5.8xlarge | 32 | 256 GiB |
| r5.24xlarge | 96 | 768 GiB |
Para obter mais informações sobre instâncias r5, consulte Amazon EC2 R5
Cada fluxo do Data Wrangler tem uma EC2 instância da Amazon associada a ele. Você pode ter vários fluxos associados a uma única instância.
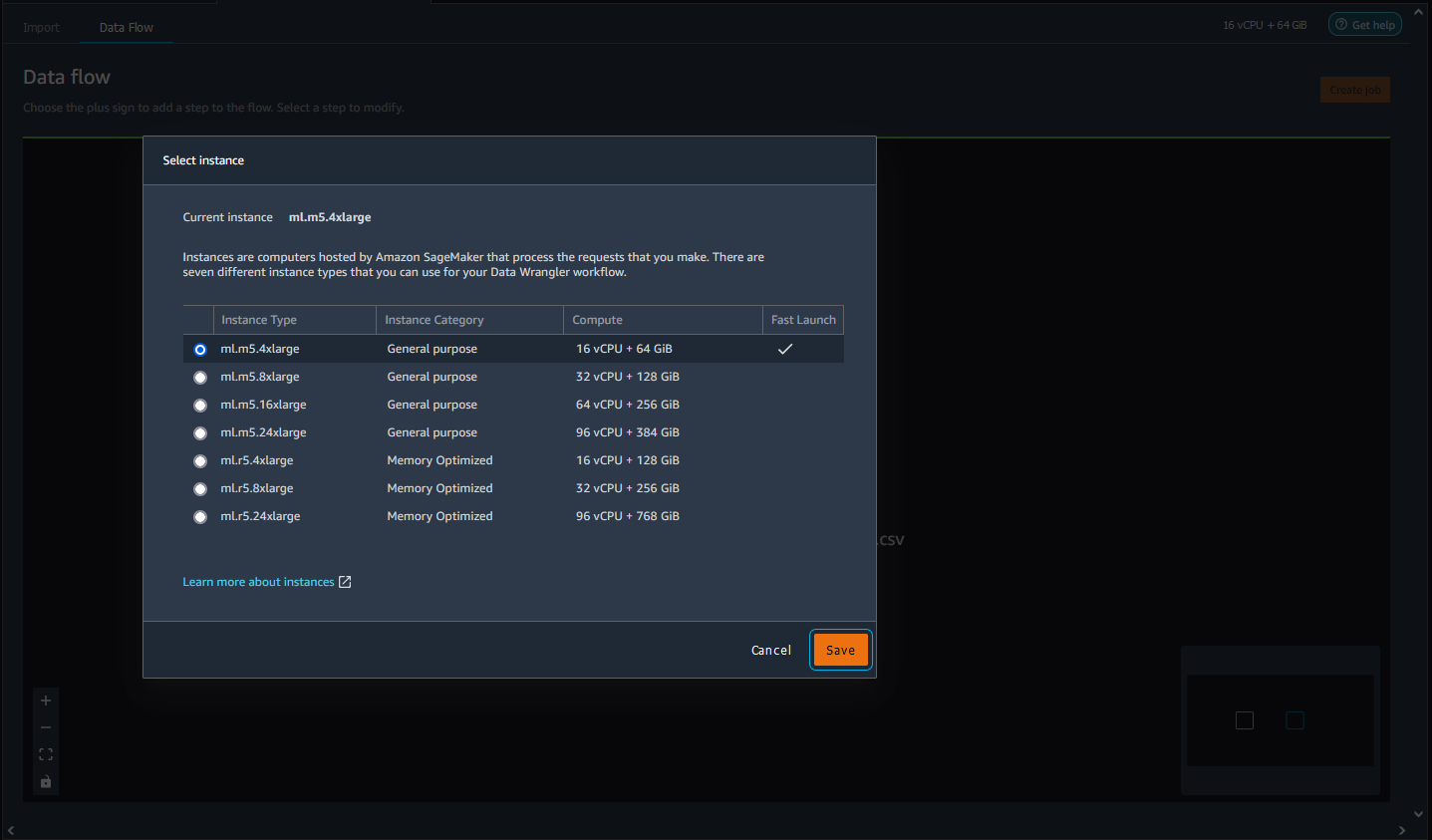
Para cada arquivo de fluxo, você pode alternar facilmente o tipo de instância. Se você alternar o tipo de instância, a instância que você usou para executar o fluxo continuará sendo executada.
