As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Evacuação controlada por plano de dados
Há várias soluções que você pode implementar para realizar a evacuação de uma zona de disponibilidade usando ações somente do plano de dados. Esta seção descreverá três delas e os casos de uso em que talvez você opte por escolher um em vez dos outros.
Ao usar qualquer uma dessas soluções, você precisará garantir que tenha capacidade suficiente nas zonas de disponibilidade restantes para lidar com a carga da zona de disponibilidade da qual você está saindo. A maneira mais resiliente de fazer isso é ter a capacidade necessária pré-provisionada em cada zona de disponibilidade. Se estiver usando três zonas de disponibilidade, você teria 50% da capacidade necessária para lidar com o pico de carga implantada em cada uma, de modo que a perda de uma única zona de disponibilidade ainda continuaria com 100% da capacidade necessária sem precisar depender de um ambiente de gerenciamento para provisionar mais.
Além disso, se você estiver usando o EC2 Auto Scaling, certifique-se de que seu grupo do Auto Scaling (ASG) não reduza a escala horizontalmente durante a mudança, de forma que, quando a mudança terminar, você ainda tenha capacidade suficiente no grupo para lidar com o tráfego de clientes. Você pode fazer isso garantindo que a capacidade mínima desejada do seu ASG possa lidar com a carga atual de clientes. Você também pode ajudar a garantir que seu ASG não reduza a escala horizontalmente de maneira inadvertida usando médias nas métricas, em vez de métricas percentuais atípicas, como P90 ou P99.
Durante uma mudança, os recursos que não atendem mais ao tráfego devem ter uma utilização muito baixa, mas os outros recursos aumentarão a utilização com o novo tráfego, mantendo a média bastante consistente, o que impediria uma ação para reduzir a escala horizontalmente. Por fim, você também pode usar as configurações de integridade do grupo-alvo para ALB e NLB para especificar o failover de DNS com uma porcentagem ou uma contagem de hosts íntegros. Isso evita que o tráfego seja roteado para uma zona de disponibilidade que não tenha hosts íntegros suficientes.
Mudança de zona no Application Recovery Controller (ARC) do Route 53
A primeira solução para evacuação da zona de disponibilidade usa mudança de zona no ARC do Route 53. Essa solução pode ser usada para workloads de solicitação/resposta que usam um NLB ou ALB como ponto de entrada para o tráfego de clientes.
Ao detectar que uma zona de disponibilidade está comprometida, você pode iniciar uma mudança de zona com o ARC do Route 53. Depois que essa operação for concluída e as respostas de DNS em cache existentes expirarem, todas as novas solicitações serão encaminhadas somente para recursos nas zonas de disponibilidade restantes. A figura a seguir mostra como funciona a mudança de zona. Na figura a seguir, temos um registro de alias www.example.com do Route 53 que aponta para my-example-nlb-4e2d1f8bb2751e6a.elb.us-east-1.amazonaws.com. A mudança de zona é executada para a zona de disponibilidade 3.
