Analysis state machine
The Media2Cloud on AWS solution includes an analysis state machine that is composed of four different AWS Step Functions sub-state machines and a set of AWS Lambda functions that start, monitor, and collect results from the sub-state machines. The analysis state machine consists of the following sub-state machines:
-
A video analysis sub-state machine that manages the video-based analysis process
-
An audio analysis sub-state machine that manages the audio-based analysis process
-
An image analysis sub-state machine that manages the image-based analysis process
-
A document analysis sub-state machine that manages the document-based analysis process
When the ingestion process is completed, the solution automatically starts the analysis process. Similar to the ingestion state machine, the analysis state machine publishes progress and status to an AWS IoT topic. The web interface processes the progress status and displays it to the customer.
-
Prepare analysis - Checks the incoming analysis request and prepares the optimal AI/ML analysis options to run based on the media type of the file and the availability of specific detections.
-
Video analysis enabled? - Checks whether video analysis is activated by checking the
$.input.video.enabledflag. -
Start video analysis and wait (nested) – Starts and waits for the video analysis sub-state machine where it runs Computer Vision (CV) analysis on the video using Amazon Rekognition if the media type of the file is a video. This follows a state to check if video analysis is activated.
-
Skip video analysis - An end state to indicate video analysis is not activated.
-
Audio analysis enabled? – Checks whether audio analysis is activated by checking the
$.input.audio.enabledflag. -
Start audio analysis and wait (nested) - Starts and waits for the audio analysis sub-state machine where it runs speech-to-text and Natural Language Processing (NLP) analysis using Amazon Transcribe and Amazon Comprehend if the file is an audio file. This follows a state to check if audio analysis is activated.
-
Skip audio analysis - An end state to indicate audio analysis is not activated.
-
Image analysis enabled? - Checks whether image analysis is activated by checking the $.input.image.enabled flag.
-
Start image analysis and wait (nested) - Starts and waits for the image analysis sub-state machine where it runs Computer Vision (CV) analysis using Amazon Rekognition if the file is an image type. This follows a state to check If image analysis is activated.
-
Skip image analysis - An end state to indicate image analysis is not activated.
-
Document analysis enabled? - Checks whether document analysis is activated by checking the
$.input.document.enabledflag. -
Start document analysis and wait (nested) - Starts and waits for the document analysis sub-state machine where it runs Optical Character Recognition (OCR) analysis using Amazon Textract. This follows a state to check if document analysis is activated.
-
Skip document analysis - An end state to indicate image analysis is not activated.
-
Collect analysis results - Collects outputs from each sub-state machine by calling the
Step Functions.DescribeExecutionAPI, parses, and joins the results. -
Analysis completed - Updates the
analysisfield of the DynamoDB ingestion table to indicate the types of analysis that have been run. The Lambda function also creates records on the DynamoDBaimltable with information including start time and end time of each analysis detection, pointers to where the analysis metadata JSON results are stored in an Amazon S3 proxy bucket, the job name of the detection, and the ARN of the state machine run.
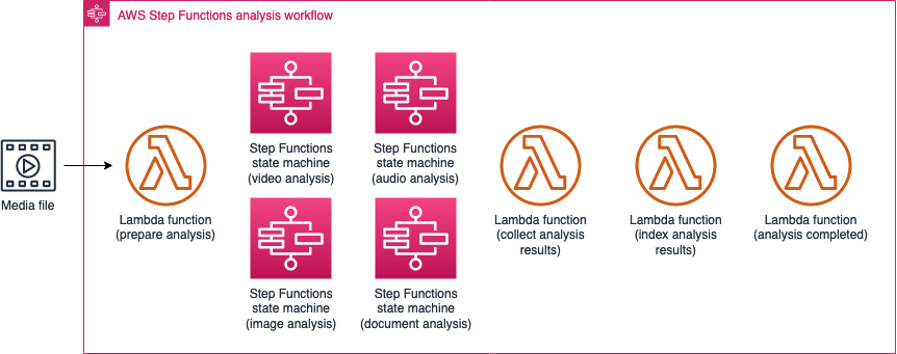
Analysis workflow
Video analysis sub-state machine
The video analysis sub-state machine is managed by the analysis state machine. It runs a series of Amazon Rekognition async processes to extract faces, celebrities, labels, moderation, and face match data from the video file. This sub-state machine consists of three parallel branches where each branch runs and monitors a specific Amazon Rekognition async process:
-
Frame-based detectors: This branch uses image frames of the video and Amazon Rekognition image APIs to analyze a video file (celebrity recognition, label detection, or moderation detection).
