Cenário 5: monitoramento de dados de telemetria em tempo real com o Apache Kafka
A ABC1Cabs é uma empresa de serviços de reserva de táxi on-line. Todas as cabines têm dispositivos IoT que coletam dados de telemetria dos veículos. Atualmente, a ABC1Cabs está executando clusters do Apache Kafka projetados para consumo de eventos em tempo real, reunindo métricas de integridade do sistema, rastreamento de atividades e alimentando os dados na plataforma Apache Spark Streaming criada em um cluster do Hadoop on-premises.
A ABC1Cabs usa o OpenSearch Dashboards para métricas de negócios, depuração, alertas e criação de outros painéis. Eles estão interessados no Amazon MSK, no Amazon EMR com Spark Streaming e no OpenSearch Service com OpenSearch Dashboards. Seu requisito é reduzir a sobrecarga administrativa da manutenção de clusters do Apache Kafka e do Hadoop, ao mesmo tempo em que usam softwares e APIs de código aberto conhecidos para orquestrar o pipeline de dados. O diagrama de arquitetura a seguir mostra a solução deles na AWS.
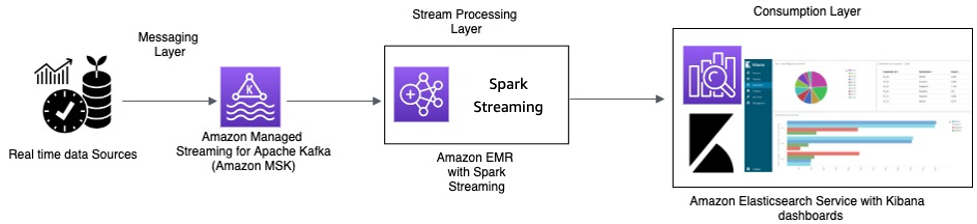
Processamento em tempo real com o Amazon MSK e o processamento de fluxos usando o Apache Spark Streaming no Amazon EMR e Amazon OpenSearch Service com o OpenSearch Dashboards
Os dispositivos IoT das cabines coletam dados de telemetria e os enviam para um hub de origem. O hub de origem está configurado para enviar dados em tempo real para o Amazon MSK. Usando as APIs da biblioteca de produtores do Apache Kafka, o Amazon MSK é configurado para transmitir os dados em um cluster do Amazon EMR. O cluster do Amazon EMR tem um cliente Kafka e o Spark Streaming instalados para poder consumir e processar os fluxos de dados.
O Spark Streaming tem conectores de coletor que podem gravar dados diretamente em índices definidos do Elasticsearch. Os clusters do Elasticsearch com o OpenSearch Dashboards podem ser usados para métricas e painéis. O Amazon MSK, o Amazon EMR com Spark Streaming e o OpenSearch Service com OpenSearch Dashboards são todos serviços gerenciados, nos quais a AWS gerencia o esforço indiferenciado do gerenciamento de infraestrutura de diferentes clusters, o que permite que você crie sua aplicação usando software de código aberto familiar com poucos cliques. A próxima seção analisa mais de perto esses serviços.
Amazon Managed Streaming for Apache Kafka (Amazon MSK)
O Apache Kafka é uma plataforma de código aberto que permite aos clientes capturar dados de streaming, como eventos de clickstream, transações, eventos de IoT e logs de aplicações e máquinas. Com essas informações, é possível desenvolver aplicações que executam análises em tempo real, executam transformações contínuas e distribuem esses dados para data lakes e bancos de dados em tempo real.
Você pode usar o Kafka como um armazenamento de dados de streaming para dissociar aplicações do produtor e dos consumidores e permitir a transferência confiável de dados entre os dois componentes. Embora o Kafka seja uma plataforma popular de transmissão de dados e mensagens corporativas, pode ser difícil configurar, dimensionar e gerenciar na produção.
O Amazon MSK encarrega-se dessas tarefas de gerenciamento e facilita a instalação, a configuração e a execução do Kafka, juntamente com o Apache Zookeeper, em um ambiente que segue as práticas recomendadas de alta disponibilidade e segurança. Você ainda pode usar as operações do plano de controle e as operações do plano de dados do Kafka para gerenciar a produção e o consumo de dados.
Como o Amazon MSK executa e gerencia o Apache Kafka de código aberto, ele facilita a migração e a execução de aplicações Apache Kafka existentes na AWS sem precisar fazer alterações no código da aplicação.
Escalabilidade
O Amazon MSK oferece operações de escalabilidade para que o usuário possa escalar o cluster ativamente durante sua execução. Ao criar um cluster do Amazon MSK, você pode especificar o tipo de instância dos agentes na execução do cluster. É possível começar com alguns agentes em um cluster do Amazon MSK. Depois, usando o AWS Management Console ou A AWS CLI, você pode escalar até centenas de agentes por cluster.