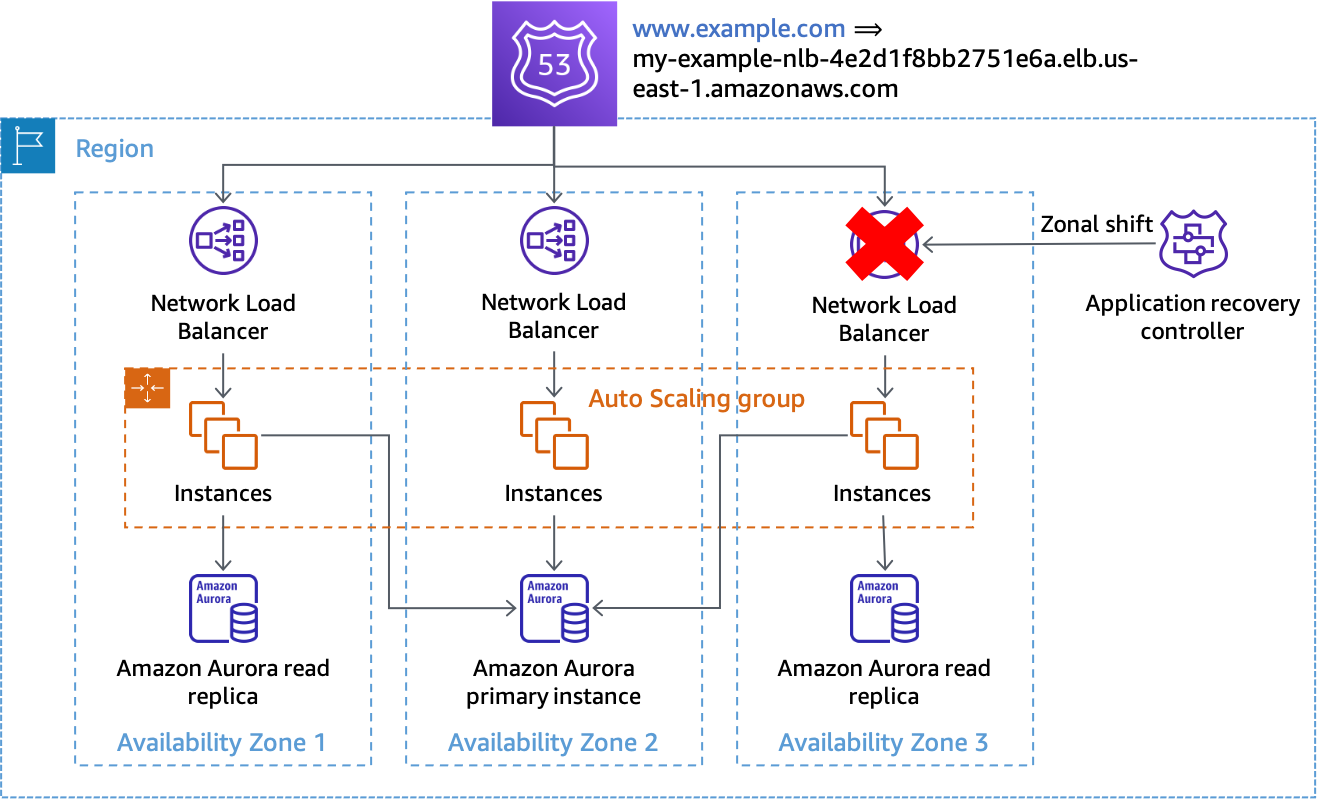
Mudança de zona
No exemplo, se a instância primária do banco de dados não estiver na zona de disponibilidade 3, realizar a mudança de zona é a única ação necessária para alcançar o primeiro resultado de evacuação, impedindo que o trabalho seja processado na zona de disponibilidade afetada. Se o nó primário estivesse na zona de disponibilidade 3, você poderia realizar um failover iniciado manualmente (que depende do ambiente de gerenciamento do Amazon RDS) em coordenação com a mudança de zona, caso o Amazon RDS ainda não tenha feito o failover automático. Isso valerá para todas as soluções controladas pelo plano de dados nesta seção.
Você deve iniciar a mudança de zona usando os comandos da CLI ou a API para minimizar as dependências necessárias para iniciar a evacuação. Quanto mais simples for o processo de evacuação, mais confiável ele será. Os comandos específicos podem ser armazenados em um runbook local que os engenheiros de plantão podem acessar facilmente. A mudança de zona é a solução preferida e mais simples para evacuar uma zona de disponibilidade.