-
Video-based detectors: This branch uses Amazon Rekognition video APIs (segment detection or people pathing detection) to analyze a video file.
-
Custom detectors: This branch activates Amazon Rekognition Custom Labels detection using the image frames of a video file.
The branches that run during analysis depend on the APIs the user selects to use to process content. In the most complex scenario, the user selects frame-based analysis but also activates segment and people pathing detections which are available with Amazon Rekognition Video APIs, and Custom Label detection to detect specialized objects in the video. In this case, all the branches run where the frame-based branch runs analysis for celebrity, label, and moderation detections using Amazon Rekognition image APIs, the video-based branch runs segment and people pathing detections with Amazon Rekognition video APIs, and the custom-based branch runs Custom Labels detection using Amazon Rekognition Custom Label APIs. The state machine uses Step Functions Map state to parallelize the detection processes.
The video analysis sub-state machine orchestrates the following tasks using AWS Lambda functions:
-
Frame-based detection iterators - Formats the user's selection as input into an array of a set of iterators for the map state. With the
Mapstate, each iterator specifies the type of detection to run, for example,celeb,label, ormoderationand pointers to the image frames. -
Detect frame (iterator) - Runs the detection specified in the iterator's input. For example, if the type is $.data.celeb, the Lambda function uses the
RecognizeCelebritiesAPI to detect celebrities. The Lambda function also stores the detection JSON result to an S3 proxy bucket. This process repeats until all the image frames are processed or when the Lambda runtime is close to the 15- minute limit. -
Detect frames completed - Indicates the detection of the specific type has completed.
-
Frame-based track iterators – Joins the results from the previous iterators and prepares for the next Map state where it generates WebVTT tracks and timeseries tracks.
-
Create frame-based track (iterator) - Fetches and parses the detection JSON result to create WebVTT track and timeseries track based on the timestamps of each of the detected item. The WebVTT track is used by the web application to activate on-screen display of the detection result. The timeseries data track is used by the web application to activate charts.
-
Index frame-based analysis (iterator) - Uses the timeseries tracked created earlier and indexes the timestamped metadata document to an OpenSearch Service index. Each type of the detections, specifically,
celeb,label,text,moderationhas its own index. -
Video-based detection iterators - Formats the input into an array, a set of iterators for the Map state where each iterator specifies the type of detection to run specifically,
celeb,labelormoderationand pointers to the video file. -
Start detection and wait (iterator) - Starts and waits for a specific Amazon Rekognition video job for example, StartCelebrityDetection and StartLabelDetectionasynchronously.
-
Collect detection results (iterator) - Collects the detection JSON results by calling Amazon Rekognition
GetLabelDetectionandGetPersonTracking. It then stores the JSON results to an S3 proxy bucket. -
Create video-based track (iterator) - Similar to Create frame-based track (Iterator) state.
-
Index video-based analysis (iterator) - Similar to Index frame-based analysis (Iterator) state.
-
Custom detection iterators - Formats the input into an array, a set of iterators for the
Mapstate. The difference is that each iterator specifies the type of Custom Labels model to run. -
Start custom and wait (iterator) - Similar to Frame-based detection iterators, formats the input into an array, a set of iterators for the Map state. The difference is that each iterator specifies the type of Custom Labels model to run.
-
Collect custom results (iterator) - Collects the Custom Label JSON results.
-
Create custom track (iterator) - Similar to Create frame-based track (Iterator) state.
-
Index custom analysis (iterator) - Similar to Index frame-based analysis (Iterator) state. The difference is that it indexes the document to the customlabel index in the OpenSearch Service cluster.
