本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
成本优化-联网
架构系统以实现高可用性 (HA) 是实现弹性和容错能力的最佳实践。实际上,这意味着将您的工作负载和底层基础设施分散到给定 AWS 区域的多个可用区 (AZs)。确保您的 Amazon EKS 环境具备这些特性将增强系统的整体可靠性。除此之外,您的 EKS 环境也可能由各种结构(即 VPCs)、组件(即)和集成(即 ECR 和其他容器注册表 ELBs)组成。
高可用性系统和其他特定用例组件的组合可以在数据的传输和处理方式中发挥重要作用。这反过来又会影响数据传输和处理所产生的成本。
下面详细介绍的实践将帮助您设计和优化 EKS 环境,从而实现不同领域和用例的成本效益。
Pod 到 Pod 通信
根据您的设置,Pod 之间的网络通信和数据传输可能会对运行 Amazon EKS 工作负载的总体成本产生重大影响。本节将介绍降低与 pod 间通信相关的成本的不同概念和方法,同时考虑高可用性 (HA) 架构、应用程序性能和弹性。
限制流向可用区的流量
Kubernetes 项目很早就开始开发拓扑感知结构,包括 kubernetes 等标签。 io/hostname, topology.kubernetes.io/region, and topology.kubernetes.io/zone分配给节点以启用诸如跨故障域分配工作负载和拓扑感知卷配置器之类的功能。在 Kubernetes 1.17 中毕业后,这些标签还被用来为 Pod 到 Pod 的通信启用拓扑感知路由功能。
以下是一些策略,说明如何控制 EKS 集群中 Pod 之间的跨可用区流量以降低成本并最大限度地减少延迟。
如果您想详细了解集群中 Pod 之间的跨可用区流量(例如以字节为单位传输的数据量),请参阅这

如上图所示,服务是稳定的网络抽象层,用于接收发往您的 Pod 的流量。创建服务时, EndpointSlices 会创建多个服务。每个端点 EndpointSlice 都有一份端点列表,其中包含 Pod 地址的子集,以及它们正在运行的节点和任何其他拓扑信息。在使用 Amazon VPC CNI 时,kube-proxy(在每个节点上运行的守护进程集)会维护网络规则以启用 Pod 通信和服务发现(基于 EBPF 的替代方案可能不使用 kube-p CNIs roxy 但提供等效行为)。它起到了内部路由的作用,但它是根据它从创建的路由中消耗的资源来实现的。 EndpointSlices
在 EKS 上,kube-proxy 主要使用 iptables NAT 规则(或 IPVS NFTables
使用拓扑感知路由(以前称为拓扑感知提示)
在 Kubernetes 服务上启用和实现拓扑感知路由kube-proxy然后会根据应用的提示将流量从区域路由到终端节点。
下图显示了如何 EndpointSlices 以这样的方式组织提示,即kube-proxy可以根据其区域原点知道它们应该去哪个目的地。如果没有提示,就没有这样的分配或组织,无论流量来自哪里,都会被代理到不同的区域目的地。
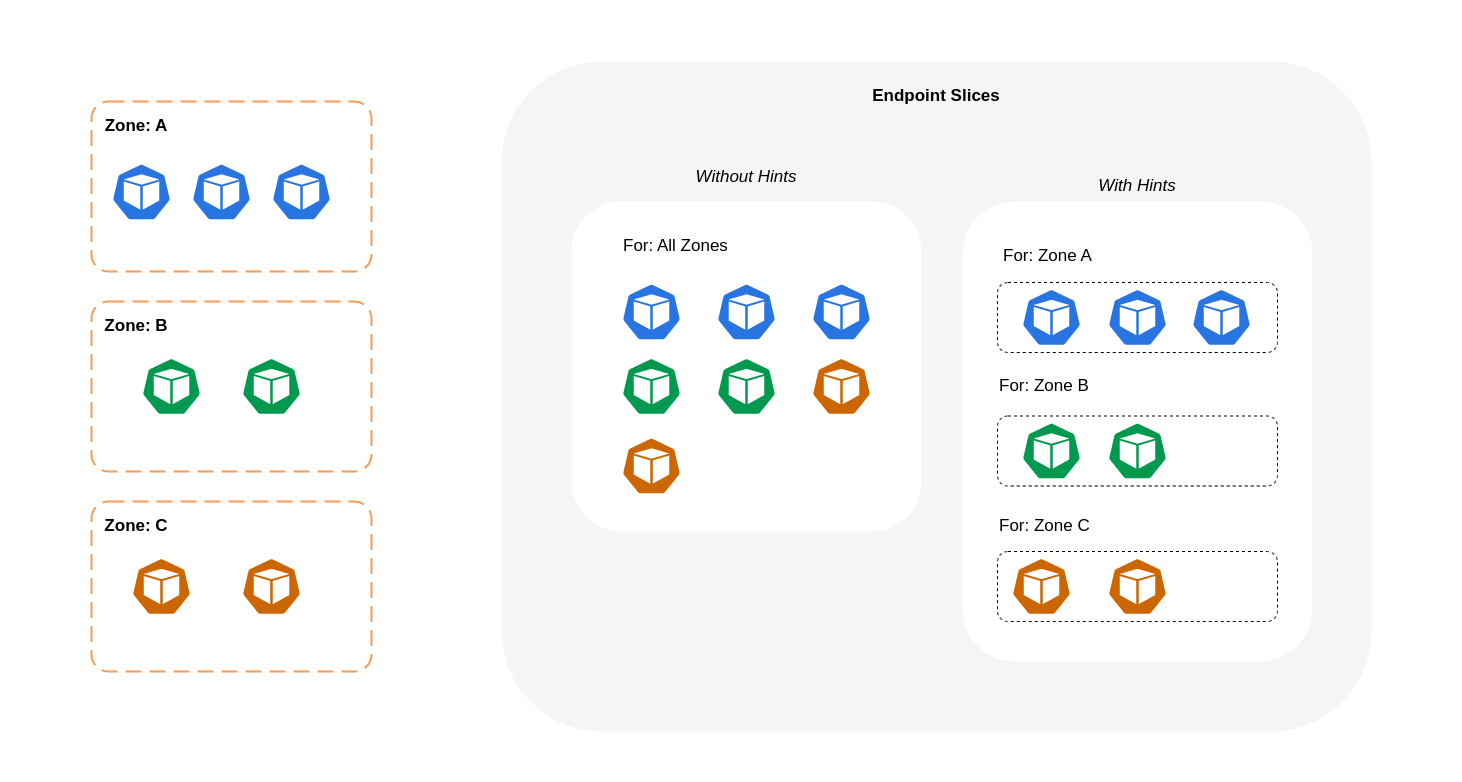
在某些情况下, EndpointSlice 控制器可能会为不同的区域应用提示,这意味着该端点最终可能会为来自不同区域的流量提供服务。这样做的原因是要尝试在不同区域的端点之间保持流量均匀分布。
以下是有关如何为服务启用拓扑感知路由的代码片段。
apiVersion: v1 kind: Service metadata: name: orders-service namespace: ecommerce annotations: service.kubernetes.io/topology-mode: Auto spec: selector: app: orders type: ClusterIP ports: * protocol: TCP port: 3003 targetPort: 3003
