Creating a vocabulary filter
There are two options for creating a custom vocabulary filter:
-
Save a list of line-separated words as a plain text file with UTF-8 encoding.
You can use this approach with the AWS Management Console, AWS CLI, or AWS SDKs.
If using the AWS Management Console, you can provide a local path or an Amazon S3 URI for your custom vocabulary file.
If using the AWS CLI or AWS SDKs, you must upload your custom vocabulary file to an Amazon S3 bucket and include the Amazon S3 URI in your request.
-
Include a list of comma-separated words directly in your API request.
-
You can use this approach with the AWS CLI or AWS SDKs using the
Wordsparameter.
-
For examples of each method, refer to Creating custom vocabulary filters
Things to note when creating your custom vocabulary filter:
-
Words aren't case sensitive. For example, "curse" and "CURSE" are treated the same.
-
Only exact word matches are filtered. For example, if your filter includes "swear" but your media contains the word "swears" or "swearing", these are not filtered. Only instances of "swear" are filtered. You must therefore include all variations of the words you want filtered.
-
Filters don't apply to words that are contained in other words. For example, if a custom vocabulary filter contains "marine" but not "submarine", "submarine" is not altered in the transcript.
-
Each entry can only contain one word (no spaces).
-
If you save your custom vocabulary filter as a text file, it must be in plain text format with UTF-8 encoding.
-
You can have up to 100 custom vocabulary filters per AWS account and each can be up to 50 Kb in size.
-
You can only use characters that are supported for your language. Refer to your language's character set for details.
Creating custom vocabulary filters
To process a custom vocabulary filter for use with Amazon Transcribe, see the following examples:
Before continuing, save your custom vocabulary filter as a text (*.txt) file. You can optionally upload your file to an Amazon S3 bucket.
-
Sign in to the AWS Management Console
. -
In the navigation pane, choose Vocabulary filtering. This opens the Vocabulary filters page where you can view existing custom vocabulary filters or create a new one.
-
Select Create vocabulary filter.

This takes you to the Create vocabulary filter page. Enter a name for your new custom vocabulary filter.
Select the File upload or S3 location option under Vocabulary input source. Then specify the location of your custom vocabulary file.
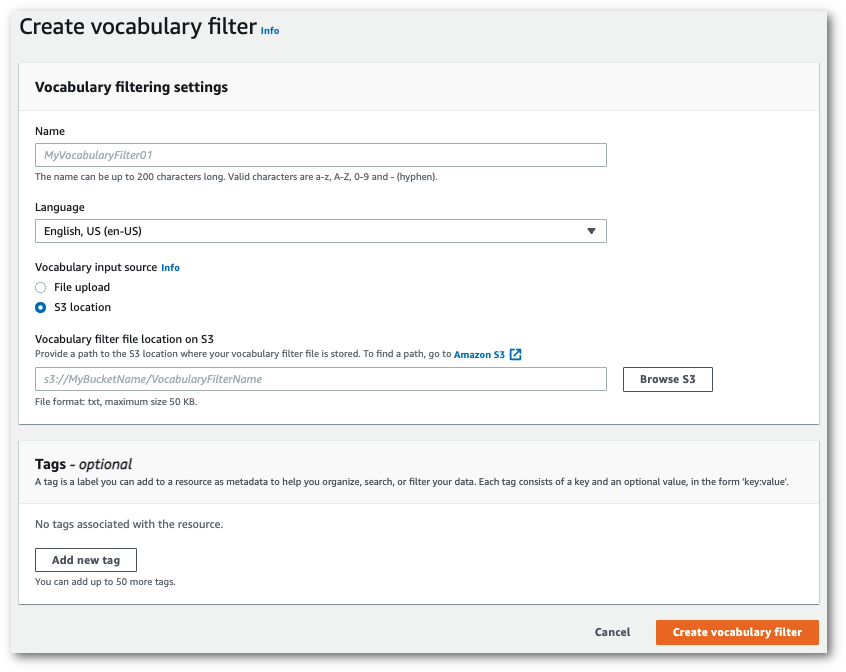
-
Optionally, add tags to your custom vocabulary filter. Once you have all fields completed, select Create vocabulary filter at the bottom of the page. If there are no errors processing your file, this takes you back to the Vocabulary filters page.
