As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Evacuação controlada por ambiente de gerenciamento
O primeiro padrão usa operações de plano de dados para evitar a execução de trabalhos em uma zona de disponibilidade afetada para mitigar o impacto de um evento. No entanto, você pode ter uma arquitetura que não usa balanceadores de carga ou em que a configuração de uma verificação de integridade por host não seja viável. Ou, talvez você queira evitar que uma nova capacidade seja implantada na zona de disponibilidade afetada por meio do Auto Scaling ou do agendamento normal de trabalho.
Para lidar com as duas situações, são necessárias ações do ambiente de gerenciamento para atualizar a configuração do recurso. O padrão funcionará para qualquer serviço cuja configuração de rede possa ser atualizada, por exemplo, EC2 Auto Scaling, Amazon ECS, Lambda e muito mais. É necessário escrever código para cada serviço, mas a lógica de negócios segue um padrão básico. O código deve ser executado localmente por um operador que responde ao evento para minimizar as dependências necessárias. O fluxo básico da lógica do script é mostrado na figura a seguir.
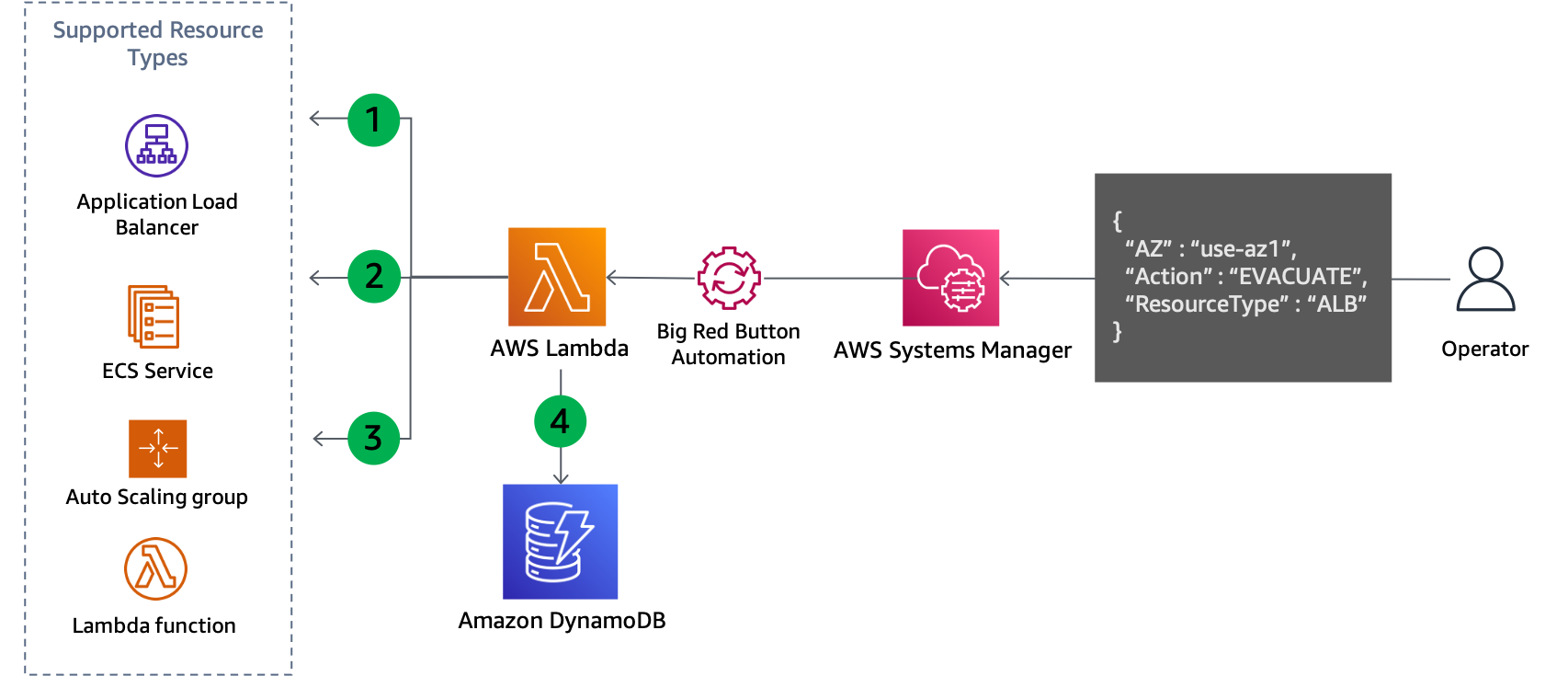
Atualização do ambiente de gerenciamento para evacuar uma zona de disponibilidade
-
O script lista todos os recursos do tipo especificado, como grupo Auto Scaling, serviço ECS ou função do Lambda e recupera as sub-redes a partir das informações do recurso. Os recursos suportados dependem do que o script foi configurado para dar suporte.