下面的屏幕截图显示了 EndpointSlice 控制器成功向在 AZ 中运行的 Pod 副本的终端节点应用提示的结果eu-west-1a。

注意
值得注意的是,拓扑感知路由仍处于测试阶段。在整个集群拓扑结构中均匀分布的工作负载时,此功能的性能更具可预测性,因为控制器在各个区域之间按比例分配端点,但是当区域中的节点资源过于不平衡而无法避免过度过载时,可能会跳过提示分配。因此,强烈建议将其与提高应用程序可用性的调度约束(例如 Pod 拓扑分布限制
使用流量分配
流量分布在 Kubernetes 1.30 中引入,并在 1.33 中正式推出,它为同区域流量偏
以下是有关如何为服务启用流量分配的代码片段。
apiVersion: v1 kind: Service metadata: name: orders-service namespace: ecommerce spec: trafficDistribution: PreferClose selector: app: orders type: ClusterIP ports: * protocol: TCP port: 3003 targetPort: 3003
启用流量分布时,会出现一个常见的难题:如果大多数流量来自同一个区域,则单个可用区内的端点可能会过载。这种重载可能会造成重大问题:
-
管理多可用区部署的单个水平 Pod Autoscaler (HPA) 可以通过跨不同区域扩展 pod 来做出响应。 AZs但是,此操作无法有效解决受影响区域中增加的负载。
-
这种情况反过来会导致资源效率低下。当像 Karpenter 这样的集群自动扩缩器检测到不同的 pod 横向扩展时 AZs,它们可能会在未受影响的 AZs节点中配置其他节点,从而导致不必要的资源分配。
要克服这一挑战,请执行以下操作:
-
为每个区域创建单独的部署,这些部署 HPAs 可以相互独立扩展。
-
利用拓扑分布约束来确保工作负载分布在整个集群中,这有助于防止高流量区域中的端点过载。
使用自动扩缩器:将节点配置到特定的可用区
我们强烈建议您在多个高度可用的环境中运行您的工作负载 AZs。这可以提高应用程序的可靠性,尤其是在可用区出现问题时。如果您愿意为了降低网络相关成本而牺牲可靠性,则可以将节点限制为单个可用区。
要在同一个可用区中运行所有 Pod,要么在同一个可用区中配置工作节点,要么将 Pod 调度到在同一个可用区上运行的工作节点上。要在单个可用区内配置节点,请使用集群自动扩缩器 (topology.kubernetes.io/zone并指定要在其中创建工作节点的可用区。例如,下面的 Karpenter 配置程序片段配置了 us-west-2a AZ 中的节点。
Karpenter
apiVersion: karpenter.sh/v1 kind: Provisioner metadata: name: single-az spec: requirements: * key: "topology.kubernetes.io/zone"` operator: In values: ["us-west-2a"]
集群自动扩缩器 (CA)
apiVersion: eksctl.io/v1alpha5 kind: ClusterConfig metadata: name: my-ca-cluster region: us-east-1 version: "1.21" availabilityZones: * us-east-1a managedNodeGroups: * name: managed-nodes labels: role: managed-nodes instanceType: t3.medium minSize: 1 maxSize: 10 desiredCapacity: 1 ...