Route 53 ARC
A segunda solução usa os recursos do ARC do Route 53 para especificar manualmente a integridade de registros DNS específicos. Essa solução tem a vantagem de usar o plano de dados de cluster ARC altamente disponível do Route 53, tornando-o resiliente à deficiência de até dois Regiões da AWS diferentes. Ele tem a desvantagem de um custo adicional e requer alguma configuração adicional de registros DNS. Para implementar esse padrão, você precisa criar registros de alias para os nomes DNS específicos da zona de disponibilidade fornecidos pelo balanceador de carga (ALB ou NLB). Isto é mostrado na tabela a seguir.
Tabela 3: Registros de alias do Route 53 configurados para os nomes DNS de zona do balanceador de carga
|
Política de roteamento: ponderada Nome: Tipo: Value (Valor): Peso: Avaliar status do destino: true |
Política de roteamento: ponderada Nome: Tipo: Valor: Peso: Avaliar status do destino: |
Política de roteamento: ponderada Nome: Tipo: Valor: Peso: Avaliar status do destino: |
Para cada um dos registros DNS, configure uma verificação de integridade do Route 53 associada a um controle de roteamento do ARC do Route 53. Quando quiser iniciar uma evacuação da zona de disponibilidade, defina o estado do controle de roteamento como Off. AWS recomenda fazer isso usando a CLI ou a API para minimizar as dependências necessárias para iniciar a evacuação da zona de disponibilidade. Como prática recomendada, você deve manter uma cópia local dos endpoints do cluster ARC do Route 53 para não precisar recuperá-los do ambiente de gerenciamento do ARC quando precisar realizar uma evacuação.
Para minimizar o custo ao usar essa abordagem, você pode criar um único cluster ARC do Route 53 e verificações de integridade em um único Conta da AWS e compartilhar as verificações de integridade com outras Contas da AWSuse1-az1) em vez do nome da zona de disponibilidade (por exemplo, us-east-1a) para os controles de roteamento. Como AWS mapeia a zona de disponibilidade física aleatoriamente com os nomes das zonas de disponibilidade de cada Conta da AWS, o uso do AZ-ID fornece uma maneira consistente de fazer referência aos mesmos locais físicos. Quando você inicia uma evacuação da zona de disponibilidade, digamos, por use1-az2, os conjuntos de registros do Route 53 em cada Conta da AWS devem garantir que usem o mapeamento AZ-ID para configurar a verificação de integridade correta para cada registro de NLB.
Por exemplo, digamos que temos uma verificação de integridade do Route 53 associada a um controle de roteamento ARC do Route 53 para use1-az2, com um ID de 0385ed2d-d65c-4f63-a19b-2412a31ef431. Se uma Conta da AWS diferente que quisesse usar isso para fazer a verificação de integridade, us-east-1c estaria mapeado para use1-az2, você precisaria usar a verificação de integridade use1-az2 para o registro us-east-1c.load-balancer-name.elb.us-east-1.amazonaws.com. Você usaria o ID da verificação de integridade 0385ed2d-d65c-4f63-a19b-2412a31ef431 com esse conjunto de registros de recursos.
Uso de um endpoint HTTP autogerenciado
Você também pode implementar essa solução gerenciando seu próprio endpoint HTTP que indica o status de uma zona de disponibilidade específica. Isso permite que você especifique manualmente quando uma zona de disponibilidade não está íntegra com base na resposta do endpoint HTTP. Essa solução custa menos do que usar o ARC do Route 53, mas é mais cara do que a mudança de zona e requer o gerenciamento de infraestrutura adicional. Ela tem a vantagem de ser muito mais flexível para diferentes cenários.
O padrão pode ser usado com arquiteturas NLB ou ALB e com verificações de integridade do Route 53. Também pode ser usada em arquiteturas sem balanceamento de carga, como sistemas de descoberta de serviços ou processamento de filas, nos quais os nós de trabalho realizam suas próprias verificações de integridade. Nesses cenários, os hosts podem usar um thread em segundo plano em que periodicamente fazem uma solicitação ao endpoint HTTP com seu AZ-ID (consulte Apêndice A — Obtendo o ID da zona de disponibilidade para obter detalhes sobre como encontrar isso) e receber de volta uma resposta sobre a integridade da zona de disponibilidade.