Para mudar o tipo de instância do seu fluxo, faça o seguinte:
-
Escolha o ícone Terminais e kernels em execução (
 ).
). -
Navegue até a instância que você está usando e escolha-a.
-
Escolha o tipo de instância que você deseja excluir.
-
Escolha Salvar.
Você é cobrado por todas as instâncias em execução. Para evitar cobranças adicionais, encerre as instâncias que você não está usando manualmente. Para encerrar uma instância em execução, use o procedimento a seguir.
Para encerrar uma instância em execução.
-
Escolha o ícone de instância. A imagem a seguir mostra onde selecionar o ícone RUNNING INSTANCES.
-
Escolha Encerrar ao lado da instância que você deseja encerrar.
Se você encerrar uma instância usada para executar um fluxo, não poderá acessar temporariamente o fluxo. Se você receber um erro ao tentar abrir o fluxo executando uma instância que você desligou anteriormente, aguarde 5 minutos e tente abri-lo novamente.
Quando você exporta seu fluxo de dados para um local como o Amazon Simple Storage Service ou o Amazon SageMaker Feature Store, o Data Wrangler executa um trabalho de SageMaker processamento da Amazon. Você pode usar uma das instâncias a seguir para o trabalho de processamento. Para obter mais informações na exportação dos seus dados, consulte Exportar.
| Instâncias padrão | vCPU | Memória |
|---|---|---|
| ml.m5.4xlarge | 16 | 64 GiB |
| ml.m5.12xlarge | 48 |
192 GiB |
| ml.m5.24xlarge | 96 | 384 GiB |
Para obter mais informações sobre o custo por hora do uso dos tipos de instância disponíveis, consulte SageMaker Preços
A interface de usuário do fluxo de dados