使用 Pod 分配和节点亲和性
或者,如果您有多个 AZs工作节点运行,则每个节点的标签都将标有 topology.kubernetes.io/zone 以及其可用区的值(例如 us-nodeSelector或将 Pod 调度nodeAffinity到单个可用区中的节点。例如,以下清单文件会将 Pod 调度到在 AZ us-west-2a 中运行的节点内。
apiVersion: v1 kind: Pod metadata: name: nginx labels: env: test spec: nodeSelector: topology.kubernetes.io/zone: us-west-2a containers: * name: nginx image: nginx imagePullPolicy: IfNotPresent
限制流向节点的流量
在某些情况下,仅在区域级别限制流量是不够的。除了降低成本外,您可能还需要减少某些具有频繁互通信功能的应用程序之间的网络延迟。为了实现最佳网络性能并降低成本,您需要一种方法来限制特定节点的流量。例如,即使在高可用性 (HA) 设置中,微服务 A 也应始终在节点 1 上与微服务 B 通信。让节点 1 上的微服务 A 与节点 2 上的微服务 B 通信可能会对这种性质的应用程序的预期性能产生负面影响,尤其是在节点 2 完全位于单独的可用区时。
使用服务内部流量策略
为了限制流向节点的 Pod 网络流量,你可以使用服务内部流量策略Local时,流量将仅限于流量来源节点上的端点。此政策规定只能使用节点本地端点。这意味着,该工作负载的网络流量相关成本将低于分布在集群范围内的成本。此外,延迟会降低,从而提高应用程序的性能。
注意
需要注意的是,此功能不能与 Kubernetes 中的拓扑感知路由结合使用。

以下是有关如何为服务设置内部流量策略的代码片段。
apiVersion: v1 kind: Service metadata: name: orders-service namespace: ecommerce spec: selector: app: orders type: ClusterIP ports: * protocol: TCP port: 3003 targetPort: 3003 internalTrafficPolicy: Local
为避免应用程序因流量下降而出现意外行为,应考虑以下方法:
-
为每个通信的 Pod 运行足够的副本
-
使用拓扑分布约束让 Pod 分布
相对均匀 -
利用 pod 关联性规则对通信 Pod
进行同地定位
在此示例中,您有 2 个微服务 A 副本和 3 个微服务 B 副本。如果微服务 A 的副本分布在节点 1 和节点 2 之间,而微服务 B 的 3 个副本全部位于节点 3 上,则由于内部流量策略,它们将无法通信。Local当没有可用的节点本地端点时,流量将被丢弃。

如果微服务 B 的 3 个副本中的 2 个位于节点 1 和 2 上,则对等应用程序之间将进行通信。但是你仍然会有一个微服务 B 的隔离副本,没有任何对等副本可以与之通信。

注意
在某些情况下,如果像上图所示的孤立副本仍有用途(例如处理来自外部传入流量的请求),则可能不会引起担忧。
使用具有拓扑分布约束的服务内部流量策略
将内部流量策略与拓扑分布限制结合使用可能有助于确保您拥有正确数量的副本,以便在不同节点上通信微服务。