Se a zona de disponibilidade tiver sido declarada não íntegra, eles terão várias opções sobre como responder. Os hosts podem optar por falhar em uma verificação de integridade externa de fontes como ELB, Route 53 ou em verificações de integridade personalizadas em arquiteturas de descoberta de serviços de forma que pareçam não íntegros para os serviços. Também podem responder imediatamente com um erro caso recebam uma solicitação, permitindo que o cliente recue e tente novamente. Em arquiteturas orientadas por eventos, os nós podem falhar intencionalmente no processamento do trabalho, como retornar intencionalmente uma mensagem SQS para a fila. Em arquiteturas de roteadores de trabalho em que um cronograma de serviço central funciona em hosts específicos, você também pode usar esse padrão. O roteador pode verificar o status de uma zona de disponibilidade antes de selecionar um operador, endpoint ou célula. Nas arquiteturas de descoberta de serviços que usam AWS Cloud Map, você pode descobrir endpoints fornecendo um filtro na solicitação
A figura a seguir mostra como essa abordagem pode ser usada para vários tipos de workload.
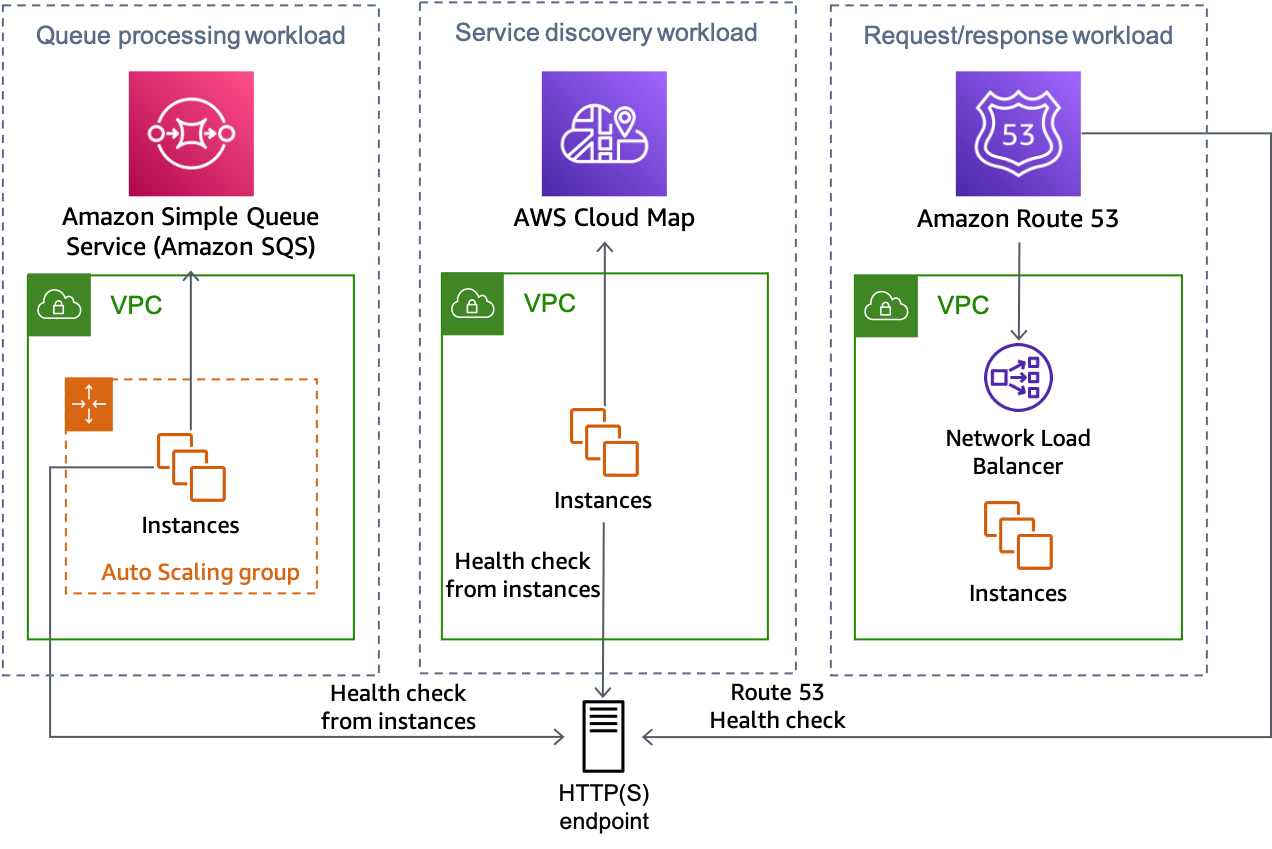
Vários tipos de workload, em que todos podem usar a solução de endpoint HTTP
Há várias maneiras de implementar a abordagem de endpoint HTTP, duas delas serão descritas a seguir.