Como alternativa, é possível escalar os clusters alterando o tamanho ou a família dos agentes Apache Kafka. Alterar o tamanho ou a família dos seus agentes oferece a você a flexibilidade de ajustar a capacidade computacional dos clusters do Amazon MSK para as mudanças em suas workloads. Use a Planilha de dimensionamento e definição de preço do Amazon MSK
Depois de criar o cluster do Amazon MSK, você pode aumentar a quantidade de armazenamento do EBS por agente, com exceção da diminuição do armazenamento. Os volumes de armazenamento permanecem disponíveis durante essa operação de expansão. Ele oferece dois tipos de operações de dimensionamento: autoescalabilidade e escalabilidade manual.
O Amazon MSK é compatível com a expansão automática do armazenamento do seu cluster em resposta ao aumento do uso utilizando políticas do Application Auto Scaling. Sua política de autoescalabilidade define a utilização de disco de destino e a capacidade máxima de escalabilidade.
O limite de utilização de armazenamento ajuda o Amazon MSK a acionar uma operação de autoescalabilidade. Para aumentar o armazenamento usando a escalabilidade manual, aguarde até que o cluster esteja no estado ACTIVE. A escalabilidade de armazenamento tem um período de desaquecimento de pelo menos seis horas entre os eventos. Embora a operação disponibilize armazenamento adicional imediatamente, o serviço realiza otimizações no cluster que podem levar até 24 horas ou mais.
A duração dessas otimizações é proporcional ao tamanho do armazenamento. Além disso, também oferece replicação de várias zonas de disponibilidade em uma região da AWS para fornecer alta disponibilidade.
Configuração
O Amazon MSK fornece uma configuração padrão para agentes, tópicos e nós Apache Zookeeper. Você também pode criar configurações personalizadas e usá-las para criar clusters do Amazon MSK ou atualizar clusters existentes. Quando você cria um cluster do MSK sem especificar uma configuração personalizada do Amazon MSK, o Amazon MSK cria e usa uma configuração padrão. Para obter uma lista desses valores padrão, consulte Configuração do Apache Kafka.
Para fins de monitoramento, o Amazon MSK reúne métricas do Apache Kafka e as envia ao Amazon CloudWatch, onde você pode visualizá-las. As métricas configuradas para os fluxos são coletadas e enviadas automaticamente ao CloudWatch. O monitoramento do atraso do consumidor permite identificar consumidores lentos ou estagnados que não estão acompanhando os dados mais recentes disponíveis em um tópico. Quando necessário, você pode tomar medidas corretivas, como escalar ou reiniciar esses consumidores.
Migrar para o Amazon MSK
A migração da estrutura on-premises para o Amazon MSK pode ser obtida por um dos métodos a seguir.
-
MirrorMaker2.0: o MirrorMaker2.0 (MM2) MM2 é um mecanismo de replicação de dados de vários clusters baseado na framework do Apache Kafka Connect. O MM2 é uma combinação de um conector de fonte do Apache Kafka e um conector coletor. É possível usar um único cluster do MM2 para migrar dados entre vários clusters. O MM2 detecta automaticamente novos tópicos e partições, além de garantir que as configurações de tópico sejam sincronizadas entre clusters. O MM2 é compatível com a migrações de ACLs, configurações de tópicos e conversão de deslocamento. Para obter mais detalhes relacionados à migração, consulte Migrar clusters com o uso do MirrorMaker do Apache Kafka. O MM2 é usado automaticamente para casos de uso relacionados à replicação de configurações de tópicos e conversão de deslocamento.
-
Apache Flink: o MM2 é compatível com a semântica do tipo exatamente uma vez. Os registros podem ser duplicados para o destino e espera-se que os consumidores sejam idempotentes para lidar com registros duplicados. Em cenários de exatamente uma vez, a semântica é necessária para que os clientes possam usar o Apache Flink. Ele fornece uma alternativa para obter uma semântica do tipo exatamente uma vez.
O Apache Flink também pode ser usado para cenários em que os dados exigem ações de mapeamento ou transformação antes do envio ao cluster de destino. O Apache Flink fornece conectores para o Apache Kafka com fontes e coletores que podem ler dados de um cluster do Apache Kafka e gravar em outro. O Apache Flink pode ser executado na AWS iniciando um cluster do Amazon EMR ou executando o Apache Flink como uma aplicação usando o Amazon Kinesis Data Analytics.