-
Video analysis completed – Merges all outputs from the parallel branches.

Video analysis sub-state machine workflow
Audio analysis sub-state machine
The audio analysis sub-state machine is managed by the analysis state machine. This sub-state machine runs Amazon Transcribe and Amazon Comprehend to extract transcription, entities, key phrases, sentiments, topic, and classification metadata. This sub-state machine first runs Amazon Transcribe to convert speech to text and starts a number of branches in parallel where each branch runs and monitors a specific Amazon Comprehend process.
-
Start transcribe and wait - Calls the Amazon Transcribe
StartTranscriptionJobasync API to start an Amazon Transcribe job for the audio file in batch mode and waits for the job to complete. -
Collect transcribe results – Ensures that the transcription job is completed (not failed). Also ensures that the transcription results (JSON file) and the Amazon Transcribe generated subtitle file (WebVTT format) are present and stored in an S3 proxy bucket.
-
Index transcribe results - Downloads and parses the WebVTT file using an open-source package node-webvtt
. Indexes the entities to the OpenSearch Service cluster under the transcribeindex. -
Batch detect entities - Runs Amazon Comprehend BatchDetectEntities to extract entities from the transcription and converts the character-based offset to timestamp-based results. The Lambda function preserves and stores the original entity results from Amazon Comprehend service to an S3 proxy bucket and stores the timestamped version of metadata result (JSON) which is used to index the entities later on in an S3 proxy bucket.
-
Index entity results - Downloads the metadata result and indexes the entity results to the OpenSearch Service cluster under the
entityindex. -
Batch detect key phrases - Runs Amazon Comprehend BatchDetectKeyPhrases and stores the original key phrase results and the timestamped metadata JSON file in an S3 proxy bucket.
-
Index key phrase results - Downloads the metadata result and indexes the key phrase results to the OpenSearch Service cluster under the
keyphraseindex. -
Batch detect sentiments - Runs Amazon Comprehend BatchDetectSentiment and stores the original sentiment results and the timestamped metadata JSON file in an S3 proxy bucket.
-
Index sentiment results – Downloads the metadata result and indexes the sentiment results to the OpenSearch Service cluster under the
sentimentindex. -
Check custom entity criteria - Ensures that the Custom Entity Recognizer is runnable and the language code of the transcription result is same as the language code of the trained recognizer. If the criteria are met, the state Lambda function prepares the documents to be analyzed, stores them in an S3 proxy bucket - s3://
PROXY_BUCKET/UUID/FILE_BASENAME/raw/DATETIME/comprehend/customentity/document-XXX.txtand sets the$.data.comprehend.customentity.prefixfield to indicate there are documents to be processed. -
Can start custom entity? - Determines custom entity detection can start by checking the
$.data.comprehend.customentity.prefixflag. If the flag is present, transitions to Start and wait custom entity state. Otherwise, transitions to Custom entity skipped state. -
Start and wait custom entity - Starts the custom entity detection by invoking
StartEntitiesDetectionJobAPI asynchronously. -
Wait for custom entity statues (3 mins) - A wait state for 3 minutes and transitions to a state to Check custom entity status state.
-
Check custom entity status - Checks the entity job by calling
DescribeEntitiesDetectionJobAPI and stores the job status to $.status. -
Custom entity completed - Checks
$.status. If it is set to COMPLETED, transitions to Create custom entity track state. Otherwise, transitions back to Wait for custom entity status (3mins) state. -
Create custom entity track - Gets the entity JSON result, parses and converts the word-offset based results into a timestamp-based metadata results, and stores the JSON results to an S3 proxy bucket.
-
Index custom entity results - Downloads the metadata result and indexes the custom entity results to the OpenSearch Service cluster under the
customentityindex. -
Custom entity skipped - An end state indicates that there is no custom entity being detected.
