This whitepaper is for historical reference only. Some content might be outdated and some links might not be available.
Derive insights with moving data around the perimeter
In other situations, you want to move data from one purpose-built data store to another: data movement around-the-perimeter. For example, you may copy the product catalog data stored in your database to your search service to make it easier to look through your product catalog and offload the search queries from the database. We think of this concept as data movement around the perimeter.
Data movement around the perimeter
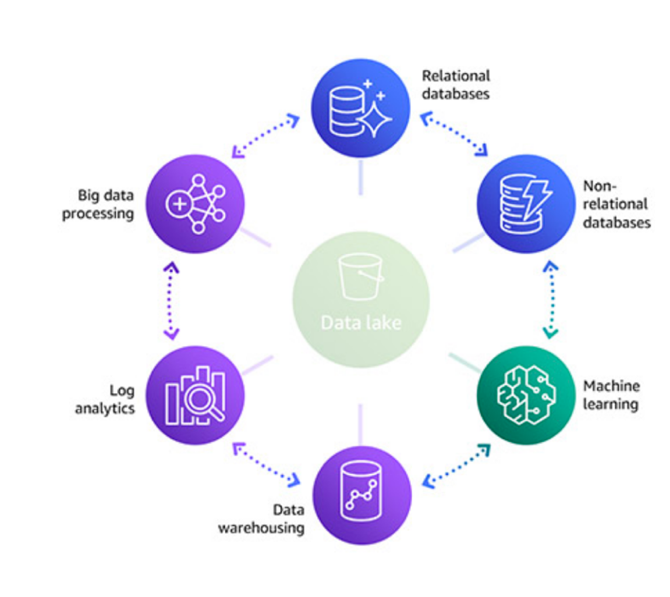
Derive insights from your data lake, data warehouse and operational databases
A data warehouse is a database optimized to analyze relational data coming from
transactional systems and line of business applications. Amazon Redshift
To get information from unstructured data that would not fit in a data warehouse, you
can build a data lake
AWS is launching two new features to help you improve the way you manage your data warehouse and integrate with a data lake:
-
Data Lake Export to unload data from an Amazon Redshift cluster to S3 in Apache Parquet
format, an efficient open columnar storage format optimized for analytics. -
Federated Query to be able, from an Amazon Redshift cluster, to query:
-
Across data stored in the cluster
-
In your S3 data lake
-
In one or more Amazon Relational Database Service
(Amazon RDS) for PostgreSQL and Amazon Aurora PostgreSQL databases
-
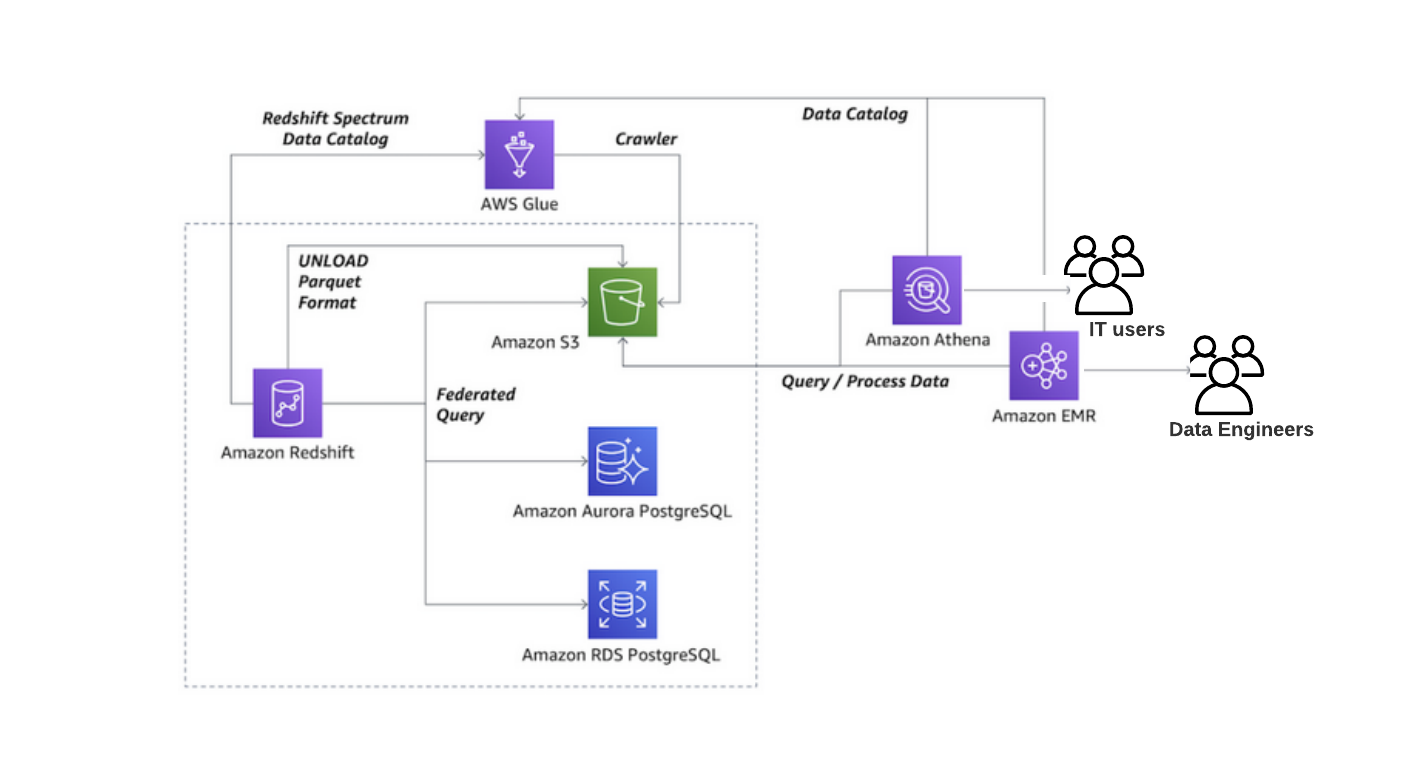
The following diagram illustrates the “moving the data around the perimeter” Modern Data approach with S3, Amazon Redshift, Amazon Aurora PostgreSQL, and Amazon EMR to derive analytics.