Uso do Amazon S3
Esse padrão foi apresentado originalmente nesta postagem do blog sobre
Nesse cenário, você criaria conjuntos de registros de recursos DNS do Route 53 para cada registro DNS de zona, assim como o cenário ARC do Route 53 acima, bem como as verificações de integridade associadas. No entanto, para essa implementação, em vez de associar as verificações de integridade aos controles de roteamento ARC do Route 53, elas são configuradas para usar um endpoint HTTP e são invertidas para se protegerem contra um comprometimento no Amazon S3 que acidentalmente acione uma evacuação. A verificação de integridade é considerada íntegra quando o objeto está ausente e não íntegra quando o objeto está presente. Essa configuração é mostrada na tabela a seguir.
Tabela 4: Configuração do registro DNS para usar as verificações de integridade do Route 53 por zona de disponibilidade
|
Tipo de verificação de integridade: monitorar um endpoint Protocolo: ID: URL: |
Tipo de verificação de integridade: monitorar um endpoint Protocolo: ID: URL: |
Tipo de verificação de integridade: monitorar um endpoint Protocolo: ID: URL: |
← | Verificações de integridade |
| ↑ | ↑ | ↑ | ||
|
Política de roteamento: ponderada Nome: Tipo: Value (Valor): Peso: Avaliar status do destino: |
Política de roteamento: ponderada Nome: Tipo: Value (Valor): Peso: Avaliar status do destino: |
Política de roteamento: ponderada Nome: Tipo: Value (Valor): Peso: Avaliar status do destino: |
← | Os registros de alias A de nível superior e com ponderação uniforme apontam para endpoints específicos da ZD do NLB |
Vamos supor que a zona de disponibilidade us-east-1a esteja mapeada na conta use1-az3 em que temos um workload que queremos realizar uma evacuação da zona de disponibilidade. Pois o conjunto de registros de recursos criado para us-east-1a.load-balancer-name.elb.us-east-1.amazonaws.com associaria uma verificação de integridade que testa o URL https://. Quando quiser iniciar uma evacuação da zona de disponibilidade para bucket-name.s3.us-east-1.amazonaws.com/use1-az3.txtuse1-az3, faça upload de um arquivo com nome de use1-az3.txt para o bucket usando a CLI ou a API. O arquivo não precisa conter nenhum conteúdo, mas precisa ser público para que a verificação de integridade do Route 53 possa acessá-lo. A figura a seguir demonstra que essa implementação está sendo usada para evacuar use1-az3.