Quando você importa um conjunto de dados, o conjunto de dados original aparece no fluxo de dados e é chamado de Fonte. Se você ativou a amostragem ao importar seus dados, esse conjunto de dados será denominado Fonte - amostrado. O Data Wrangler infere automaticamente os tipos de cada coluna em seu conjunto de dados e cria um novo quadro de dados chamado Tipos de dados. Você pode selecionar esse quadro para atualizar os tipos de dados inferidos. Você verá resultados semelhantes aos mostrados na imagem a seguir após o upload de um conjunto de dados:
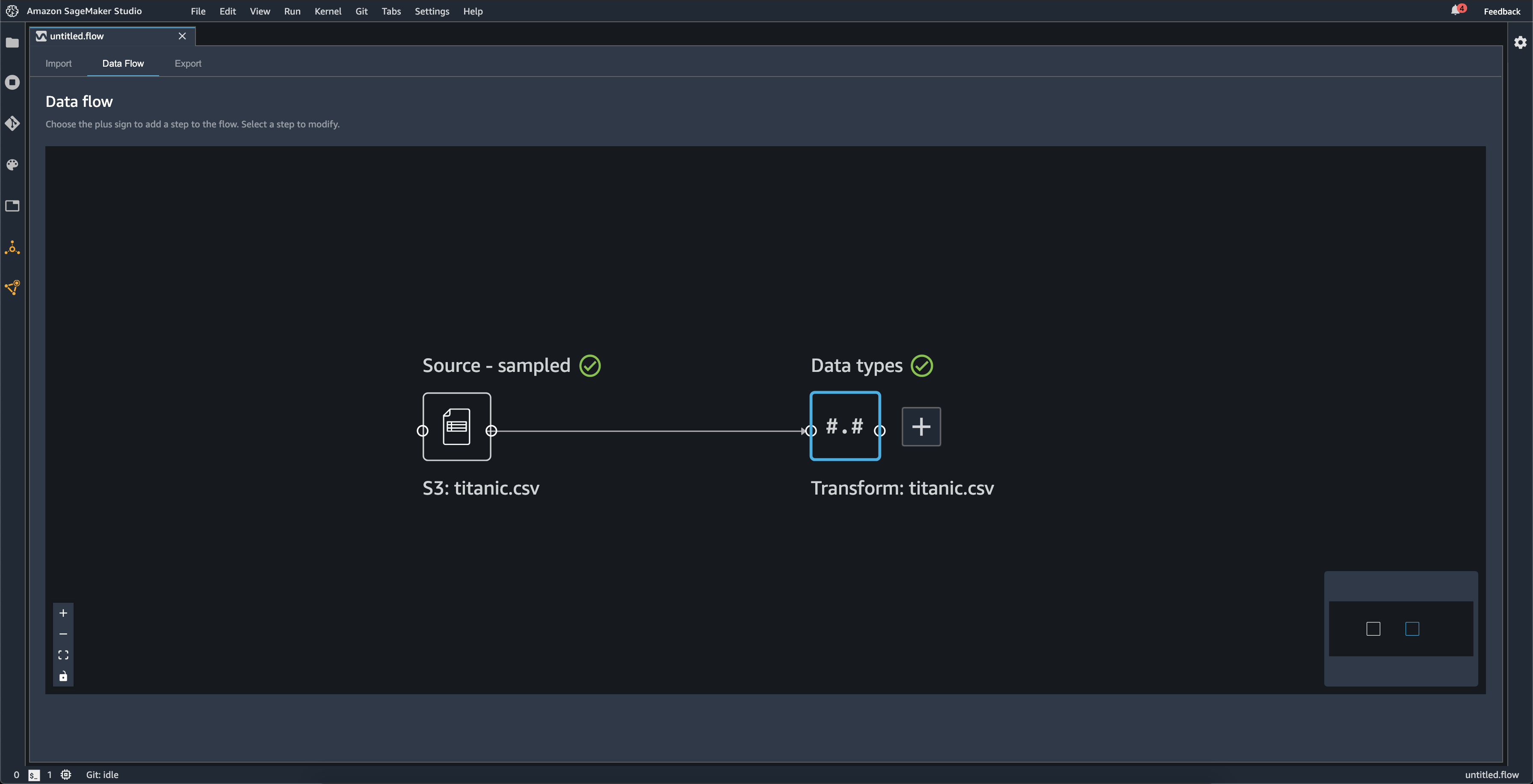
Cada vez que você adiciona uma etapa de transformação, você cria um novo dataframe. Quando várias etapas de transformação (exceto Unir ou Concatenar) são adicionadas ao mesmo conjunto de dados, elas são empilhadas.
Unir e Concatenar criam etapas autônomas que contêm o novo conjunto de dados unido ou concatenado.
O diagrama a seguir mostra um fluxo de dados com uma junção entre dois conjuntos de dados, bem como duas pilhas de etapas. A primeira pilha (Etapas (2) adiciona duas transformações ao tipo inferido no conjunto de dados tipos de dados. A pilha downstream, ou a pilha à direita, adiciona transformações ao conjunto de dados resultantes de uma junção chamada demo-join.
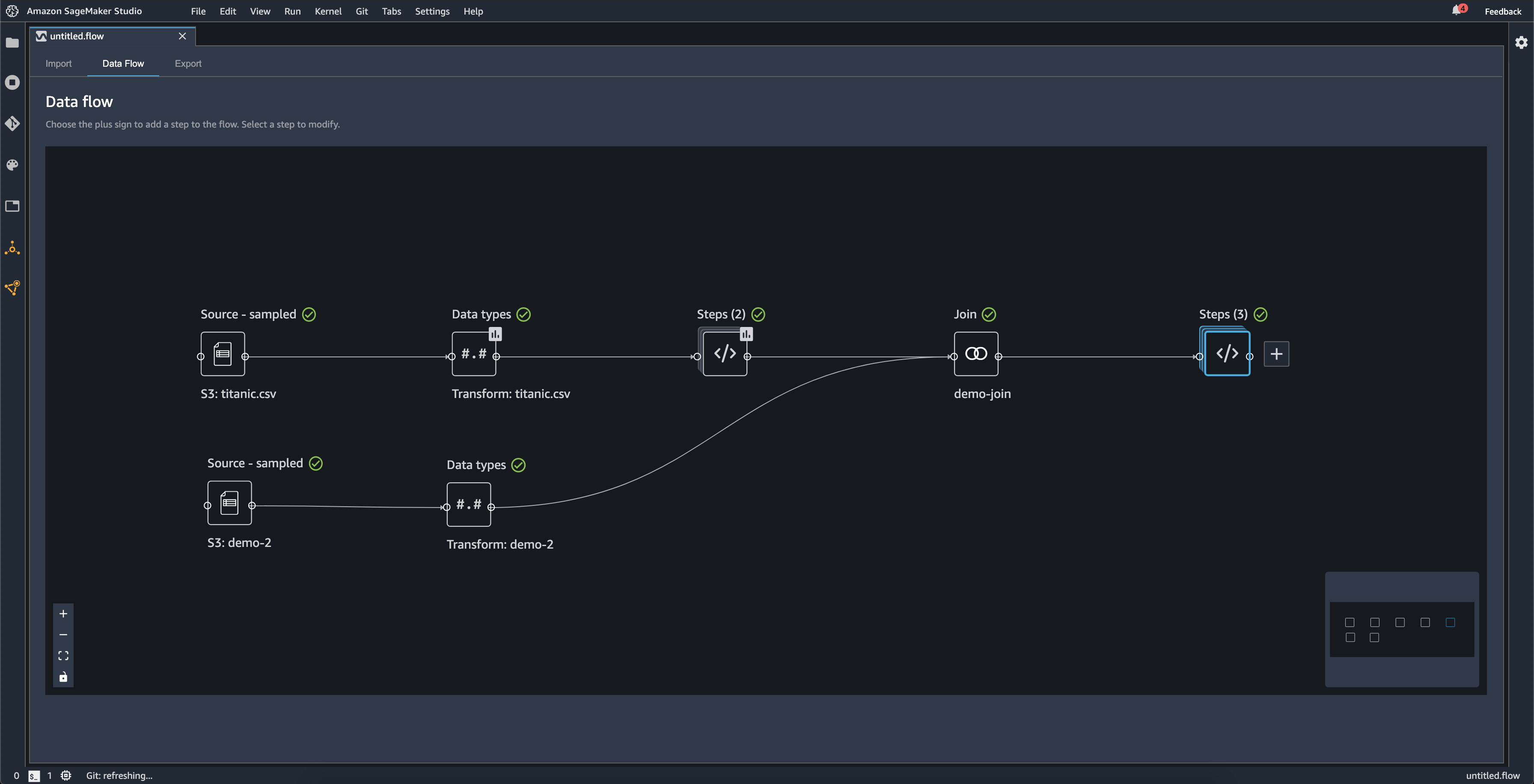
A pequena caixa cinza no canto inferior direito do fluxo de dados fornece uma visão geral do número de pilhas e etapas no fluxo e do layout do fluxo. A caixa mais clara dentro da caixa cinza indica as etapas que estão dentro da visualização da interface do usuário. Você pode usar essa caixa para ver seções do seu fluxo de dados que estão fora da visualização da interface do usuário. Use o ícone de ajuste da tela (
 ) para ajustar todas as etapas e conjuntos de dados à sua visualização da interface do usuário.