apiVersion: apps/v1 kind: Deployment metadata: name: express-test spec: replicas: 6 selector: matchLabels: app: express-test template: metadata: labels: app: express-test tier: backend spec: topologySpreadConstraints: - maxSkew: 1 topologyKey: "topology.kubernetes.io/zone" whenUnsatisfiable: ScheduleAnyway labelSelector: matchLabels: app: express-test
将服务内部流量策略与 Pod 关联性规则配合使用
另一种方法是在使用服务内部流量策略时使用 Pod 关联性规则。借助 Pod 亲和性,你可以影响调度器将某些 Pod 放在同一个位置,因为它们经常通信。通过对某些 Pod 应用严格的调度约束 (requiredDuringSchedulingIgnoredDuringExecution),当调度器将 Pod 放在节点上时,这将为你提供 Pod 托管的更好结果。
apiVersion: apps/v1 kind: Deployment metadata: name: graphql namespace: ecommerce labels: app.kubernetes.io/version: "0.1.6" ... spec: serviceAccountName: graphql-service-account affinity: podAffinity: requiredDuringSchedulingIgnoredDuringExecution: - labelSelector: matchExpressions: - key: app operator: In values: - orders topologyKey: "kubernetes.io/hostname"
Load Balancer 到 Pod 通信
EKS 工作负载通常由负载均衡器前置,该负载均衡器将流量分配到 EKS 集群中的相关 Pod。您的架构可能包括面向 and/or 外部的内部负载均衡器。根据您的架构和网络流量配置,负载均衡器与 Pod 之间的通信可能会导致大量的数据传输费用。
您可以使用 AWS Load Balancer 控制器
使用实例模式时, NodePort 将在您的 EKS 集群中的每个节点上打开。然后,负载均衡器将均匀地代理节点间的流量。如果节点上运行了目标 Pod,则不会产生数据传输费用。但是,如果目标 Pod 与 NodePort 接收流量的 Pod 位于不同的节点和不同的可用区中,则从 kube-proxy 到目标 Pod 将有额外的网络跳跃。在这种情况下,将收取跨可用区数据传输费用。由于流量分布均匀,从 kube-proxy 到相关目标 Pod 的跨区域网络流量跳跃很可能会产生额外的数据传输费用。
下图描绘了流量从负载均衡器流向另一可用区中单独节点上的目标 Pod NodePort,然后从负载均衡器流kube-proxy向目标 Pod 的网络路径。这是实例模式设置的示例。
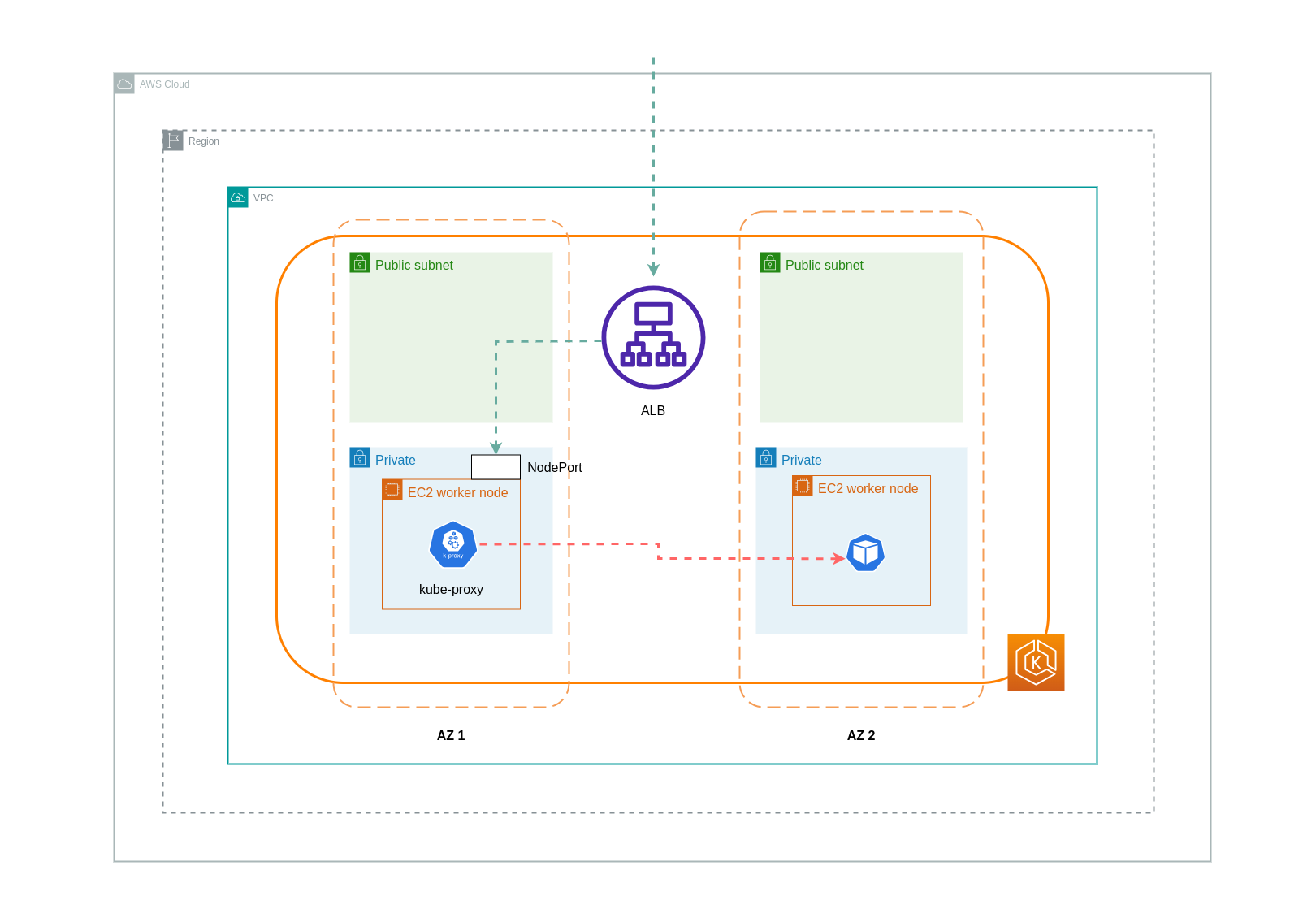
使用 IP 模式时,网络流量会直接从负载均衡器代理到目标 Pod。因此,这种方法不涉及数据传输费用。
注意
建议您将负载均衡器设置为 IP 流量模式,以降低数据传输费用。在此设置中,确保您的负载均衡器部署在您的 VPC 中的所有子网中也很重要。
