在 DynamoDB 表中管理多对多关系的最佳实践
相邻列表是一种在 Amazon DynamoDB 中建模多对多关系的设计模式。一般地说,它们提供在 DynamoDB 中表示图表数据(节点和边缘)的方式。
相邻列表设计模式
如果应用程序的不同实体之间具有多对多关系,可以将关系建模为相邻列表。在此模式下,所有顶级实体(与图表模型中的节点同义)都使用分区键表示。将排序键值设置为目标实体 ID(目标节点),可以将与其他实体(图表中的边缘)的任何关系表示为分区内的项目。
此模式的优点包括数据重复率最低,简化查询模式查找与目标实体(边缘作为目标节点)相关的所有实体(节点)。
包含多个账单的开票系统是此模式的一个真实示例。一个账单可以属于多个发票。此示例中的分区键为 InvoiceID 或 BillID。BillID 分区的所有属性特定于账单。InvoiceID 分区的一个项目存储发票特定属性,一个项目保存汇总到发票的每个 BillID。
架构如下所示。
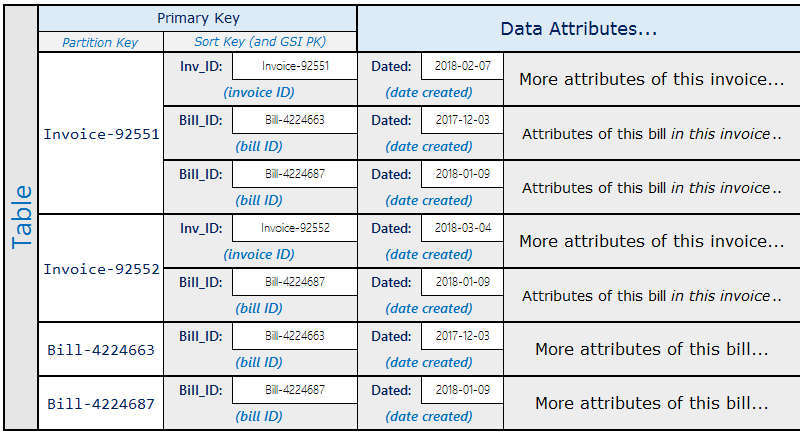
从上述架构可以看到,可以使用表主键查询发票的所有账单。要查找包含一部分账单的所有发票,请对表的排序键创建全局二级索引。
全局二级索引的投影如下所示。
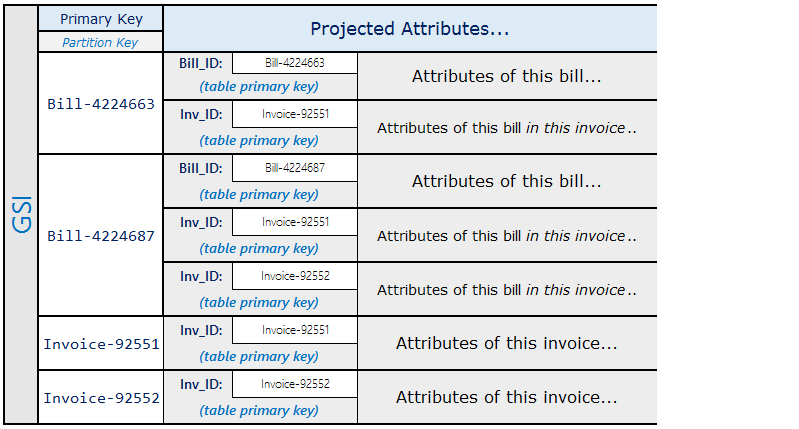
具体化图表模式
很多应用程序建立的基础是在对跨对等排名、实体间关系、相邻实体状态以及其他类型图表样式工作流的了解。对于这些类型的应用程序,考虑下面架构设计模式。
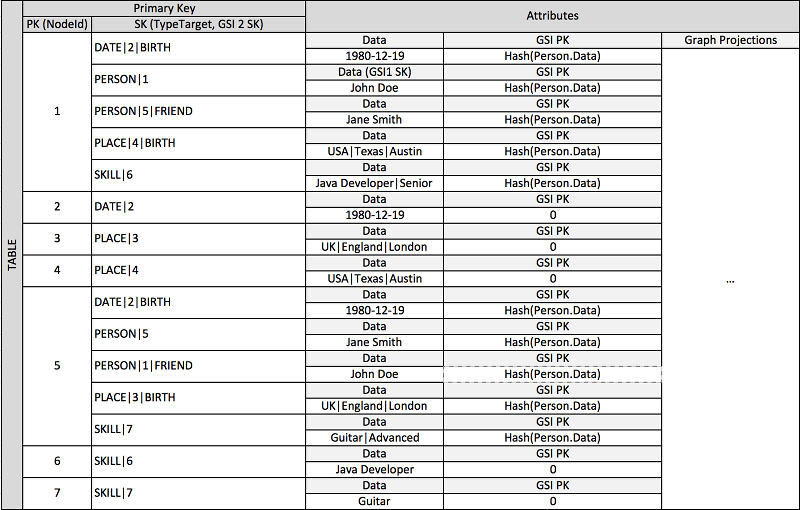
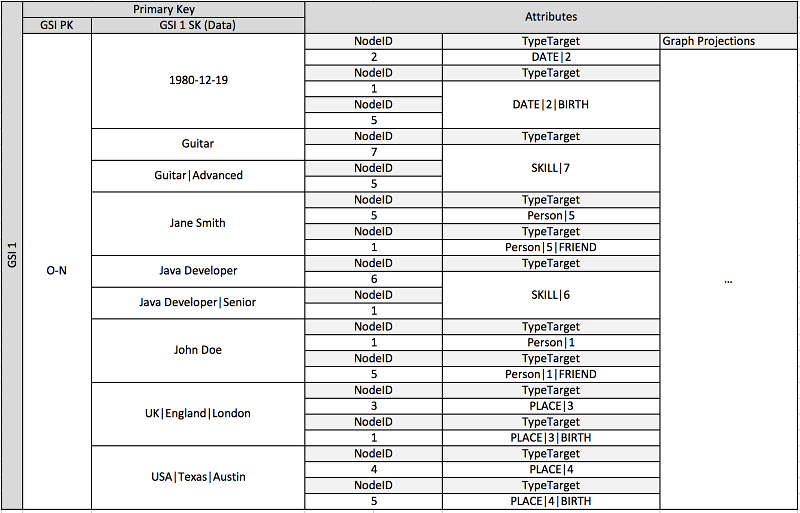
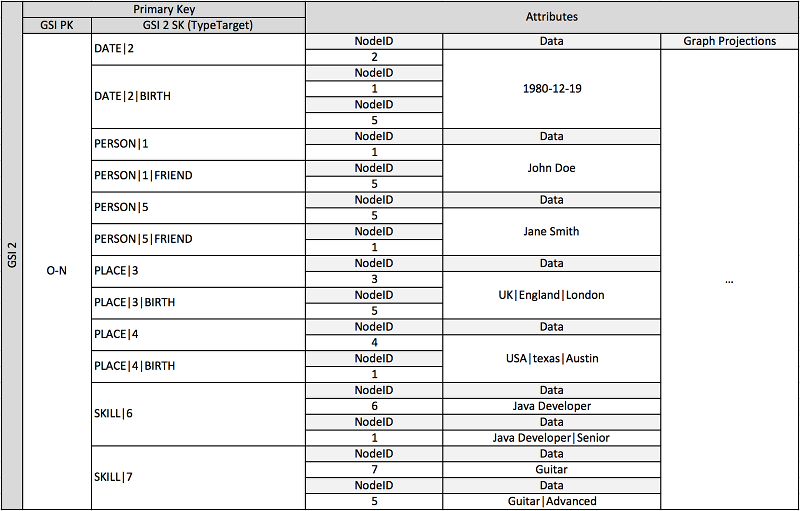
上述架构显示的图表数据结构由一组数据分区定义,包含定义图表边缘和节点的项目。边缘项目包含 Target 和 Type 属性。这些属性用作复合键名称“TypeTarget”的一部分,标识主表分区或另一个全局二级索引中的项目。