) para ajustar todas as etapas e conjuntos de dados à sua visualização da interface do usuário.
A barra de navegação inferior esquerda inclui ícones que você pode usar para ampliar (
 ) e reduzir (
) e reduzir (
 ) o fluxo de dados, além de redimensionar o fluxo de dados para caber na tela (
). Use o ícone de cadeado (
) o fluxo de dados, além de redimensionar o fluxo de dados para caber na tela (
). Use o ícone de cadeado (
 ) para bloquear e desbloquear a localização de cada etapa na tela.
) para bloquear e desbloquear a localização de cada etapa na tela.
Adicione uma etapa ao seu fluxo de dados
Selecione + ao lado de qualquer conjunto de dados ou etapa adicionada anteriormente e, em seguida, selecione uma das seguintes opções:
-
Editar tipos de dados (somente para uma etapa de tipos de dados): se você não adicionou nenhuma transformação a uma etapa de tipos de dados, você pode selecionar Editar tipos de dados para atualizar os tipos de dados que o Data Wrangler inferiu ao importar seu conjunto de dados.
-
Adicionar transformação: adiciona uma nova etapa de transformação. Consulte Transformar dados para saber mais sobre as transformações de dados que você pode adicionar.
-
Adicionar análise: adiciona uma análise. Você pode usar essa opção para analisar seus dados em qualquer ponto do fluxo de dados. Quando você adiciona uma ou mais análises a uma etapa, um ícone de análise (
 ) aparece nessa etapa. Consulte Analisar e visualizar para saber mais sobre as análises que você pode adicionar.
) aparece nessa etapa. Consulte Analisar e visualizar para saber mais sobre as análises que você pode adicionar. -
Unir: une dois conjuntos de dados e adiciona o conjunto de dados resultante ao fluxo de dados. Para saber mais, consulte Unir conjuntos de dados.