下图描绘了在网络 IP 模式下从负载均衡器流向 Pod 的流量的网络路径。

从容器注册表传输数据
Amazon ECR
向 Amazon ECR 私有注册表传输数据是免费的。区域内数据传输不产生任何费用,但传输到互联网和跨区域的数据传输将按传输双方的互联网数据传输费率收费。
您应该利用 ECRs 内置的映像复制功能将相关的容器镜像复制到与您的工作负载相同的区域。这样,复制只需支付一次费用,并且所有相同的区域(区域内)图像拉取都将是免费的。
通过使用接口 VPC 终端节点连接到区域内 ECR 存储库,可以进一步降低与从 ECR 提取映像(数据传出)相关的数据传输成本。连接到 ECR 的公有 AWS 终端节点(通过 NAT 网关和 Internet Gateway)的替代方法将产生更高的数据处理和传输成本。下一节将更详细地介绍如何降低您的工作负载和 AWS 服务之间的数据传输成本。
如果您运行的工作负载包含特别大的映像,则可以使用预先缓存的容器映像构建自己的自定义 Amazon 系统映像 (AMIs)。这可以减少初始映像提取时间和从容器注册表到 EKS 工作节点的潜在数据传输成本。
将数据传输到互联网和 AWS 服务
通过互联网将 Kubernetes 工作负载与其他 AWS 服务或第三方工具和平台集成,这是一种常见的做法。用于将流量路由到相关目的地的底层网络基础设施可能会影响数据传输过程中产生的成本。
使用 NAT 网关
NAT 网关是执行网络地址转换 (NAT) 的网络组件。下图描绘了 EKS 集群中的 Pod 与其他 AWS 服务(亚马逊 ECR、DynamoDB 和 S3)和第三方平台通信。在此示例中,Pod 分别 AZs在私有子网中运行。为了发送和接收来自互联网的流量,需要将 NAT 网关部署到一个可用区的公有子网中,从而允许任何具有私有 IP 地址的资源共享一个公有 IP 地址来访问互联网。反过来,此 NAT 网关与 Internet Gateway 组件通信,允许将数据包发送到其最终目的地。
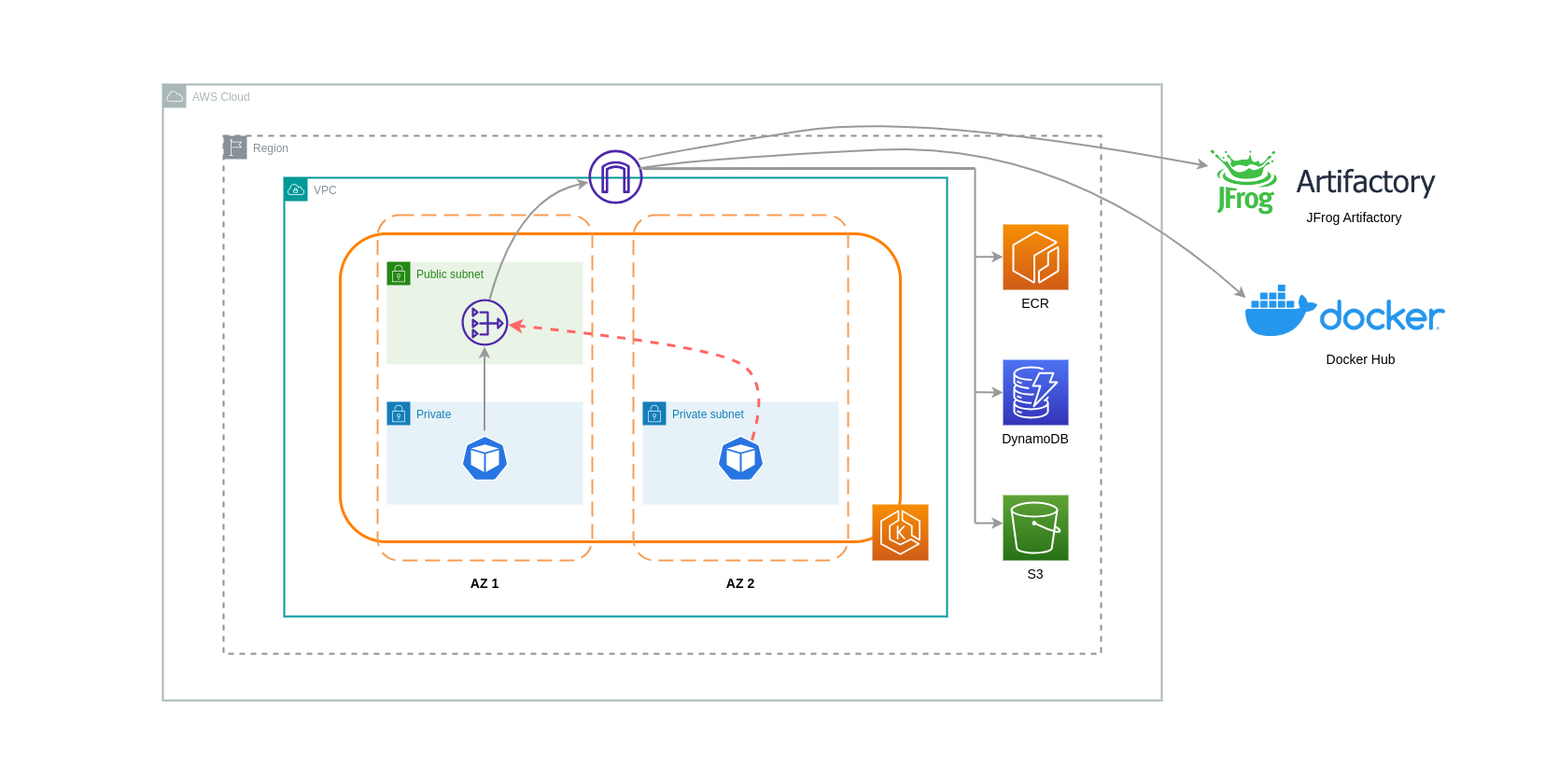
在此类用例中使用 NAT 网关时,您可以通过在每个可用区部署一个 NAT 网关来最大限度地降低数据传输成本。这样,路由到互联网的流量将通过同一可用区中的 NAT 网关,从而避免可用区间的数据传输。但是,尽管您可以节省可用区间数据传输的成本,但这种设置的含义是,您的架构中会产生额外的 NAT 网关的成本。
这种推荐的方法如下图所示。

使用 VPC 终端节点
为了进一步降低此类架构的成本,您应该使用 VPC 终端节点在工作负载和 AWS 服务之间建立连接。VPC 终端节点允许您从 VPC 内部访问 AWS 服务,无需 data/network 数据包通过互联网。所有流量均为内部流量并保持在 AWS 网络内。VPC 终端节点有两种类型:接口 VPC 终端节点(受许多 AWS 服务支持)和网关 VPC 终端节点(仅受 S3 和 DynamoDB 支持)。
网关 VPC 终端节点
网关 VPC 终端节点不收取每小时费用或数据传输费用。使用网关 VPC 终端节点时,请务必注意,它们不能跨越 VPC 边界扩展。它们不能用于 VPC 对等互连、VPN 网络或通过 Direct Connect。
接口 VPC 终端节点
VPC 终端节点按小时收费
下图显示了通过 VPC 终端节点与 AWS 服务通信的 Pod。

之间的数据传输 VPCs
