This whitepaper is for historical reference only. Some content might be outdated and some links might not be available.
Modern data architecture layers deep-dive
Following is an overview of each of the layers in the modern data architecture.
Staging layer

Staging layer of modern data architecture
The staging layer in traditional data
warehouses resided on RDBMS. It was a
schema
on write
In a modern data architecture, the staging layer is represented by the raw layer plus the standardized layer. The raw layer is mainly used to land the data as-is, and is used for audit, exploration, and reproducibility purposes.
Standardized layer
The standardized layer is the interface for
users (data engineers, data scientists, and so on) to explore and
build use cases using raw data that is validated and conforming to
certain defined standards. This layer is a
schema
on read
The challenge of schema evolution
The standardized layer is the interface for self-service BI, exploration and Business as Usual (BAU) data pipelines refreshing the insights on hourly, daily or weekly basis which are used by ML models or business stakeholders to make critical decisions on a day-to-day basis. Consequently, these pipelines need an agreed-upon interface to consistently produce insights with limited issues.
The challenge of schema evolution appears in a data lake due to the schema on read nature of implementation. Typically, in a data lake, the schema is enforced on read. This can make establishing contracts challenging. For example, a data pipeline might use a numeric column to do some calculations. If this column is changed to a string by the source, without notifying the consumer, the pipeline will certainly fail.
To avoid such schema change issues, a standardized layer is recommended. The standardized layer acts as the contract between data producers and consumers. All the data can land in the raw layer, making it an enterprise repository of data for exploration. However, only standardized and harmonized data with schema validation and evolution control is available in the standardized layer. This way, the standardized layer exposes only quality assured data to the consumers.
Schema validation and evolution control assures data consumers that any changes from producers that impact the consumers are flagged, so the data lake administrator can take appropriate actions.
Essentially, schema evolution controls schema drift that is based on the user’s configuration, and should normally be configured so that only compatible changes are propagated further.
Any incompatible changes, flagged in the invalid zone, need to be evaluated by data lake administrators so they can make informed decisions (such as creating a new version of the dataset).
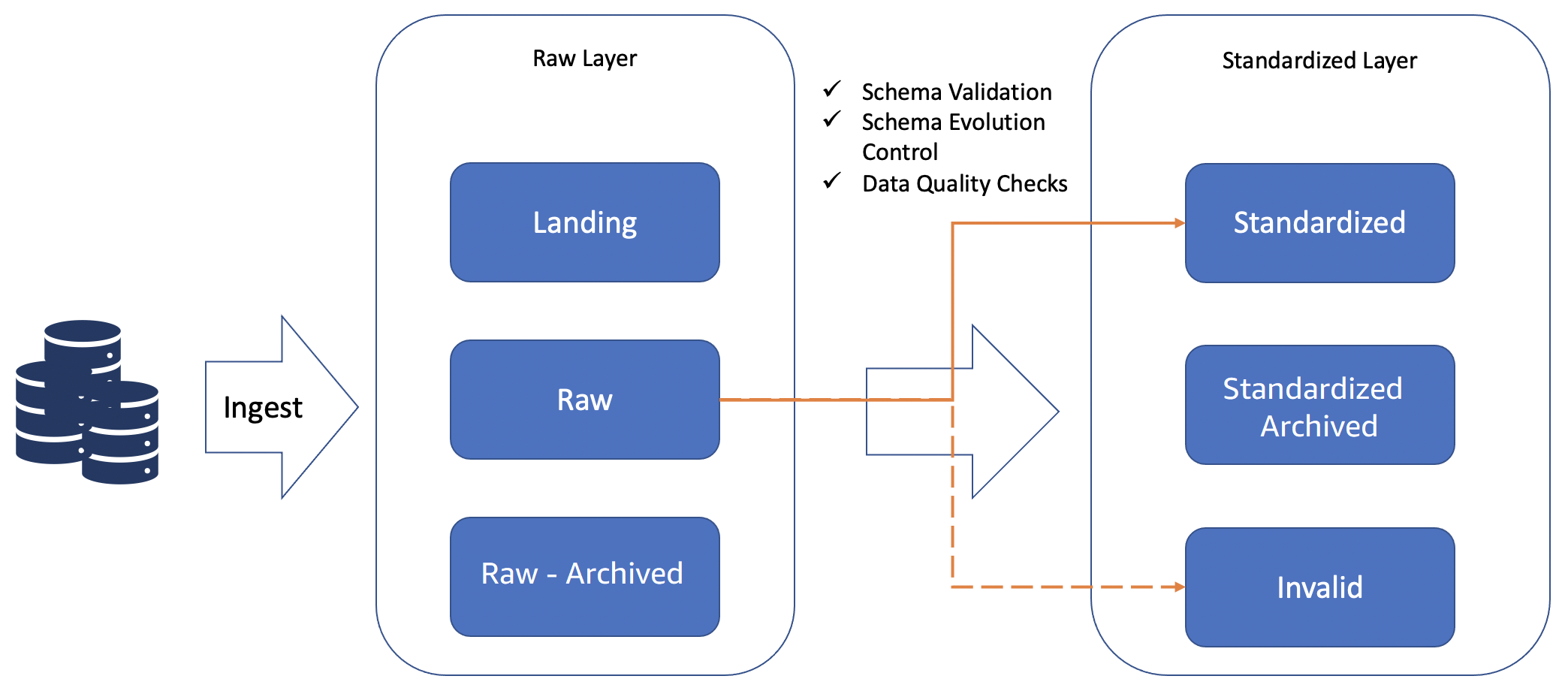
Standardized layer activities
Conformed layer