-
Concatenar: concatena dois conjuntos de dados e adiciona o conjunto de dados resultante ao fluxo de dados. Para saber mais, consulte Concatenar conjuntos de dados.
Excluir uma etapa do seu fluxo de dados
Para excluir uma etapa, selecione a etapa e depois Excluir. Se o nó for de uma única entrada, você exclui somente a etapa selecionada. Quando se exclui uma etapa com uma única entrada não se exclui as etapas que a seguem. Se você excluir uma etapa de um nó de origem, junção ou concatenação, todas as etapas subsequentes também serão excluídas.
Para excluir uma etapa de uma pilha de etapas, selecione a pilha e, em seguida, selecione a etapa que deseja excluir.
Você pode usar um dos procedimentos a seguir para excluir uma etapa sem excluir as etapas posteriores.
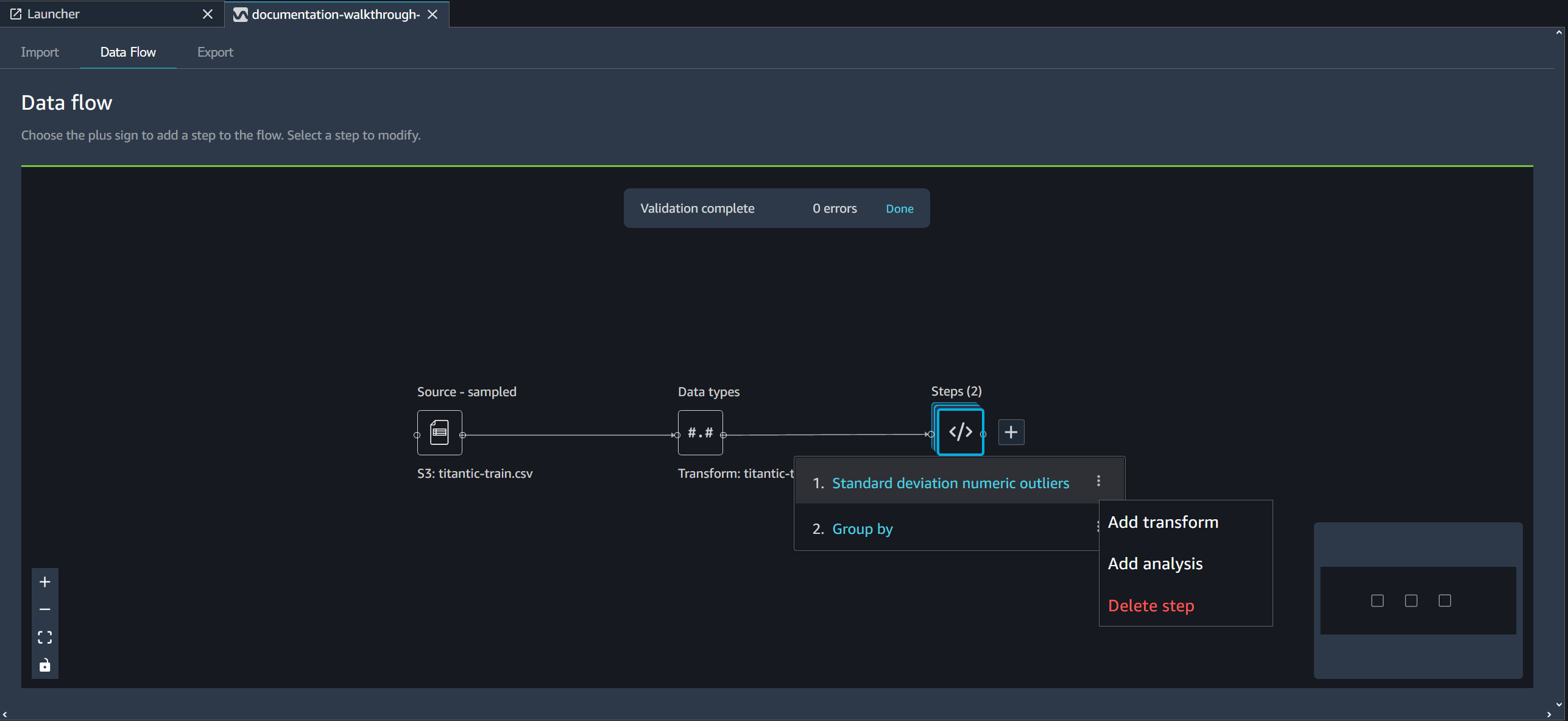
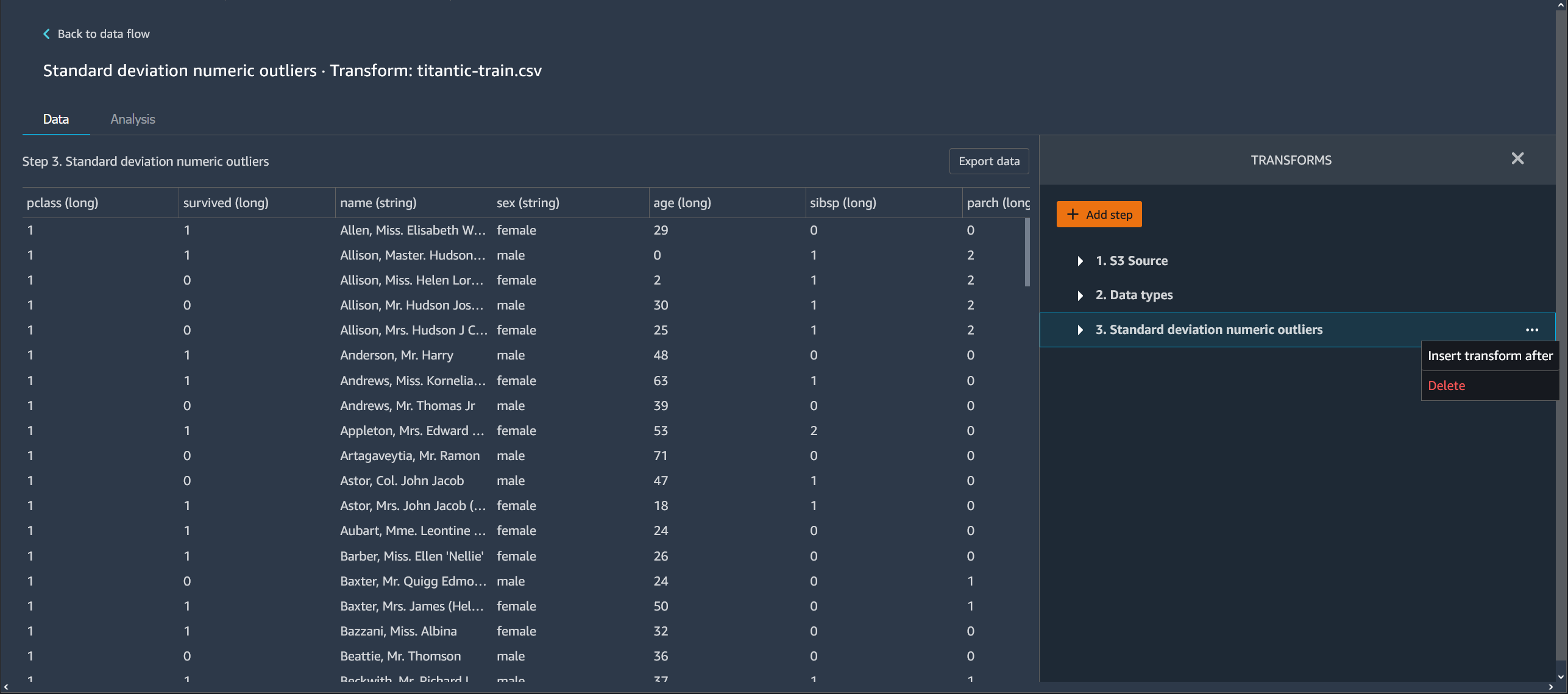
Exclua uma etapa no seu fluxo do Data Wrangler.
Você pode editar cada etapa adicionada ao fluxo do Data Wrangler. Ao editar as etapas, é possível alterar as transformações ou os tipos de dados das colunas. Você pode editar as etapas para fazer alterações com as quais pode realizar análises melhores.
Há várias maneiras de editar uma etapa. Alguns exemplos incluem a alteração do método de imputação ou a alteração do limite para considerar um valor como algo atípico.
Utilize o seguinte procedimento para editar uma etapa:
Para editar uma etapa, faça o seguinte:
-
Escolha uma etapa no fluxo do Data Wrangler para abrir a exibição da tabela.