在某些情况下,您的工作负载可能位于不同的 VPCs (在同一 AWS 区域内),需要相互通信。这可以通过允许流量通过连接到相应 VPCs网关的互联网网关穿过公共互联网来实现。可以通过在公有子网中部署基础架构组件(如 EC2 实例、NAT 网关或 NAT 实例)来启用此类通信。但是,包含这些组件的设置将产生 processing/transferring 数据进出 VPCs费用。如果进出分开的流量 VPCs 正在流过 AZs,则数据传输将额外收费。下图描绘了一种使用 NAT 网关和 Internet 网关在不同 VPCs工作负载之间建立通信的设置。

VPC 对等连接
要降低此类用例的成本,您可以使用 VPC 对等连接。使用 VPC 对等连接时,停留在同一可用区内的网络流量无需支付数据传输费用。如果交通过境 AZs,则会产生费用。不过,建议使用 VPC 对等互连方法,以便在同一 AWS 区域 VPCs 内的不同工作负载之间进行经济高效的通信。但是,需要注意的是,VPC 对等互连主要对 1:1 VPC 连接有效,因为它不允许传输网络。
下图是通过 VPC 对等连接进行工作负载通信的高级表示。

可传递网络连接
如上一节所述,VPC 对等连接不允许传输网络连接。如果您想根据过渡网络要求连接 3 个或更多个 VPCs ,则应使用 T ransit Gateway (TGW)。这将使您能够克服 VPC 对等互连的限制或与在多个 VPC 对等连接之间建立多个 VPC 对等连接相关的任何运营开销。 VPCs您按小时计费,并按
下图显示了不同 VPCs 但位于相同 AWS 区域内的不同工作负载之间通过 TGW 的可用区间流量。
使用服务网格
服务网格提供强大的联网功能,可用于降低 EKS 集群环境中的网络相关成本。但是,如果您采用服务网格,则应仔细考虑服务网格会给您的环境带来的操作任务和复杂性。
限制流向可用区的流量
使用 Istio 的局部加权分布
Istio 使您能够在路由发生后将网络策略应用于流量。这是使用目的地规则
上面详述的 Istio 目标规则也可以应用于管理从负载均衡器到 EKS 集群中 Pod 的流量。本地加权分配规则可以应用于从高可用性负载均衡器(特别是 Ingress Gateway)接收流量的服务。这些规则允许您根据其区域来源(在本例中为负载均衡器)来控制流量流向何处。如果配置正确,与将流量均匀或随机分配到不同的 Pod 副本的负载均衡器相比,跨区域的出口流量将更少。 AZs
以下是 Istio 中目标规则资源的代码块示例。如下所示,该资源为来自该区域 3 个不同 AZs eu-west-1地区的传入流量指定了加权配置。这些配置声明,来自给定可用区的大部分传入流量(在本例中为 70%)应代理到其来源的同一个可用区中的目的地。
apiVersion: networking.istio.io/v1beta1 kind: DestinationRule metadata: name: express-test-dr spec: host: express-test.default.svc.cluster.local trafficPolicy: loadBalancer: + localityLbSetting: distribute: - from: eu-west-1/eu-west-1a/ + to: "eu-west-1/eu-west-1a/_": 70 "eu-west-1/eu-west-1b/_": 20 "eu-west-1/eu-west-1c/_": 10 - from: eu-west-1/eu-west-1b/_ + to: "eu-west-1/eu-west-1a/_": 20 "eu-west-1/eu-west-1b/_": 70 "eu-west-1/eu-west-1c/_": 10 - from: eu-west-1/eu-west-1c/_ + to: "eu-west-1/eu-west-1a/_": 20 "eu-west-1/eu-west-1b/_": 10 "eu-west-1/eu-west-1c/*": 70** connectionPool: http: http2MaxRequests: 10 maxRequestsPerConnection: 10 outlierDetection: consecutiveGatewayErrors: 1 interval: 1m baseEjectionTime: 30s
注意
可以分配到目的地的最小权重为 1%。这样做的原因是为了维护故障转移区域和区域,以防主目标中的终端节点运行状况不佳或不可用。
下图描绘了一个场景,其中 eu -west-1 区域中有一个高可用性负载均衡器,并应用了地区加权分布。此图表的目标规则策略配置为将来自 eu-west-1a 的流量的 60% 发送到同一个可用区中的 Pod,而来自 e u-west-1a 的流量中有 40% 应发送到 e u-west- 1b 中的 Pod。

限制流向可用区和节点的流量
在 Istio 中使用服务内部流量策略
为了降低与外部传入流量和 Pod 之间的内部流量相关的网络成本,您可以将 Istio 的目标规则和 Kubernetes 服务内部流量策略结合起来。将 Istio 目标规则与服务内部流量策略相结合的方法在很大程度上取决于三件事:
-
微服务的作用
-
跨微服务的网络流量模式
-
如何在 Kubernetes 集群拓扑中部署微服务
下图显示了嵌套请求情况下的网络流会是什么样子,以及上述策略将如何控制流量。

-
最终用户向应用程序 A 发出请求,而应用程序 A 又向 AP C 发出嵌套请求。 该请求首先发送到高可用性负载均衡器,该负载均衡器在可用区 1 和可用区 2 中都有实例,如上图所示。
-
然后,Istio 虚拟服务会将外部传入的请求路由到正确的目的地。
-
请求被路由后,Istio 目标规则 AZs 根据请求的来源(AZ 1 或 AZ 2)控制流向相应请求的流量。
-
然后,流量会进入应用程序 A 的服务,然后被代理到相应的 Pod 端点。如图所示,80% 的传入流量发送到可用区 1 中的 Pod 终端节点,20% 的传入流量发送到可用区 2。
-
然后,应用程序 A 向应用程序 C 发出内部请求。 APP C 的服务启用了内部流量策略 (
internalTrafficPolicy`: Local`)。 -
由于 APP C 有可用的节点本地端点,因此从 APP A(在节点 1 上)向 AP P C 发出的内部请求是成功的。
-
从应用程序 A(在节点 3 上)向 APP C 发出的内部请求失败,因为 AP P C 没有可用的节点本地端点。 如图所示,应用程序 C 在 NODE 3 上没有副本。 *
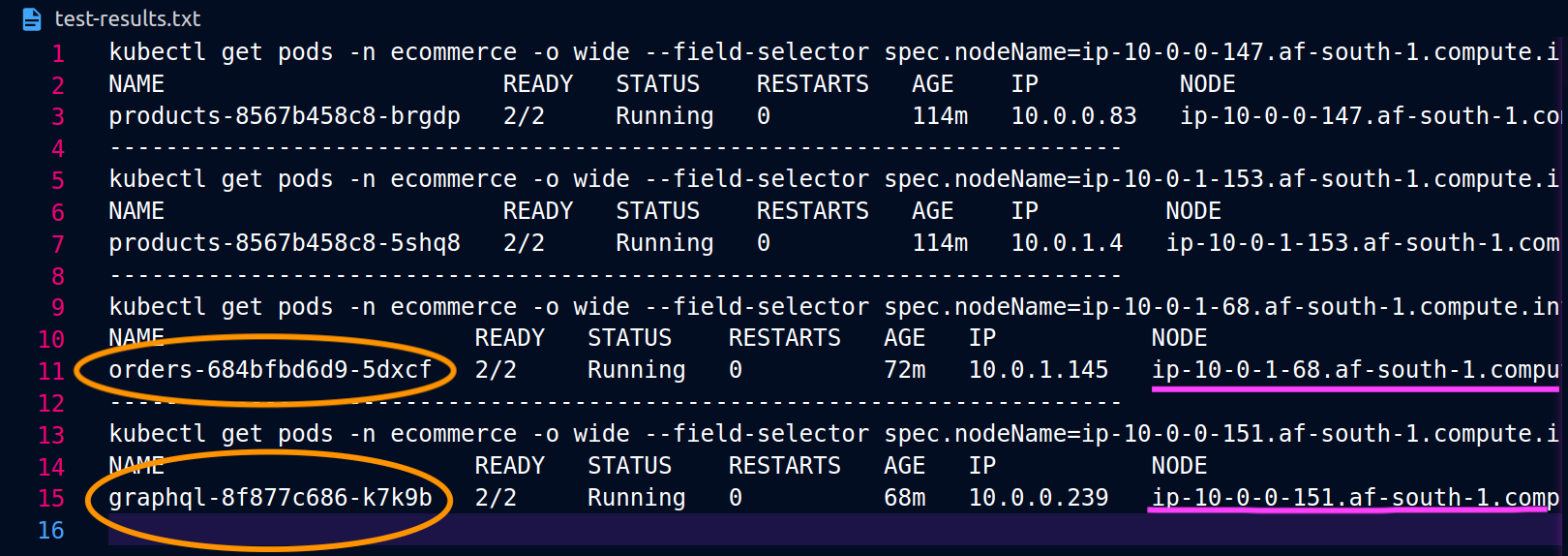
以下屏幕截图是从这种方法的真实示例中截取的。第一组屏幕截图演示了向节点ip-10-0-0-151.af-south-1.compute.internal上托管orders副本的成功外部请求graphql以及来自的成功嵌套请求。graphql


使用 Istio,你可以验证和导出任何 [上游集群] 的统计数据 (https://www.envoyproxy. io/docs/envoy/latest/intro/arch_overview/intro/terminologygraphql代理知道的orders端点:
kubectl exec -it deploy/graphql -n ecommerce -c istio-proxy -- curl localhost:15000/clusters | grep orders
... orders-service.ecommerce.svc.cluster.local::10.0.1.33:3003::**rq_error::0** orders-service.ecommerce.svc.cluster.local::10.0.1.33:3003::**rq_success::119** orders-service.ecommerce.svc.cluster.local::10.0.1.33:3003::**rq_timeout::0** orders-service.ecommerce.svc.cluster.local::10.0.1.33:3003::**rq_total::119** orders-service.ecommerce.svc.cluster.local::10.0.1.33:3003::**health_flags::healthy** orders-service.ecommerce.svc.cluster.local::10.0.1.33:3003::**region::af-south-1** orders-service.ecommerce.svc.cluster.local::10.0.1.33:3003::**zone::af-south-1b** ...
在这种情况下,graphql代理只知道与其共享节点的副本的orders终端节点。如果您从 orders Service 中删除该internalTrafficPolicy: Local设置,然后重新运行类似于上面的命令,则结果将返回分布在不同节点上的副本的所有端点。此外,通过检查相应的rq_total端点,您会注意到网络分布的份额相对均匀。因此,如果端点与在不同区域中运行的上游服务相关联 AZs,则这种跨区域的网络分布将导致更高的成本。
如上文前一节所述,你可以利用 pod 的亲和力将频繁通信的 Pod 放在同一个地方。
... spec: ... template: metadata: labels: app: graphql role: api workload: ecommerce spec: affinity: podAffinity: requiredDuringSchedulingIgnoredDuringExecution: - labelSelector: matchExpressions: - key: app operator: In values: - orders topologyKey: "kubernetes.io/hostname" nodeSelector: managedBy: karpenter billing-team: ecommerce ...
当graphql和orders副本不在同一个节点 (ip-10-0-0-151.af-south-1.compute.internal) 上共存时,第一个请求成功,如下面graphql的 Postman 屏幕截图所200 response code示,而第二个从graphql到的嵌套请求将orders失败,结果为 a。503 response code

其他资源