In general, you can view the conformed layer as a repository of common entities which are well defined and are commonly understood and used across the organization, as explained in the conformed layer description. There are two main patterns to understand:
Centralized pattern
These are common entities and properties (attributes) that are generically used throughout the enterprise. This pattern generally limits the properties of such entities, and can be governed and made centrally available.
For example, in the case of a customer entity, these are generic properties such as name, age, profession, address, and so on. This makes it easier to centrally manage and provide primary data information, especially from a governance point of view (such as PII/PCI management, and lineage and lifecycle management of such sensitive data).

Centralized pattern for conformed layer
In the preceding image, metadata is logged in the central data
catalog and data exchange is governed using the capabilities of
marketplace
Different business units might have additional properties with respect to the customer entity; for example, from a marketing perspective, preferred channels, lifetime value, next best action, customer consent, net promoter score (NPS), and so on. These might be very important properties, but they are only relevant in the bounded context of marketing. Therefore, these properties could be derived and added by the marketing team in their enriched layer from the standardized raw layer. Deriving and managing all properties relevant for each bounded context at the enterprise level centrally often causes a bottleneck and increases time-to-market.
In this pattern, it should be possible to achieve a more denormalized dataset because of the limited number of attributes per entity.
Distributed pattern
Another pattern could be having a conformed layer and enriched layer per business line context, which could be useful in cases of large enterprises where each business line realizes entities which are generic in their context, such as marketing, will focus on customer segments, campaigns, impressions, conversions, and so on, while accounting will focus on orders, sales, revenue, net income, and so on.
This is more distributed conformed layer, which is more domain driven. Because of its distributed nature, you see multiple datasets emerge for the common enterprise entities with properties where different domains are the golden source for specific properties. A way to enable discoverability of these datasets is cataloging the metadata and enabling governance for data exchange using a central data marketplace, with a data catalog and marketplace at its core.

Distributed pattern for conformed layer
In the preceding diagram, the metadata is logged in the central data catalog and data exchange is governed using the capabilities of the marketplace data.
In both patterns, centralized and distributed, the conformed layer is not directly used for operational BI and other applications; however, it can be used for self-service BI, exploration, and analysis.