Your custom vocabulary filter is now ready to use.
This example uses the create-vocabulary-filter
command to process a word list into a usable custom vocabulary filter. For more information, see
CreateVocabularyFilter.
Option 1: You can include your list of words to your request using
the words parameter.
aws transcribe create-vocabulary-filter \ --vocabulary-filter-namemy-first-vocabulary-filter\ --language-codeen-US\ --wordsprofane,offensive,Amazon,Transcribe
Option 2: You can save your list of words as a text file and upload it to an
Amazon S3 bucket, then include the file's URI in your request using the
vocabulary-filter-file-uri parameter.
aws transcribe create-vocabulary-filter \ --vocabulary-filter-namemy-first-vocabulary-filter\ --language-codeen-US\ --vocabulary-filter-file-uri s3://amzn-s3-demo-bucket/my-vocabulary-filters/my-vocabulary-filter.txt
Here's another example using the create-vocabulary-filter command, and a request body that creates your custom vocabulary filter.
aws transcribe create-vocabulary-filter \ --cli-input-json file://filepath/my-first-vocab-filter.json
The file my-first-vocab-filter.json contains the following request body.
Option 1: You can include your list of words to your request using
the Words parameter.
{ "VocabularyFilterName": "my-first-vocabulary-filter", "LanguageCode": "en-US", "Words": [ "profane","offensive","Amazon","Transcribe" ] }
Option 2: You can save your list of words as a text file and upload it to an
Amazon S3 bucket, then include the file's URI in your request using the
VocabularyFilterFileUri parameter.
{ "VocabularyFilterName": "my-first-vocabulary-filter", "LanguageCode": "en-US", "VocabularyFilterFileUri": "s3://amzn-s3-demo-bucket/my-vocabulary-filters/my-vocabulary-filter.txt" }
Note
If you include VocabularyFilterFileUri in your request, you cannot use
Words; you must choose one or the other.
This example uses the AWS SDK for Python (Boto3) to create a custom vocabulary filter using the
create_vocabulary_filterCreateVocabularyFilter.
For additional examples using the AWS SDKs, including feature-specific, scenario, and cross-service examples, refer to the Code examples for Amazon Transcribe using AWS SDKs chapter.
Option 1: You can include your list of words to your request using
the Words parameter.
from __future__ import print_function import time import boto3 transcribe = boto3.client('transcribe', 'us-west-2') vocab_name = "my-first-vocabulary-filter" response = transcribe.create_vocabulary_filter( LanguageCode = 'en-US', VocabularyFilterName = vocab_name, Words = [ 'profane','offensive','Amazon','Transcribe' ] )
Option 2: You can save your list of words as a text file and upload it to an
Amazon S3 bucket, then include the file's URI in your request using the
VocabularyFilterFileUri parameter.
from __future__ import print_function import time import boto3 transcribe = boto3.client('transcribe', 'us-west-2') vocab_name = "my-first-vocabulary-filter" response = transcribe.create_vocabulary_filter( LanguageCode = 'en-US', VocabularyFilterName = vocab_name, VocabularyFilterFileUri = 's3://amzn-s3-demo-bucket/my-vocabulary-filters/my-vocabulary-filter.txt' )
Note
If you include VocabularyFilterFileUri in your request, you cannot use
Words; you must choose one or the other.
Note
If you create a new Amazon S3 bucket for your custom vocabulary filter files, make sure the
IAM role making the CreateVocabularyFilter
request has permissions to access this bucket. If the role doesn't have the correct permissions, your request
fails. You can optionally specify an IAM role within your request by including the
DataAccessRoleArn parameter. For more information on IAM roles and policies
in Amazon Transcribe, see Amazon Transcribe identity-based policy
examples.
