This whitepaper is for historical reference only. Some content might be outdated and some links might not be available.
Modern data architecture
As technology rapidly evolves, the type and volume of data also grows rapidly. Organizations want to capture all this data and derive value from it as fast as possible, to stay ahead of competition. A data warehouse is a type of data store that caters to a particular type of use case – Online Analytics Processing (OLAP). To meet other types of use cases, such as log analytics, predictive analytics, and big data processing, a one-size-fits-all data strategy creates rough edges and is challenging to scale for future growth.
A modern data architecture gives you the best of both data lakes and purpose-built data stores. It lets you store any amount of data you need at a low cost, and in open, standards-based data formats. It isn’t restricted by data silos, and lets you empower people to run analytics or machine learning (ML) using their preferred tool or technique. Also, it lets you securely manage who has access to the data.
Organizations want to build a better data foundation to:
-
Modernize their data infrastructure.
-
Unify the best of both data lakes and purpose-built data stores.
-
Innovate new experiences and reimagine old processes with AI/ML.
The main features of a modern data architecture are:
-
Scalable, performant and cost-effective.
-
Purpose-built data services.
-
Support for open-data formats.
-
Decoupled storage and compute.
-
Seamless data movements.
-
Support diverse consumption mechanisms.
-
Secure and governed.
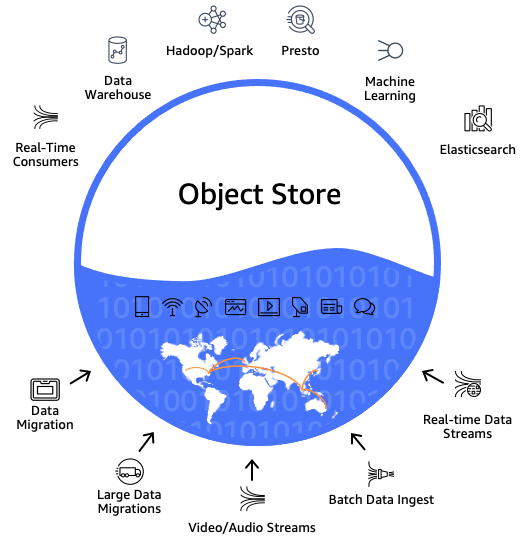
Modern data architecture ecosystem
Before looking into details of the tools that make up a modern data architecture, it’s important to understand the different layers through which the data passes, and the significance of each of these layers.

Data layers of modern data architecture
Raw layer
The raw layer acts as the landing zone for all the source data in the format delivered by the source. The data in this layer can be stored for longer periods of time, and can be archived for audit and reproducibility perspective.
Standardized layer
Because the data that arrives in the raw layer can be in specific
formats as delivered by the source, the standardized
layer is used to store the data in a standard format
(typically Apache Parquet file format) after performing schema
validations, schema evolution control, data quality rules,
tokenization, and cleansing rules for the data. A typical example
of cleansing rule is to standardize the datetime format to a
standard format (for example,
ISO
8601
The data stored in this layer is already optimized for analytical queries, because it is partitioned and stored in columnar format. This data is typically also stored in a central data catalog for discovery.
This layer acts as the consumption layer for standardized raw data in the organization.
Conformed layer
Typically, in any organization, there are some common entities and subject areas which are well defined, and are commonly understood and used across the organization. Such entities can be treated as conformed entities, and end up in the conformed layer.
The definition of these common entities needs to be governed centrally, because they are usually formed based on the primary data of an organization.
The entities in this layer can be created centrally, or the definitions can be created centrally and the operations of loading and maintaining can be delegated to various data engineering teams that need such entities based on a first-come-first-realize basis.
All these entities are also logged in a central data catalog with clear ownership and metadata with respect to Personal Identifiable Information/Payment Card Industry (PII/PCI), retention, purpose, and so on.
One of benefits of managing the conformed entities centrally is clear enterprise ownership. Because this data is used by several parties within the organization, if the ownership is distributed, the definitions can become ambiguous, and maintenance and retention of history, along with governance and data management of these conformed entities, can become challenging.
Enriched layer
The enriched layer is more of a logical layer, because it is aimed at data engineering teams, who create their own data products combining conformed entities and standardized raw data.
Mostly, these business domain-focused teams have many end products that are useful for particular business domains; however, in some cases these could also be products that are useful for other business domains. These are sometimes called golden datasets and can be offloaded to the data lake for sharing across the business.
All the end product datasets in this layer should also be added to the central data catalog with proper labels, metadata, and the purpose of the datasets.