To maintain the slowly changing nature of such datasets and to optimize performance for both patterns, some suggested approaches follow:
Amazon Redshift-based approach
Based on the patterns discussed in the previous section, Amazon Redshift
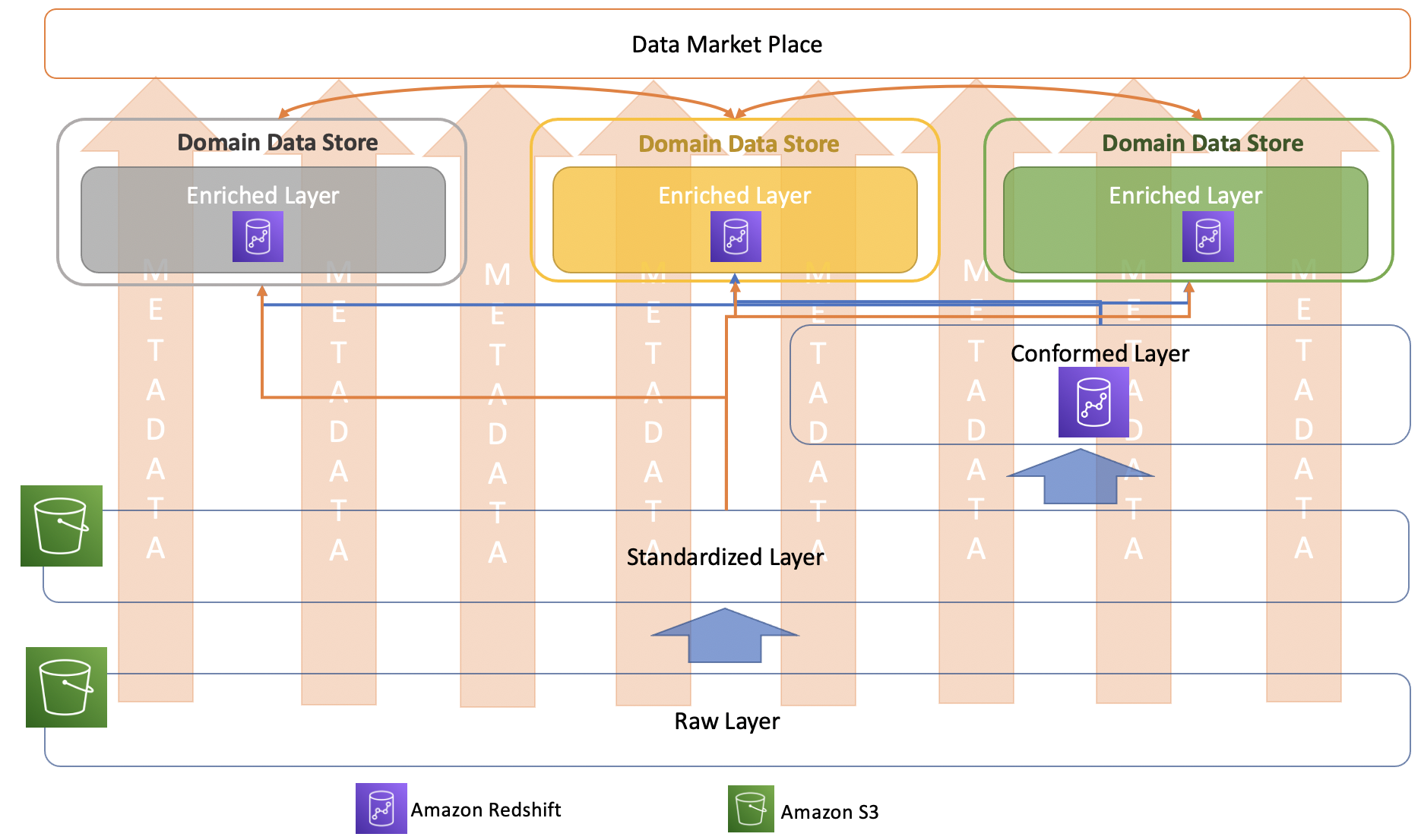
Amazon Redshift approach for conformed layer
AWS Lake Formation governed table approach
The consumers of the conformed layer or enriched layer may use different tools to analyze the data stored in those layers. These consumption patterns vary based on the use case and non-functional requirements. For business intelligence and analytical applications, having a data warehouse solution is suitable; however, for other use cases, such as a customer profile store exposed to online channels, a very low latency NoSQL solution would be more suitable.
