Track objects in video frames using video frame object tracking
You can use the video frame object tracking task type to have workers track the movement of objects in a sequence of video frames (images extracted from a video) using bounding boxes, polylines, polygons or keypoint annotation tools. The tool you choose defines the video frame task type you create. For example, you can use a bounding box video frame object tracking task type to ask workers to track the movement of objects, such as cars, bikes, and pedestrians by drawing boxes around them.
You provide a list of categories, and each annotation that a worker adds to a video frame is identified as an instance of that category using an instance ID. For example, if you provide the label category car, the first car that a worker annotates will have the instance ID car:1. The second car the worker annotates will have the instance ID car:2. To track an object's movement, the worker adds annotations associated with the same instance ID around to object in all frames.
You can create a video frame object tracking labeling job using the Amazon SageMaker AI Ground Truth console, the SageMaker API, and language-specific AWS SDKs. To learn more, see Create a Video Frame Object Detection Labeling Job and select your preferred method. See Task types to learn more about the annotations tools you can choose from when you create a labeling job.
Ground Truth provides a worker UI and tools to complete your labeling job tasks: Preview the Worker UI.
You can create a job to adjust annotations created in a video object detection labeling job using the video object detection adjustment task type. To learn more, see Create Video Frame Object Detection Adjustment or Verification Labeling Job.
Preview the Worker UI
Ground Truth provides workers with a web user interface (UI) to complete your video frame object tracking annotation tasks. You can preview and interact with the worker UI when you create a labeling job in the console. If you are a new user, we recommend that you create a labeling job through the console using a small input dataset to preview the worker UI and ensure your video frames, labels, and label attributes appear as expected.
The UI provides workers with the following assistive labeling tools to complete your object tracking tasks:
-
For all tasks, workers can use the Copy to next and Copy to all features to copy an annotation with the same unique ID to the next frame or to all subsequent frames respectively.
-
For tasks that include the bounding box tools, workers can use a Predict next feature to draw a bounding box in a single frame, and then have Ground Truth predict the location of boxes with the same unique ID in all other frames. Workers can then make adjustments to correct predicted box locations.