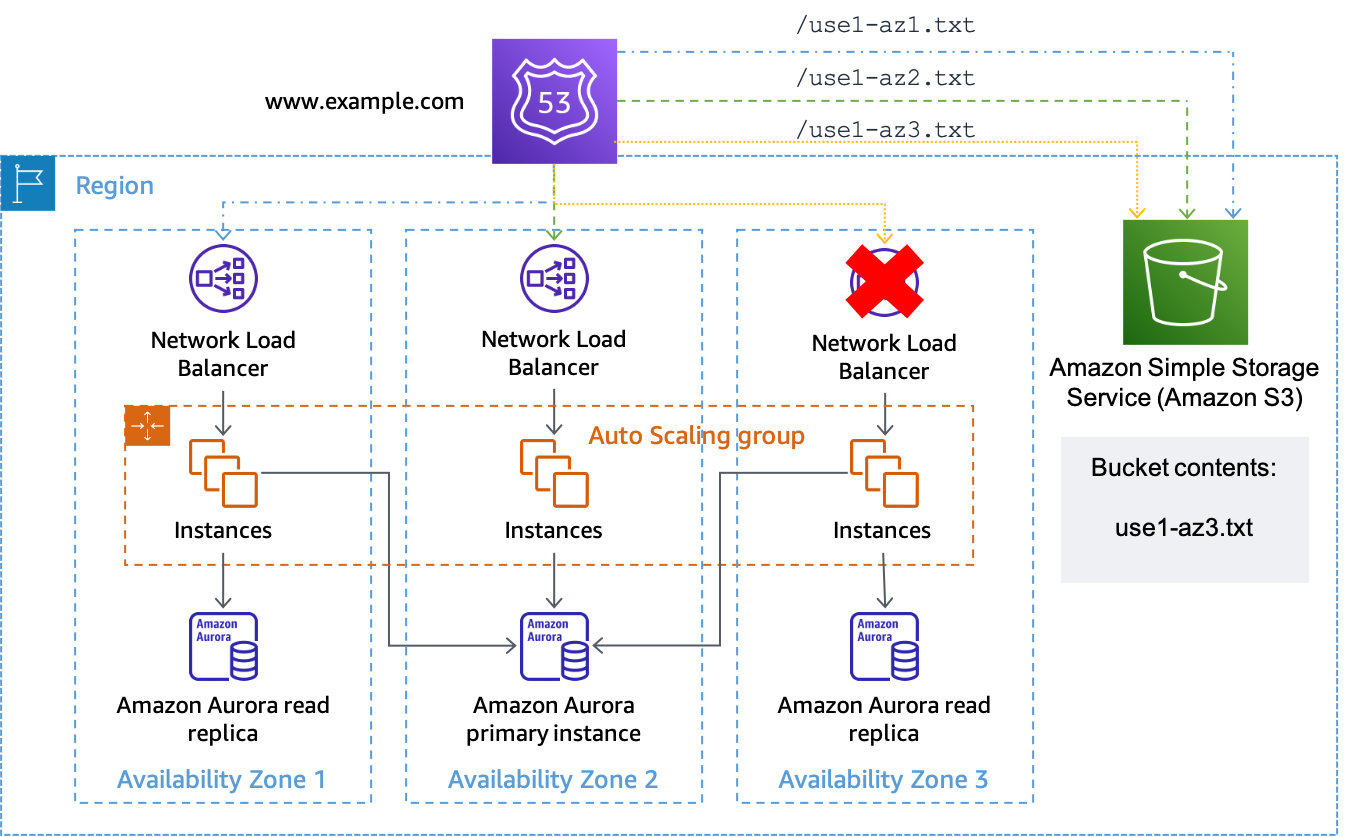
Uso do Amazon S3 como destino para uma verificação de integridade do Route 53
Uso da API Gateway e o DynamoDB
A segunda implementação desse padrão usa uma API REST do Amazon API Gateway
Se você estiver usando essa solução com uma arquitetura NLB ou ALB, configure seus registros DNS da mesma forma que o exemplo do Amazon S3 acima, exceto altere o caminho da verificação de integridade para usar o endpoint da API Gateway e forneça o AZ-ID no caminho do URL. Por exemplo, se a API Gateway estiver configurada com um domínio personalizado de az-status.example.com, a solicitação completa de use1-az1 seria semelhante a https://az-status.example.com/status/use1-az1. Quando quiser iniciar uma evacuação da zona de disponibilidade, você pode criar ou atualizar um item do DynamoDB usando a CLI ou a API. O item usa o AZ-ID como chave primária e, em seguida, tem um atributo booleano chamado Healthy, que é usado para indicar como a API Gateway responde. Veja a seguir um exemplo de código usado na configuração da API Gateway para fazer essa determinação.