One solution won’t typically work for all the use cases. To address this, you can use
the new feature of AWS Lake Formation
AWS Lake Formation has introduced new APIs that support atomic, consistent, isolated, and
durable (ACID) transactions using a new data lake table type, called a governed
table. A governed table allows multiple users to concurrently insert, delete,
and modify rows across tables, while still allowing other users to simultaneously run
analytical queries and ML models on the same datasets that return consistent and
up-to-date results. The ability to update and delete individual rows in governed tables,
like a row (record) of customer data after they have asked to be forgotten, helps users
comply with right to be forgotten provisions in privacy laws like
GDPR
This feature enables the creation of tables in a data lake (Amazon S3) and maintains
history in those tables using slowly changing
dimension
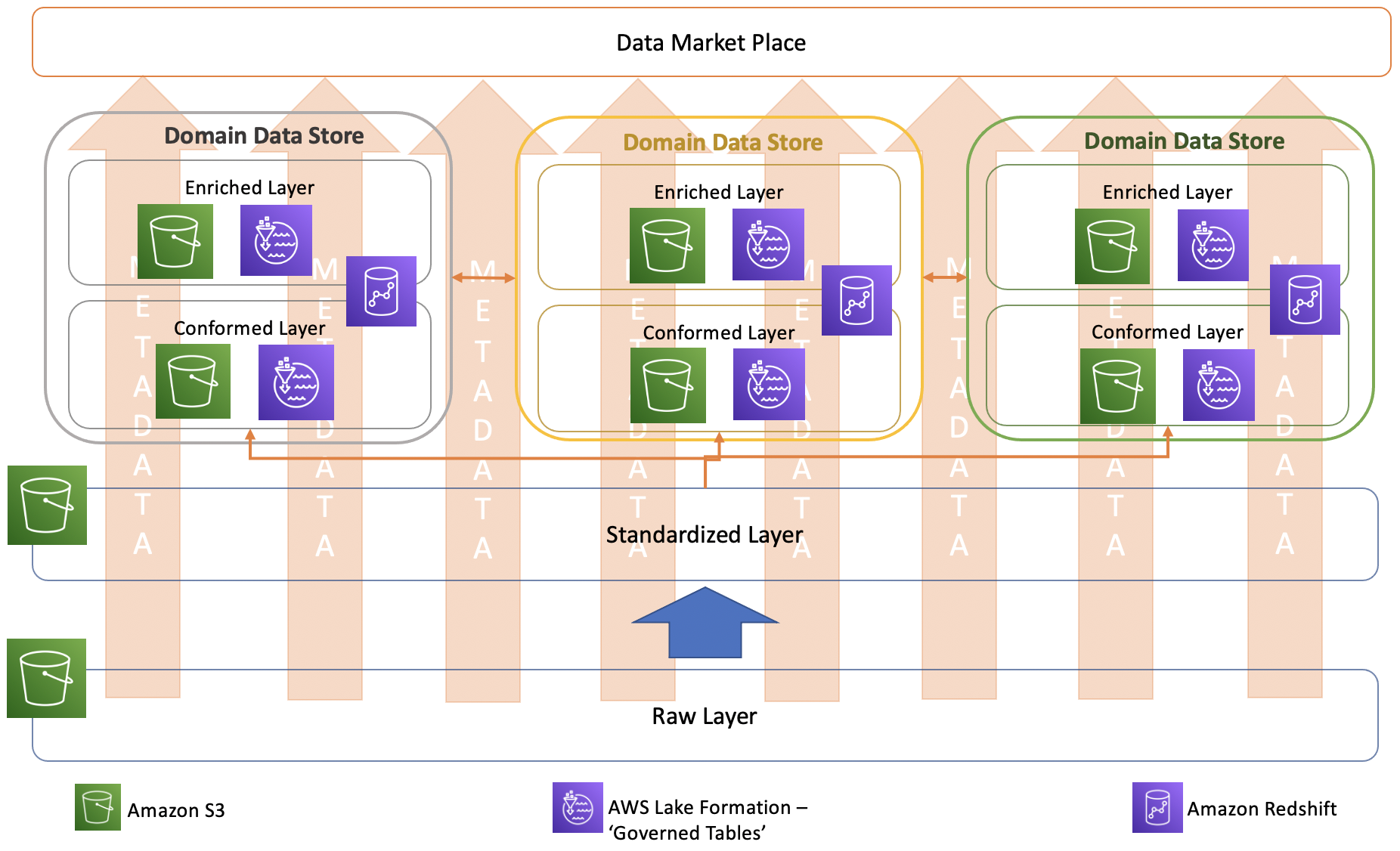
AWS Lake Formation governed tabled approach for conformed layer
Enriched layer
The enriched layer can be seen as the layer which hosts the data product (data set). Depending on the consumption pattern for a use case, an appropriate service can be chosen to host the data to fulfill the non-functional requirements.
This is the final data product used in the business process. For example, it could be a dashboard used to make daily operational decisions or a customer profile with recommendations of products or next-best actions. The datasets can be hosted in different databases or applications, depending on the nonfunctional requirements such as latency, capabilities, scaling needs, and so on.
This data product or data set should be cataloged in the data marketplace for other users to find and request it as needed.