-
AWS Lambda: com suporte para o Apache Kafka como fonte de eventos para AWS Lambda
, os clientes agora podem consumir mensagens de um tópico por meio de uma função do Lambda. O serviço AWS Lambda pesquisa internamente novos registros ou mensagens da fonte do evento e, depois, chama de forma síncrona a função do Lambda de destino para consumir essas mensagens. O Lambda lê as mensagens em lotes e fornece os lotes de mensagens para sua função na carga útil do evento para processamento. As mensagens consumidas podem ser transformadas e/ou gravadas diretamente no cluster do Amazon MSK de destino.
Amazon EMR com Spark Streaming
O Amazon EMR
O Amazon EMR fornece os recursos do Spark e pode ser usado para iniciar o streaming do Spark para consumir dados do Kafka. O Spark Streaming é uma extensão da API principal do Spark que permite o processamento escalável, de alta taxa de transferência e tolerante a falhas de fluxos de dados ao vivo.
É possível criar um cluster do Amazon EMR usando o AWS Command Line Interface
Os dados processados podem ser enviados para sistemas de arquivos, bancos de dados e painéis dinâmicos.
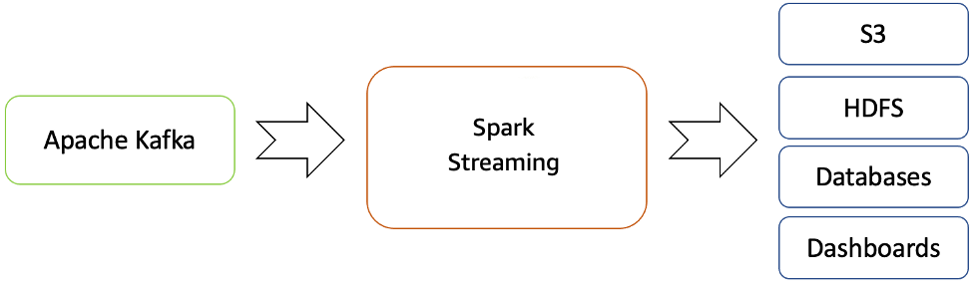
Fluxo de streaming em tempo real do Apache Kafka para o ecossistema Hadoop
Por padrão, o Apache Spark Streaming tem um modelo de execução de microlote. No entanto, desde que o Spark 2.3 foi lançado, o Apache introduziu um novo modo de processamento de baixa latência chamado Processamento contínuo, que pode atingir latências de ponta a ponta tão baixas quanto um milissegundo com garantias de pelo menos uma vez.
Sem alterar as operações Dataset/DataFrames em suas consultas, você pode escolher o modo com base nos requisitos da sua aplicação. Alguns dos benefícios do Spark Streaming são:
-
Ele traz a API integrada à linguagem
do Apache Spark para o processamento de streaming, permitindo que você escreva trabalhos de streaming da mesma forma que escreve trabalhos em lote. -
É compatível com Java, Scala e Python.
-
Ele pode recuperar o trabalho perdido e o estado do operador (como janelas deslizantes) predefinidos, sem nenhum código adicional de sua parte.
-
Ao ser executado no Spark, o Spark Streaming permite reutilizar o mesmo código para processamento em lote, unir fluxos com dados históricos ou executar consultas ad hoc no estado do fluxo e criar aplicações interativas avançadas, não apenas análises.
-
Depois que o fluxo de dados é processado com o Spark Streaming, o OpenSearch Sink Connector pode ser usado para gravar dados no cluster do OpenSearch Service e, por sua vez, o OpenSearch Service com o OpenSearch Dashboards pode ser usado como camada de consumo.
Amazon OpenSearch Service com OpenSearch Dashboards
O OpenSearch Service é um serviço gerenciado que facilita a implantação, a operação e o escala de clusters do OpenSearch na Nuvem AWS. O OpenSearch é um conhecido mecanismo de pesquisa e análise de código aberto para casos de uso, como análise de log, monitoramento de aplicações em tempo real e análise de clickstream.
O OpenSearch Dashboards
O OpenSearch Dashboards fornece uma forte integração com o OpenSearch
Resumo
Com o Apache Kafka oferecido como um serviço gerenciado na AWS, é possível se concentrar no consumo em vez de gerenciar a coordenação entre os agentes, o que geralmente requer um entendimento detalhado do Apache Kafka. Recursos como alta disponibilidade, escalabilidade de agentes e controle de acesso granular são gerenciados pela plataforma Amazon MSK.
A ABC1Cabs utilizou esses serviços para criar aplicações de produção sem precisar de experiência em gerenciamento de infraestrutura. Eles puderam se concentrar na camada de processamento para consumir dados do Amazon MSK e se propagar ainda mais para a camada de visualização.
O Spark Streaming no Amazon EMR pode ajudar na análise em tempo real de dados de streaming e na publicação no OpenSearch Dashboards