#set($inputRoot = $input.path('$')) #if ($inputRoot.Item.Healthy['BOOL'] == (false)) #set($context.responseOverride.status = 500) #end
Se o atributo for true (ou não presente), a API Gateway responderá à verificação de integridade com um HTTP 200; se for falso, ela responderá com um HTTP 500. Essa implementação é mostrada na figura a seguir.
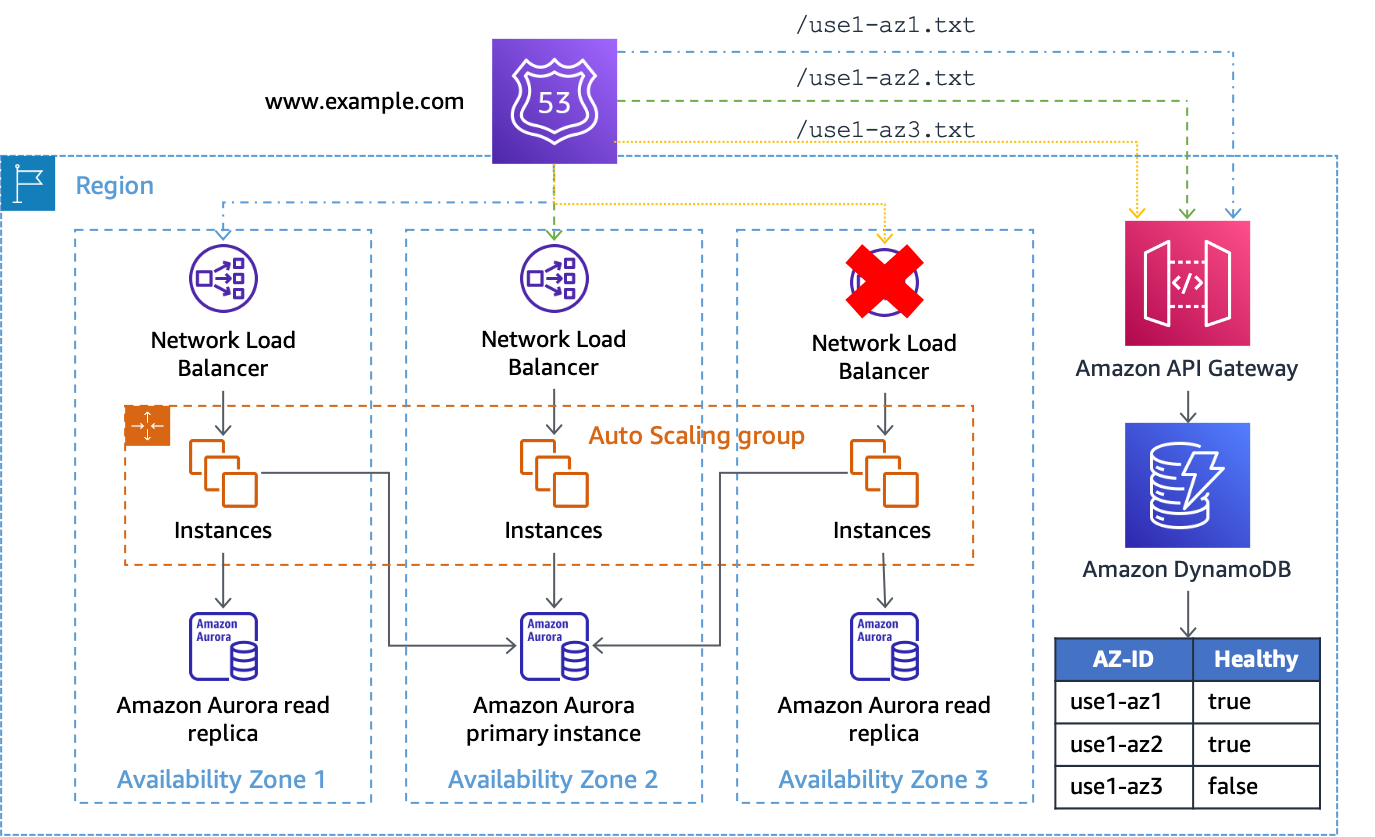
Uso da API Gateway e o DynamoDB como destino das verificações de integridade do Route 53
Nessa solução, você precisa usar a API Gateway na frente do DynamoDB para tornar o endpoint acessível ao público, bem como manipular a URL da solicitação em uma solicitação de GetItem para o DynamoDB. A solução também oferece flexibilidade se você quiser incluir dados adicionais na solicitação. Por exemplo, se quiser criar status mais granulares, como por aplicativo, poderá configurar a URL da verificação de integridade para fornecer um ID do aplicativo no caminho ou na string de consulta que também corresponda ao item do DynamoDB.
O endpoint de status da zona de disponibilidade pode ser implantado de maneira centralizada para que vários recursos de verificação de integridade em Contas da AWS que podem usar a mesma visão consistente da integridade da zona de disponibilidade (garantindo que a API REST da API Gateway e a tabela do DynamoDB sejam dimensionadas para lidar com a carga) e elimine a necessidade de compartilhar as verificações de integridade do Route 53.
A solução também pode ser escalada em várias Regiões da AWS usando uma tabela global do Amazon DynamoDB
