This whitepaper is for historical reference only. Some content might be outdated and some links might not be available.
Abstract and introduction
Publication date: February 15, 2022 (Document revisions)
Abstract
Today, with the rapid growth in data from ever-expanding data producer platforms, organizations are looking for ways to modernize their data analytics platforms. This whitepaper lays out the traditional analytics approaches and their challenges. It then explains why a modern data architecture is required, and how it helps solve the challenges presented by traditional analytics.
This paper also provides context around how Amazon Web Service (AWS) Cloud analytics services provide a foundation for building this modern data architecture platform.
Introduction
Many large organizations use
enterprise
data warehouses
In contrast, a
data
lake
EDW became popular in the last two decades because of the popularity of using business intelligence (BI) for strategic decision making, as well as for daily operational activities across the organization.
The two most popular approaches to realize a data warehouse over the years have been:
-
Kimball approach – proposed by Ralph Kimball
-
Inmon approach – proposed by Bill Inmon
Enterprise data warehouse
Kimball approach
Ralph Kimball’s view is that data warehouse design is a
bottom-up
This approach suggests gradual building of the data warehouse by
adding new data marts. Data marts are added by adding new
fact
tables
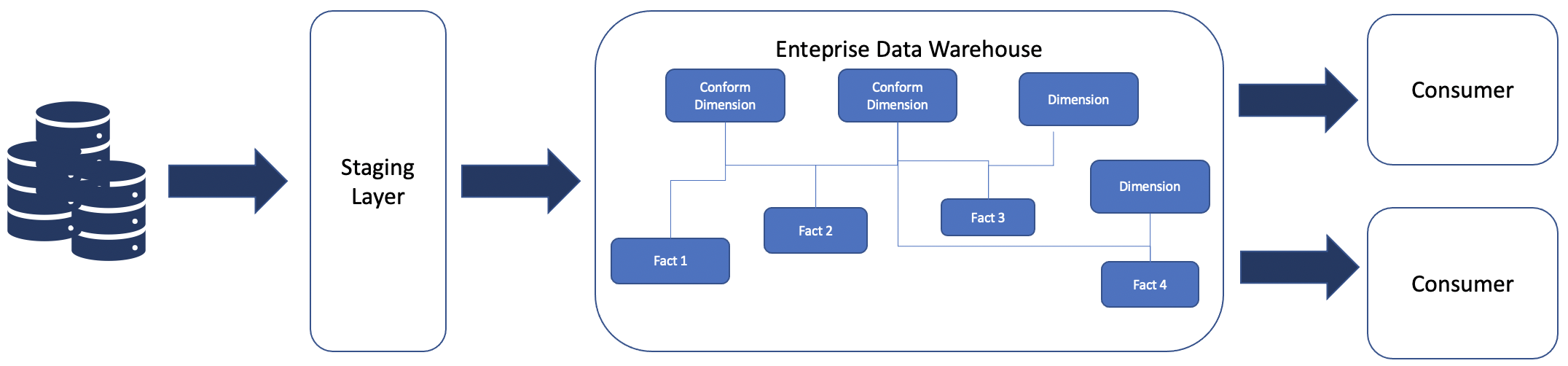
Bottom-up EDW approach
The various combination of dimensions and facts form a logical data mart for a specific business use case.
Benefits:
-
EDW is purpose-built with logical grouping of data marts; EDW is gradually realized based on business use cases and all the data gets stored in EDW.
-
Data is highly denormalized
and redundant, which makes it optimal for analytical purposes with generally better performance. In some cases, a performance layer is also created in terms of physical data marts to achieve optimal performance for use cases such as aggregated reports, trend reports, and time frame reports. -
EDW is easier to understand for non-IT users, because logical data marts are purpose-built subject areas for a particular business domain. It’s easy to create and understand a business metadata layer.
-
EDW is highly suitable for massively parallel processing Relational Database Management Systems (RDBMS), and also suitable for data lake implementations.
Shortcomings:
-
Because EDW is use case driven, creating a fully harmonized integration layer might be difficult to achieve. Data duplication and data sync issues also make this task challenging.
-
Tight coupling with consumers causes delay in changes to mitigate the impact on consumers.
-
The data volume of the tables is high, and this results in heavy and long running extract, transform, and load (ETL) jobs. Additional jobs may be required to get a physical performant layer.
Inmon approach
Bill Inmon proposed a
top-down
According to this approach, data from all the source systems is unified, formatted, type casted, and semantically translated (mapped to the same vocabulary up front). To achieve this, organizations must put in significant amounts of time and effort to define a unified data model to align all the data elements from the source systems.

Top-down EDW approach
Benefits:
-
Highly normalized and no/low data redundancy.
-
Data relationships and granularity is clear with proper semantics.
-
Decoupled from consumers, so it can evolve independently.
-
Optimized for storage and historical data.
-
More suitable for RDBS implementations.
Shortcomings:
-
Data model is complex and data preparation effort is large.
-
Integrated model leads to higher dependency in data sources and reduces parallelism.
-
Third normal form
(3NF) leads to a lot of joins for analysis, making it compute-heavy for doing ad-hoc analysis. -
Most of the time, source data needs to be broken down for the EDW model, and businesses may need to join multiple tables together to derive a final combined dataset across multiple sources.
-
Usually a presentation layer (consisting of multiple data marts) is created on top, which is de-normalized in a star
or snowflake schema for optimal performance for analytical queries. -
Less suitable for data lake implementation.
Because of these reasons and the exponential growth of data in recent years, data warehouses by themselves prove to be less agile and tend to increase the time to market to realize data products in a large organization.
Also, there is an increasing need for organizations to use
several tools on this data to create modern data application,
whereas traditional data warehouse patterns mostly supported
SQL
In recent years, with the advent of cloud and big data tools, organizations are making a shift towards a modern data architecture pattern.