-
Ele determina quais sub-redes devem ser removidas comparando o nome da zona de disponibilidade de cada sub-rede com o ID da zona de disponibilidade mapeada, fornecida como parâmetro de entrada.
-
A configuração de rede do recurso é atualizada para remover as sub-redes identificadas.
-
Os detalhes da atualização são registrados em uma tabela do DynamoDB. O ID da zona de disponibilidade é armazenado como chave de partição e o ARN ou nome do recurso é armazenado como chave de classificação. As sub-redes que foram removidas são armazenadas como uma matriz de strings. Finalmente, o tipo de recurso também é armazenado e usado como uma chave de hash para um Índice Secundário Global (GSI).
Como a etapa quatro registra as atualizações feitas, essa abordagem também pode ser facilmente reversível quando você estiver pronto para a recuperação, conforme mostrado na figura a seguir.
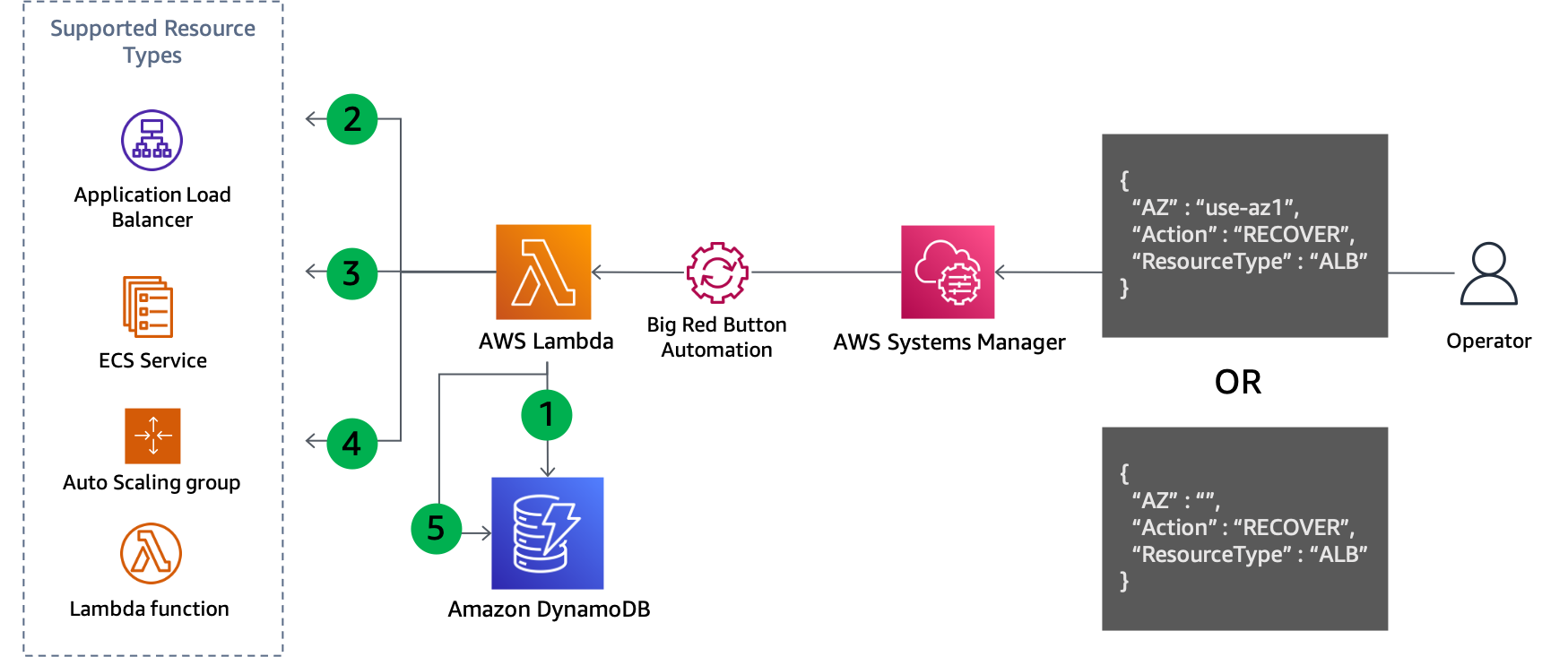
Atualização do ambiente de gerenciamento para se recuperar da evacuação da zona de disponibilidade
Etapas de recuperação:
-
Consulte o GSI para remover as sub-redes de cada recurso do tipo especificado na zona de disponibilidade especificada (ou todas as zonas de disponibilidade, se não nenhuma for especificada).