Se você estava criando uma solução para hosts individuais usarem como um mecanismo para determinar a integridade de sua ZD, como alternativa, em vez de fornecer um mecanismo de extração para verificações de integridade, você pode usar notificações push. Uma maneira de fazer isso é com um tópico do SNS que seus consumidores assinam. Quando quiser acionar o disjuntor, publique uma mensagem no tópico do SNS indicando qual zona de disponibilidade está comprometida. Essa abordagem tem desvantagens comparada com a anterior. Ela elimina a necessidade de criar e operar a infraestrutura da API Gateway e realizar o gerenciamento de capacidade. Também pode potencialmente fornecer uma convergência mais rápida do estado da zona de disponibilidade. No entanto, ela remove a capacidade de realizar consultas ad hoc e depende da política de novas tentativas de entrega do SNS para garantir que cada endpoint receba a notificação. Também exige que cada workload ou serviço crie uma forma de receber a notificação do SNS e realizar ações sobre ela.
Por exemplo, cada lançamento de uma nova instância ou contêiner do EC2 deverá ser inscrito no tópico com um endpoint HTTP durante a inicialização. Em seguida, cada instância precisa implementar um software que escute esse endpoint em que a notificação é entregue. Além disso, se a instância for afetada pelo evento, ela poderá não receber a notificação push e continuar trabalhando. Por outro lado, com uma notificação pull, a instância saberá se sua solicitação de pull falhou e poderá escolher qual ação tomar em resposta.
Uma segunda forma de enviar notificações push é com conexões WebSocket de longa duração. O Amazon API Gateway pode ser usado para fornecer uma API de WebSocket à qual os consumidores podem se conectar e receber uma mensagem quando enviada pelo back-end. Com um WebSocket, as instâncias podem fazer buscas periódicas para garantir que a conexão esteja íntegra e também receber notificações push de baixa latência.