The following video shows how a worker might use the worker UI with the bounding box tool to complete your object tracking tasks.

Create a Video Frame Object Tracking Labeling Job
You can create a video frame object tracking labeling job using the SageMaker AI console
or the CreateLabelingJob API operation.
This section assumes that you have reviewed the Video frame labeling job reference and have chosen the type of input data and the input dataset connection you are using.
Create a Labeling Job (Console)
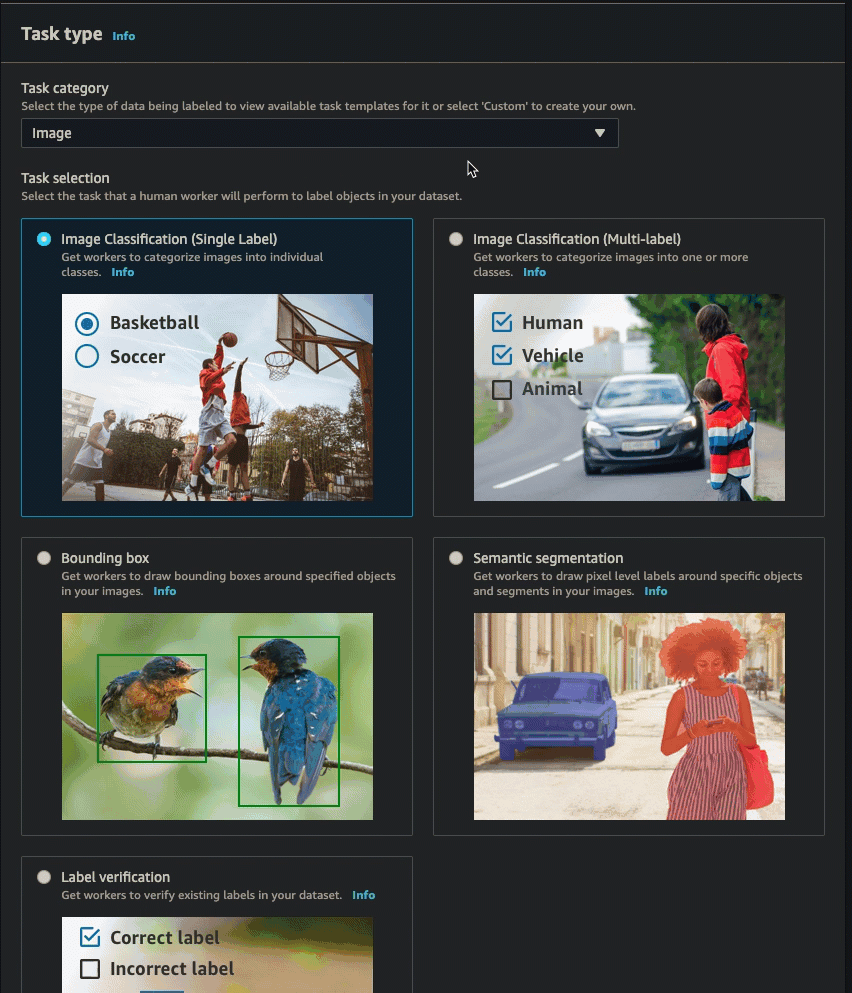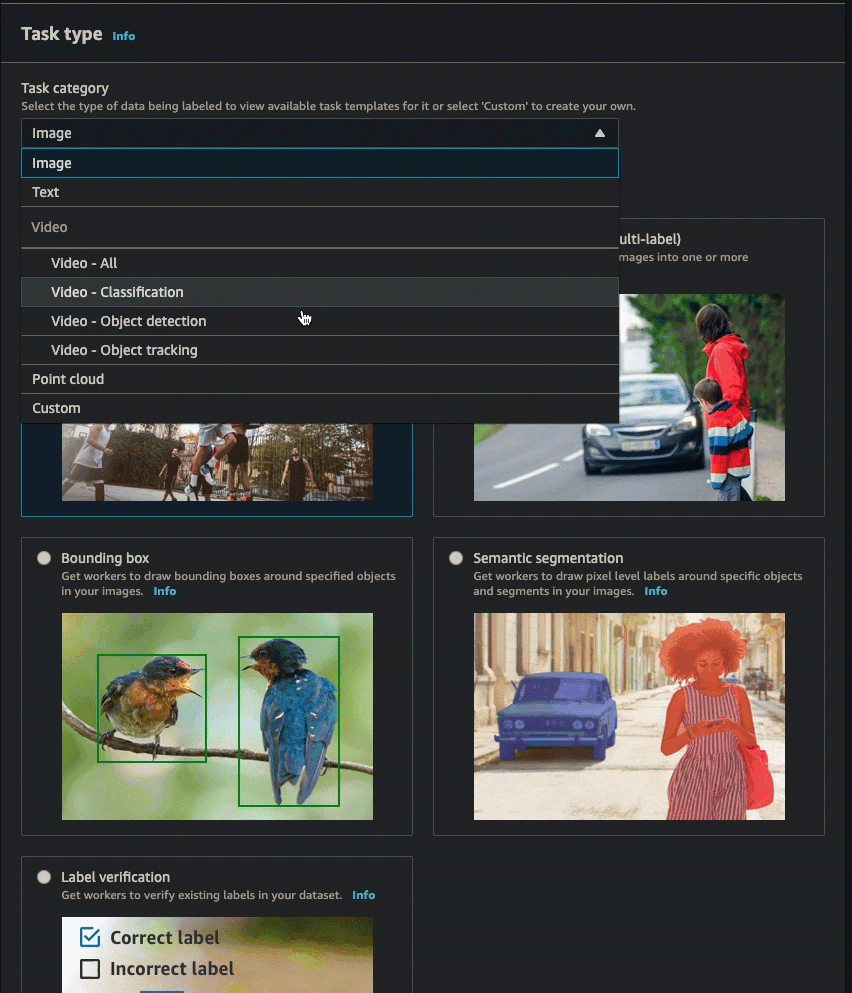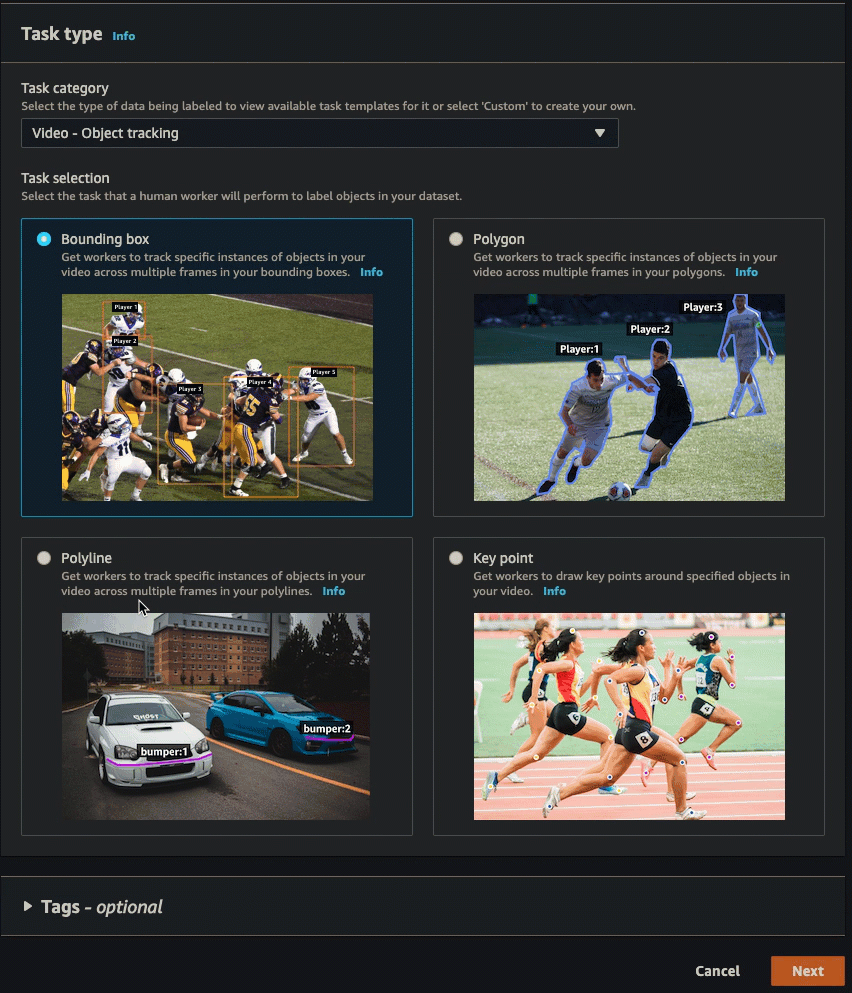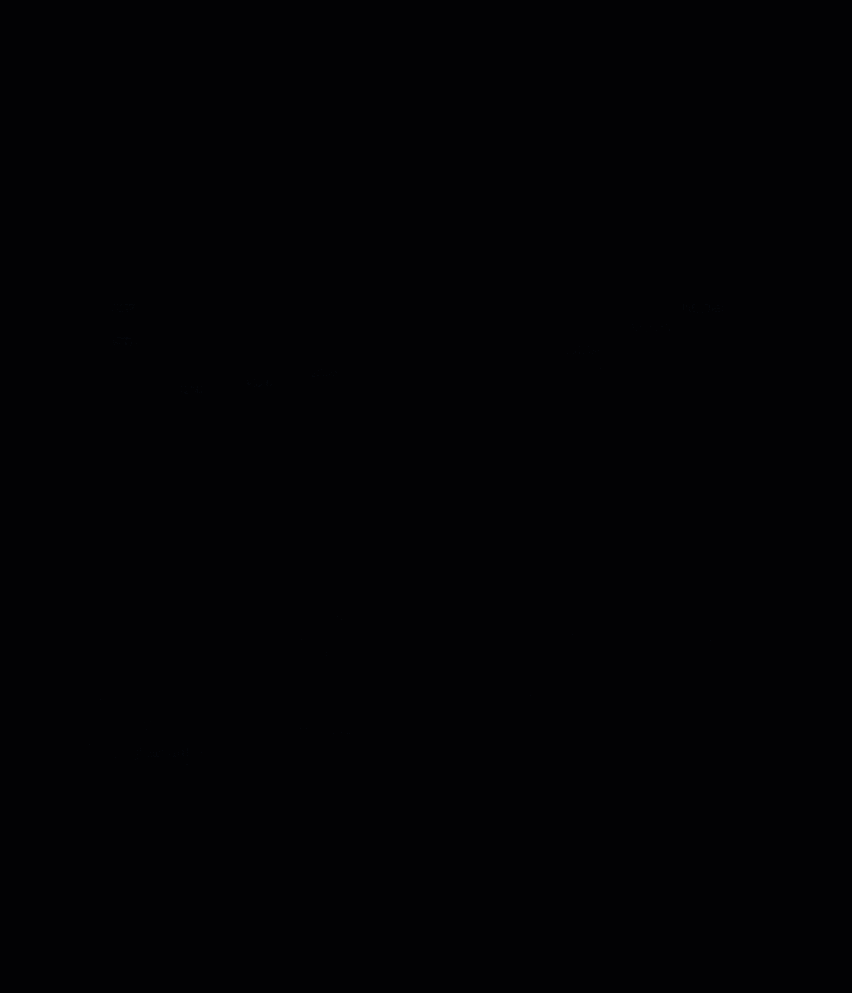
You can follow the instructions in Create a Labeling Job (Console) to learn how to create a video frame object tracking job in the SageMaker AI console. In step 10, choose Video - Object tracking from the Task category dropdown list. Select the task type you want by selecting one of the cards in Task selection.
Create a Labeling Job (API)
You create an object tracking labeling job using the SageMaker API operation
CreateLabelingJob. This API defines this operation for all
AWS SDKs. To see a list of language-specific SDKs supported for this
operation, review the See Also section of CreateLabelingJob.
