This whitepaper is for historical reference only. Some content might be outdated and some links might not be available.
Data requirements and transfer for proof of concept (POC)
Once connections have been established with AWS, you should determine what data will be
needed for a proof of concept (POC) and transfer that data to an Amazon Simple Storage Service (Amazon S3)
Once the data has been transferred to an Amazon S3 bucket, you can quickly move data to an
Amazon FSx for Lustre
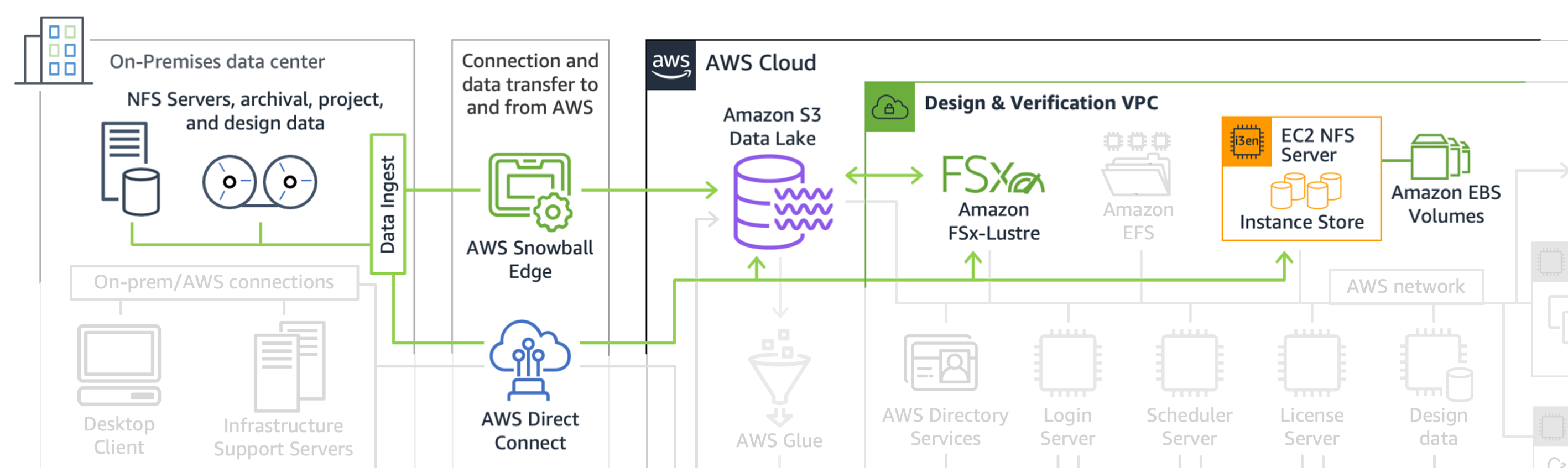
Data requirements and transfer for proof of concept
Note
There are additional services for data transfer that are beyond the scope of this paper,
such as AWS DataSync, and partner solutions. For more information, see Migration & Transfer on
AWS
Use of Amazon S3 data lake
In the preceding figure, the Amazon S3 bucket is shown as an Amazon S3 data lake. A data
lake
Consider what data to move to Amazon S3
Prior to moving your flows to AWS, consider the processes and methods that will be in place as you move from initial experiments, to POC, and then full production.
We encourage customers to start with a relatively small amount of data; for example, only the data required to run a simulation job (hardware description language [HDL] compile and simulation workflow), or a subset of jobs. This approach allows you to quickly gain experience with AWS and build an understanding of how to build production-ready architectures on AWS, while also running an initial chip design workload. Optimization of your flows will come as your knowledge of AWS expands, and you are able to leverage more AWS services.
Data is gravity, and moving only the limited amount of data needed to run your tools to
Amazon S3 allows for flexibly and agility when building and iterating your architecture on AWS.
The S3 transfer speed to an Amazon Elastic Compute Cloud (Amazon EC2) instance is up to 25 Gbps per instance. With
your data stored in Amazon S3, you can quickly experiment with different Amazon EC2
Dependencies
Semiconductor design environments often have complex dependencies that can hinder the
process of moving workflows to AWS. AWS Solutions Architects can work with you to build an
initial POC or even a complex architecture. However, it is often the designer’s or the tool
engineer’s responsibility to identify and optimize any legacy on-premises dependencies. The
initial POC process will require some effort to determine which dependencies, such as shared
libraries, will need to be moved along with project data for a first test. There are tools
available that help you build a list of run-time dependencies, and some of these tools yield
a file manifest that expedites the process of moving data to AWS. For example,
Altair/Ellexus has several tools that can be used to profile applications and determine
dependencies. For more information, see Ellexus on the AWS Marketplace
License sever dependencies and setup can be mitigated by using on-premises license servers while running simple tests on AWS that do not require frequent check outs. However, note that using an on-premises license server while running the job on AWS may adversely affect the run-time. This configuration may only be used temporarily, and for testing only. Having the license server in AWS, with your entire flow, will result in the fastest access to licenses and faster run times.
Dependencies can also include authentication methods (e.g., Active Directory, NIS, LDAP), shared file systems, cross organization collaboration, and globally distributed designs. Identifying and managing such dependencies is not unique to cloud migration; semiconductor design teams face similar challenges in any distributed environment.
Rather than moving an existing workflow, you may avoid a considerable amount of work and launch a net-new semiconductor design and/or verification project on AWS, which should significantly reduce the number of legacy dependencies. For example, you might choose to focus only on one separable part of the flow, such as timing analysis, for your first POC. Or you might choose to test the complete chip design flow, and have the entire project and file dependencies moved to cloud for the duration of the project.
Data management and movement is especially important when migrating and running chip design flows on AWS. It is a critical initial step, that should not be underestimated. Without the data necessary to run even one tool, building out the environment becomes an academic exercise only.