-
Escolha uma etapa no fluxo de dados.
-
Edite a etapa.
A imagem a seguir mostra um exemplo de edição de uma etapa.
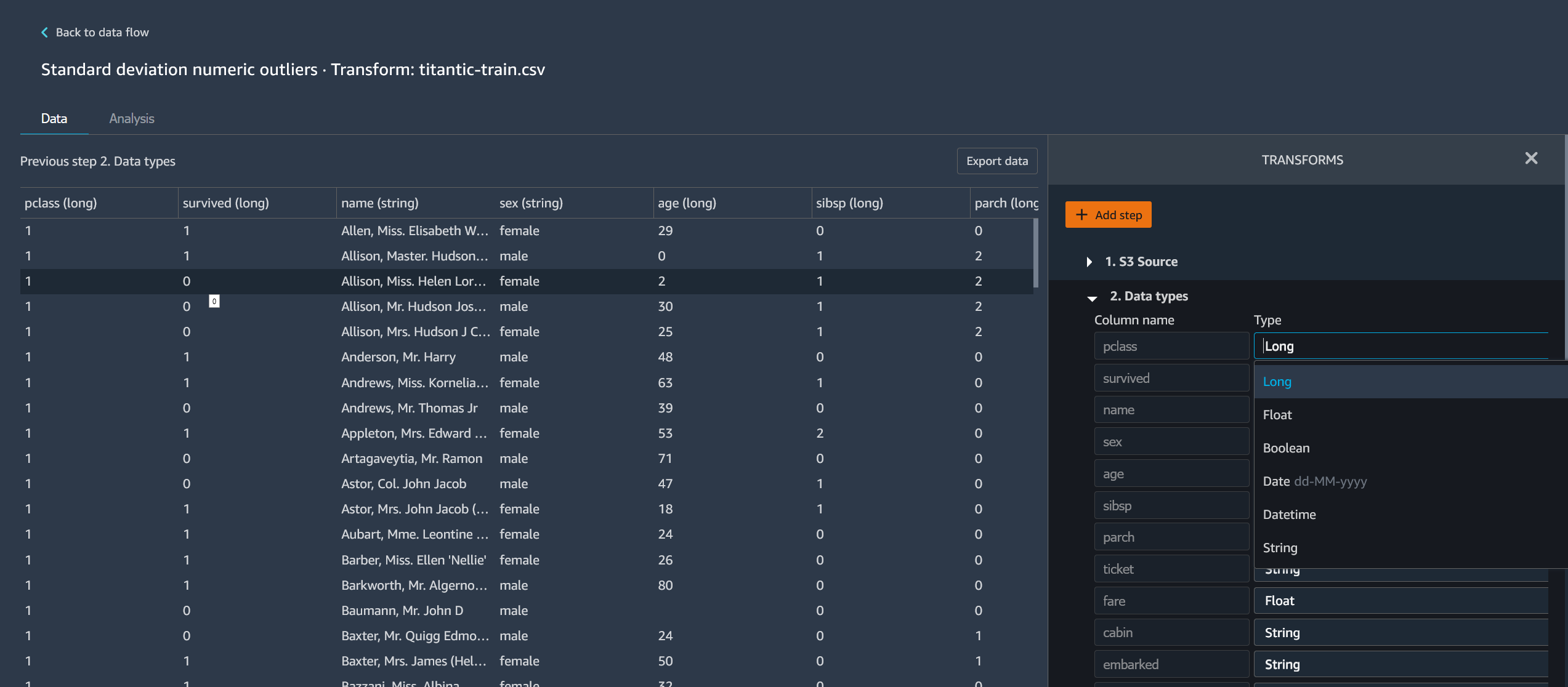
nota
Você pode usar os espaços compartilhados em seu domínio Amazon SageMaker AI para trabalhar de forma colaborativa em seus fluxos do Data Wrangler. Em um espaço compartilhado, você e seus colaboradores podem editar um arquivo de fluxo em tempo real. No entanto, nem você nem seus colaboradores podem ver as mudanças em tempo real. Quando alguém faz uma alteração no fluxo do Data Wrangler, deve salvá-la imediatamente. Quando alguém salva um arquivo, um colaborador não poderá vê-lo, a menos que feche o arquivo e o reabra. Todas as alterações que não são salvas por uma pessoa são substituídas pela pessoa que salvou as alterações.