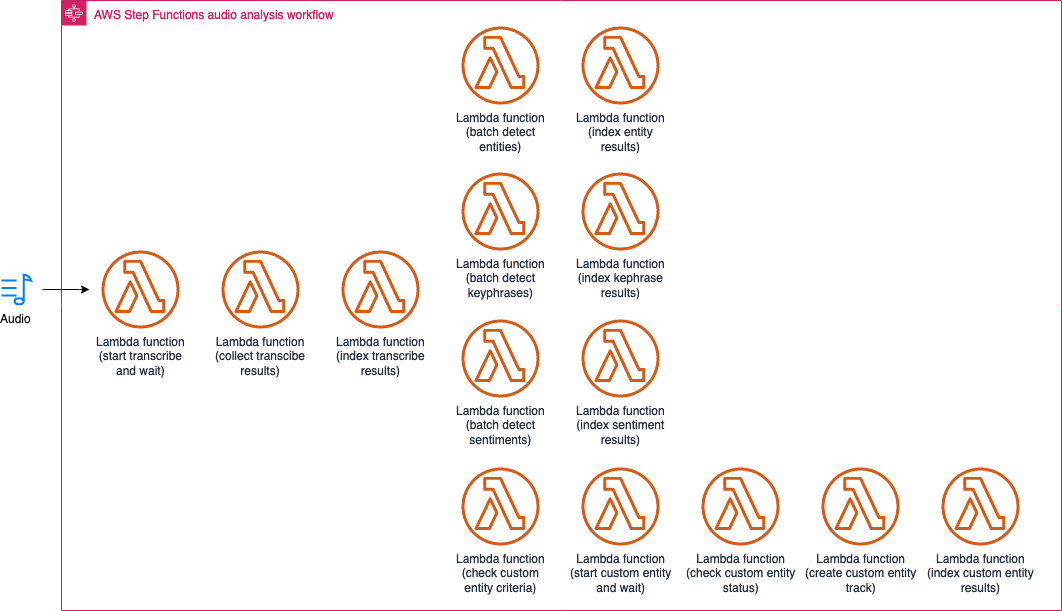
Audio analysis sub-state machine workflow
Image analysis sub-state machine
The image analysis sub-state machine is managed by the analysis state machine. It runs a series of Amazon Rekognition image (synchronized) processes to extract faces, celebrities, labels, moderation, face match, and texts from the video or image file.
Start image analysis - Runs
the Amazon Rekognition Image APIs such as RecognizeCelebrities,
DetectFaces, SearchFacesByImage, DetectLabels,
DetectModerationLabels, and DetectText APIs to extract visual
metadata from the image file and stores raw results to the proxy
bucket:
s3://PROXY_BUCKET/UUID/FILE_BASENAME/raw/DATETIME/rekog-image/ANALYSIS_TYPE/output.json
where ANALYSIS_TYPE is celeb, label, face, faceMatch, text, or moderation.
-
Index analysis results - Indexes all the JSON results to the OpenSearch Service indices.
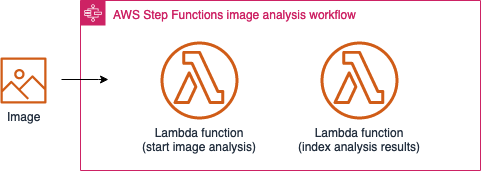
Image analysis sub-state machine workflow
Document analysis sub-state machine
-
Analyze document – Calls the
AnalyzeDocumentAPI to extract tabular metadata of the document and stores the results in an S3 proxy bucket. The process repeats until all pages of the document has been processed or when the Lambda runtime is close to the 15-minute limit. In a case where more pages to be processed and the Lambda is approaching the 15-minute limit, the Lambda function sets $.status to IN_PROGRESS and$.data.cursorto the current page index to prepare for re-entering the same state to continue where it leaves off. -
Index analysis results - Indexes the metadata to the OpenSearch service
textractindex.
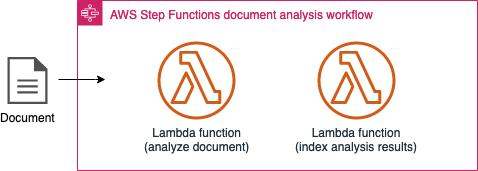
Document analysis sub-state machine workflow