Create a Labeling Job (API) provides an overview of
the CreateLabelingJob operation. Follow these instructions and
do the following while you configure your request:
-
You must enter an ARN for
HumanTaskUiArn. Usearn:aws:sagemaker:. Replace<region>:394669845002:human-task-ui/VideoObjectTracking<region>Do not include an entry for the
UiTemplateS3Uriparameter. -
Your
LabelAttributeNamemust end in-ref. For example,ot-labels-ref -
Your input manifest file must be a video frame sequence manifest file. You can create this manifest file using the SageMaker AI console, or create it manually and upload it to Amazon S3. For more information, see Input Data Setup. If you create a streaming labeling job, the input manifest file is optional.
-
You can only use private or vendor work teams to create video frame object detection labeling jobs.
-
You specify your labels, label category and frame attributes, the task type, and worker instructions in a label category configuration file. Specify the task type (bounding boxes, polylines, polygons or keypoint) using
annotationTypein your label category configuration file. For more information, see Labeling category configuration file with label category and frame attributes reference to learn how to create this file. -
You need to provide pre-defined ARNs for the pre-annotation and post-annotation (ACS) Lambda functions. These ARNs are specific to the AWS Region you use to create your labeling job.
-
To find the pre-annotation Lambda ARN, refer to
PreHumanTaskLambdaArn. Use the Region in which you are creating your labeling job to find the correct ARN that ends withPRE-VideoObjectTracking. -
To find the post-annotation Lambda ARN, refer to
AnnotationConsolidationLambdaArn. Use the Region in which you are creating your labeling job to find the correct ARN that ends withACS-VideoObjectTracking.
-
-
The number of workers specified in
NumberOfHumanWorkersPerDataObjectmust be1. -
Automated data labeling is not supported for video frame labeling jobs. Do not specify values for parameters in
LabelingJobAlgorithmsConfig. -
Video frame object tracking labeling jobs can take multiple hours to complete. You can specify a longer time limit for these labeling jobs in
TaskTimeLimitInSeconds(up to 7 days, or 604,800 seconds).
The following is an example of an AWS Python SDK (Boto3) request
response = client.create_labeling_job( LabelingJobName='example-video-ot-labeling-job, LabelAttributeName='label', InputConfig={ 'DataSource': { 'S3DataSource': { 'ManifestS3Uri':'s3://amzn-s3-demo-bucket/path/video-frame-sequence-input-manifest.json'} }, 'DataAttributes': { 'ContentClassifiers': ['FreeOfPersonallyIdentifiableInformation'|'FreeOfAdultContent', ] } }, OutputConfig={ 'S3OutputPath':'s3://amzn-s3-demo-bucket/prefix/file-to-store-output-data', 'KmsKeyId':'string'}, RoleArn='arn:aws:iam::*:role/*, LabelCategoryConfigS3Uri='s3://bucket/prefix/label-categories.json', StoppingConditions={ 'MaxHumanLabeledObjectCount':123, 'MaxPercentageOfInputDatasetLabeled':123}, HumanTaskConfig={ 'WorkteamArn':'arn:aws:sagemaker:us-east-1:*:workteam/private-crowd/*', 'UiConfig': { 'HumanTaskUiArn: 'arn:aws:sagemaker:us-east-1:394669845002:human-task-ui/VideoObjectTracking' }, 'PreHumanTaskLambdaArn': 'arn:aws:lambda:us-east-1:432418664414:function:PRE-VideoObjectTracking', 'TaskKeywords': ['Video Frame Object Tracking, ], 'TaskTitle':'Video frame object tracking task', 'TaskDescription':Tracking the location of objects and people across video frames', 'NumberOfHumanWorkersPerDataObject':123, 'TaskTimeLimitInSeconds':123, 'TaskAvailabilityLifetimeInSeconds':123, 'MaxConcurrentTaskCount':123, 'AnnotationConsolidationConfig': { 'AnnotationConsolidationLambdaArn': 'arn:aws:lambda:us-east-1:432418664414:function:ACS-VideoObjectTracking' }, Tags=[ { 'Key':'string', 'Value':'string'}, ] )
Create a Video Frame Object Tracking Adjustment or Verification Labeling Job
You can create an adjustment and verification labeling job using the Ground Truth console
or CreateLabelingJob API. To learn more about adjustment and
verification labeling jobs, and to learn how create one, see Label verification and adjustment.
Output Data Format
When you create a video frame object tracking labeling job, tasks are sent to workers. When these workers complete their tasks, labels are written to the Amazon S3 output location you specified when you created the labeling job. To learn about the video frame object tracking output data format, see Video frame object tracking output. If you are a new user of Ground Truth, see Labeling job output data to learn more about the Ground Truth output data format.