Derive insights from your data lake, data warehouse, and operational databases
The steps that data follows through the architecture are as follows:
-
Using the Redshift data lake export — You can unload the result of a Redshift query to an S3 data lake in Apache Parquet format. The Parquet format is up to 2x faster to unload, and consumes up to 6x less storage in S3, compared to text formats. Redshift Spectrum enables you to query data directly from files in S3 without moving data. Or, you can use Amazon Athena
, Amazon EMR , or Amazon SageMaker AI to analyze the data. -
Using the Redshift federated query — You can also access data in Amazon RDS and Aurora PostgreSQL stores directly from your Amazon Redshift data warehouse. In this way, you can access data as soon as it is available. By using federated queries in Amazon Redshift, you can query and analyze data across operational databases, data warehouses, and data lakes.
Refer to the blog post New for Amazon Redshift
– Data Lake Export and Federated Query
Derive insights from your data lake, data warehouse, and purpose-built analytics stores by using Glue Elastic Views
AWS Glue Elastic Views
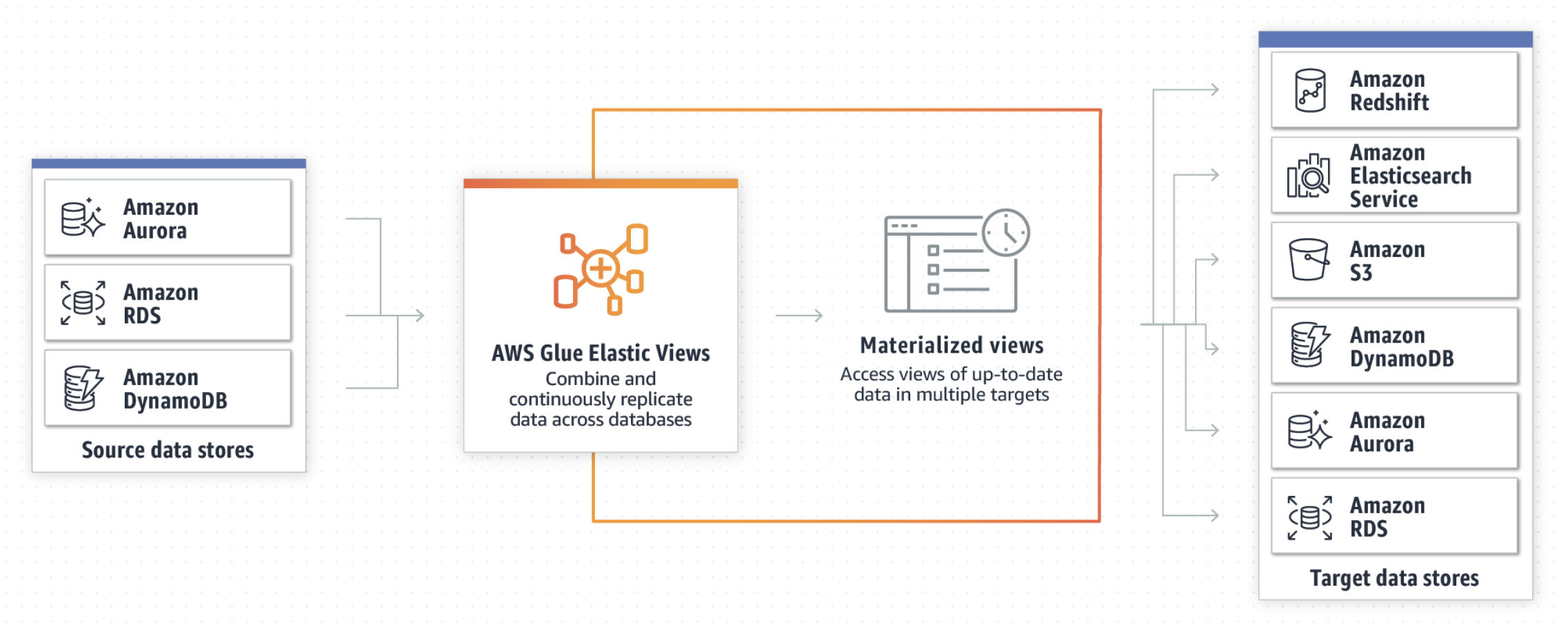
You can just create a view using SQL and pull data out of databases, like DynamoDB or Aurora, and then you can pick a target like Amazon Redshift or Amazon S3 or Elastic Search Service, and all changes will propagate through. You can scale up and down automatically. AWS also monitors that flow of data for any change, so all the error handling and monitoring is no longer your responsibility. It simplifies that data movement across services.
AWS Glue Elastic Views builds on Athena’s federated query capability by making it easier for users to get access to the most up-to-date data while also enabling them to query data wherever it might reside–all using SQL.
The preview of AWS Glue Elastic Views supports DynamoDB and Aurora as sources, and Amazon Redshift and OpenSearch as targets. The goal is for AWS to add more supported sources and destinations over time. It’s also welcoming customers and partners to use the Elastic Views API to add support for their databases and data stores, too.
The following diagram illustrates the “moving the data around the perimeter” Modern Data approach with AWS Glue Elastic Views to derive insights.
Derive insights from your data lake, data warehouse, and purpose-built analytics stores by using AWS Glue Elastic Views