第一个全局二级索引基于 Data 属性生成。此属性使用之前介绍的全局二级索引重载,为多个不同属性类型(即 Dates、Names、Places 和 Skills)编制索引。一个全局二级索引可以为四个不同属性有效编制索引。
将项目插入表时,可以使用智能分片策略,在全局二级索引上所需数量的逻辑分区之间,分配包含大型聚合(生日、技能)的项目集,避免热门读取/写入问题。
这种设计模式组合为高效实时图表工作流带来可靠数据存储。这些工作流可以提供高性能相邻实体状态和边缘聚合查询,用于建议引擎、社交网络应用程序、节点排名、子树聚合和其他常见图表使用案例。
如果使用案例对实时数据一致性不敏感,可以使用计划的 Amazon EMR 流程,用工作流相关图表摘要聚合填充边缘。如果将边缘添加到图表后,应用程序不需要立即知道,则可以使用计划流程聚合结果。
要保持一定程度的一致性,此设计可以加入 Amazon DynamoDB Streams 和 AWS Lambda 以处理边缘更新。还可以定期使用 Amazon EMR 任务验证结果。下图说明此方法。常用于社交网络应用程序,实时查询成本高,对立刻知道各个用户更新的需求低。
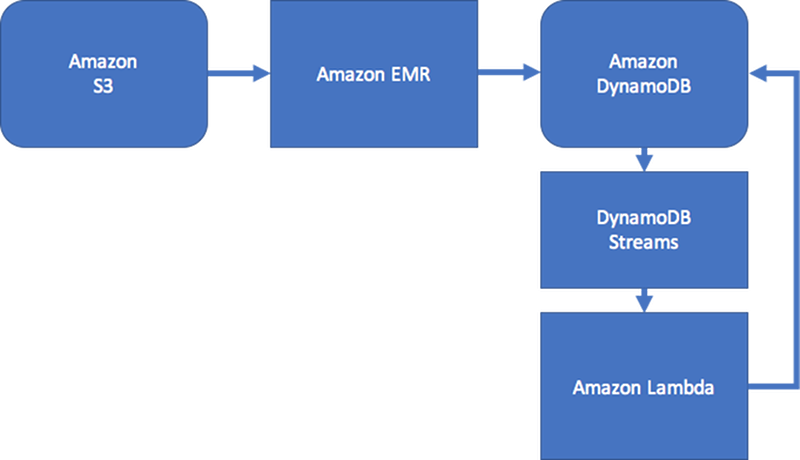
IT 服务管理 (ITSM) 和安全应用程序通常需要实时响应包含复杂边缘聚合的实体状态更改。此类应用程序需要系统可以支持二级和三级关系的实时多个节点聚合或复杂边缘遍历。如果使用案例需要这类实时图表查询工作流,建议考虑使用 Amazon Neptune 管理工作流。
注意
如果您需要查询高度连接的数据集,或者要执行需要以毫秒级延迟遍历多个节点的查询(也称为多跃点查询),则应考虑使用 Amazon Neptune。Amazon Neptune 是一个专门打造的高性能图形数据库引擎,它经过优化,可存储数十亿个关系并能以毫秒级延迟进行图形查询。