-
Descreva cada recurso encontrado na consulta do DynamoDB para obter sua configuração de rede atual.
-
Combine as sub-redes da configuração de rede atual com aquelas recuperadas da consulta do DynamoDB.
-
Atualize a configuração de rede do recurso com o novo conjunto de sub-redes.
-
Remova o registro da tabela do DynamoDB após a atualização ser concluída com sucesso.
Esse padrão generalizado impede o trabalho de roteamento para a zona de disponibilidade afetada e impede que uma nova capacidade seja implantada lá. A seguir estão exemplos de como isso é feito para diferentes serviços.
-
Lambda — atualize a configuração de VPC da função para remover as sub-redes na zona de disponibilidade especificada.
-
Grupo de Auto Scaling — remova as sub-redes da configuração do ASG que substituirão essa capacidade nas demais zonas de disponibilidade.
-
Amazon ECS — atualize a configuração VPC do serviço ECS para remover as sub-redes.
-
Amazon EKS — aplique taints
nos nós na zona de disponibilidade afetada para remover pods existentes e evitar que outros pods sejam agendados lá.
Cada serviço reagirá de forma diferente à atualização da configuração. Por exemplo, o Amazon ECS seguirá a configuração de implantação do serviço após uma atualização e acionará uma implantação contínua ou uma implantação azul/verde de novas tarefas.
Essas atualizações podem transferir o trabalho para as zonas de disponibilidade íntegras muito rapidamente para alguns workloads. Embora esteja configurado para ser estaticamente estável a falhas (com capacidade pré-provisionada suficiente nas zonas de disponibilidade restantes para lidar com o trabalho da zona de disponibilidade afetada), você também pode querer eliminar gradualmente a capacidade da zona de disponibilidade afetada.
Se você planeja atualizar a configuração de rede do grupo de Auto Scaling que é um grupo-alvo para um balanceador de carga com balanceamento de carga entre zonas desativado, siga esta orientação.
O Auto Scaling reage a essa mudança usando sua lógica de rebalanceamento da zona de disponibilidade. Ele iniciará instâncias nas outras zonas de disponibilidade para atender à capacidade desejada e encerrará instâncias na zona de disponibilidade que você removeu. No entanto, o balanceador de carga continuará dividindo o tráfego uniformemente em cada zona de disponibilidade, incluindo a que você removeu do ASG, enquanto as instâncias estão sendo encerradas. Isso pode reduzir a capacidade restante nessa zona de disponibilidade até que todas as instâncias sejam encerradas com sucesso. Esse é o mesmo problema descrito em Independência da zona de disponibilidade em relação ao desequilíbrio da zona de disponibilidade quando o balanceamento de carga entre zonas está desativado. Para evitar que isso ocorra, você pode:
-
Sempre realizar primeiro a evacuação da zona de disponibilidade para que o tráfego seja dividido apenas entre as demais zonas de disponibilidade
-
Especificar uma contagem mínima de alvos íntegros com failover de DNS para corresponder à contagem mínima necessária para essa zona de disponibilidade.
Isso ajudará a garantir que o tráfego não seja enviado para a zona de disponibilidade que você removeu depois que as instâncias começarem a ser encerradas.
