本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
Kubernetes 控制平面
Kubernetes 控制平面由 Kubernetes API 服务器、Kubernetes 控制器管理器、调度器和 Kubernetes 运行所需的其他组件组成。这些组件的可扩展性限制因您在集群中运行的内容而异,但对扩展影响最大的领域包括 Kubernetes 版本、利用率和单个节点扩展。
使用 EKS 1.24 或更高版本
EKS 1.24 引入了许多更改,并将容器运行时切换为 contain erd 而不--container-runtime引导程序标志。
限制工作负载和节点爆发
重要
为了避免在控制平面上达到 API 限制,您应该限制一次将集群大小增加两位数百分比的扩展峰值(例如,1000 个节点增加到 1100 个节点,或者同时增加 4000 到 4500 个 pod)。
EKS 控制平面将随着集群的增长而自动扩展,但是它的扩展速度有限制。首次创建 EKS 集群时,控制平面将无法立即扩展到数百个节点或数千个 Pod。要详细了解 EKS 如何进行扩展改进,请参阅此博客文章
扩展大型应用程序需要基础设施适应以完全准备就绪(例如,变暖负载均衡器)。要控制扩展速度,请确保根据应用程序的正确指标进行扩展。CPU 和内存缩放可能无法准确预测您的应用程序限制,在 Kubernetes 水平容器自动扩缩器 (HPA) 中使用自定义指标(例如每秒请求数)可能是更好的扩展选项。
要使用自定义指标,请参阅 Kubernetes
安全地向下扩展节点和 pod
替换长时间运行的实例
定期更换节点可以避免配置偏差和只有在延长正常运行时间后才会出现的问题(例如缓慢的内存泄漏),从而保持集群的健康。自动替换将为您提供良好的节点升级和安全补丁流程和实践。如果定期更换集群中的每个节点,那么维护单独的进程以进行持续维护所需的辛勤工作就会减少。
使用 Karpenter 的生存时间 (TTL)max-instance-lifetime设置自动循环节点。托管节点组目前没有此功能,但您可以在此
移除未充分利用的节点
当节点没有正在运行的工作负载时,你可以使用 Kubernetes 集群自动扩缩器中的缩减阈值将其移除,--scale-down-utilization-thresholdttlSecondsAfterEmpty
使用 pod 中断预算和安全关闭节点
从 Kubernetes 集群中移除 Pod 和节点需要控制器对多个资源进行更新(例如)。 EndpointSlices当更改传播到控制器时,频繁或过快地执行此操作可能会导致 API 服务器限制和应用程序中断。当集群中的节点被移除或重新调度时,Pod 中断预算
运行 Kubectl 时使用客户端缓存
如果使用 kubectl 命令效率低下,可能会给 Kubernetes API 服务器增加额外的负载。你应该避免运行重复使用 kubectl 的脚本或自动化(例如在 for 循环中),或者在没有本地缓存的情况下运行命令。
kubectl具有客户端缓存,用于缓存来自集群的发现信息,以减少所需的 API 调用量。默认情况下,缓存处于启用状态,并且每 10 分钟刷新一次。
如果您从容器或没有客户端缓存的情况下运行 kubectl,则可能会遇到 API 限制问题。建议通过挂载来保留您的集群缓存,--cache-dir以避免进行不必要的 API 调用。
禁用 kubectl 压缩
在你的 kubeconfig 文件中禁用 kubectl 压缩可以降低 API 和客户端 CPU 的使用率。默认情况下,服务器将压缩发送到客户端的数据以优化网络带宽。这会增加每个请求在客户端和服务器上的 CPU 负载,如果您有足够的带宽,禁用压缩可以减少开销和延迟。要禁用压缩,你可以在 kubeconfig 文件disable-compression: true中使用或设置该--disable-compression=true标志。
apiVersion: v1
clusters:
- cluster:
server: serverURL
disable-compression: true
name: cluster
分片集群自动扩缩器
Kubernetes 集群自动扩缩器已经过测试,可以扩展
ClusterAutoscaler-1
autoscalingGroups: - name: eks-core-node-grp-20220823190924690000000011-80c1660e-030d-476d-cb0d-d04d585a8fcb maxSize: 50 minSize: 2 - name: eks-data_m1-20220824130553925600000011-5ec167fa-ca93-8ca4-53a5-003e1ed8d306 maxSize: 450 minSize: 2 - name: eks-data_m2-20220824130733258600000015-aac167fb-8bf7-429d-d032-e195af4e25f5 maxSize: 450 minSize: 2 - name: eks-data_m3-20220824130553914900000003-18c167fa-ca7f-23c9-0fea-f9edefbda002 maxSize: 450 minSize: 2
ClusterAutoscaler-2
autoscalingGroups: - name: eks-data_m4-2022082413055392550000000f-5ec167fa-ca86-6b83-ae9d-1e07ade3e7c4 maxSize: 450 minSize: 2 - name: eks-data_m5-20220824130744542100000017-02c167fb-a1f7-3d9e-a583-43b4975c050c maxSize: 450 minSize: 2 - name: eks-data_m6-2022082413055392430000000d-9cc167fa-ca94-132a-04ad-e43166cef41f maxSize: 450 minSize: 2 - name: eks-data_m7-20220824130553921000000009-96c167fa-ca91-d767-0427-91c879ddf5af maxSize: 450 minSize: 2
API 优先级和公平性
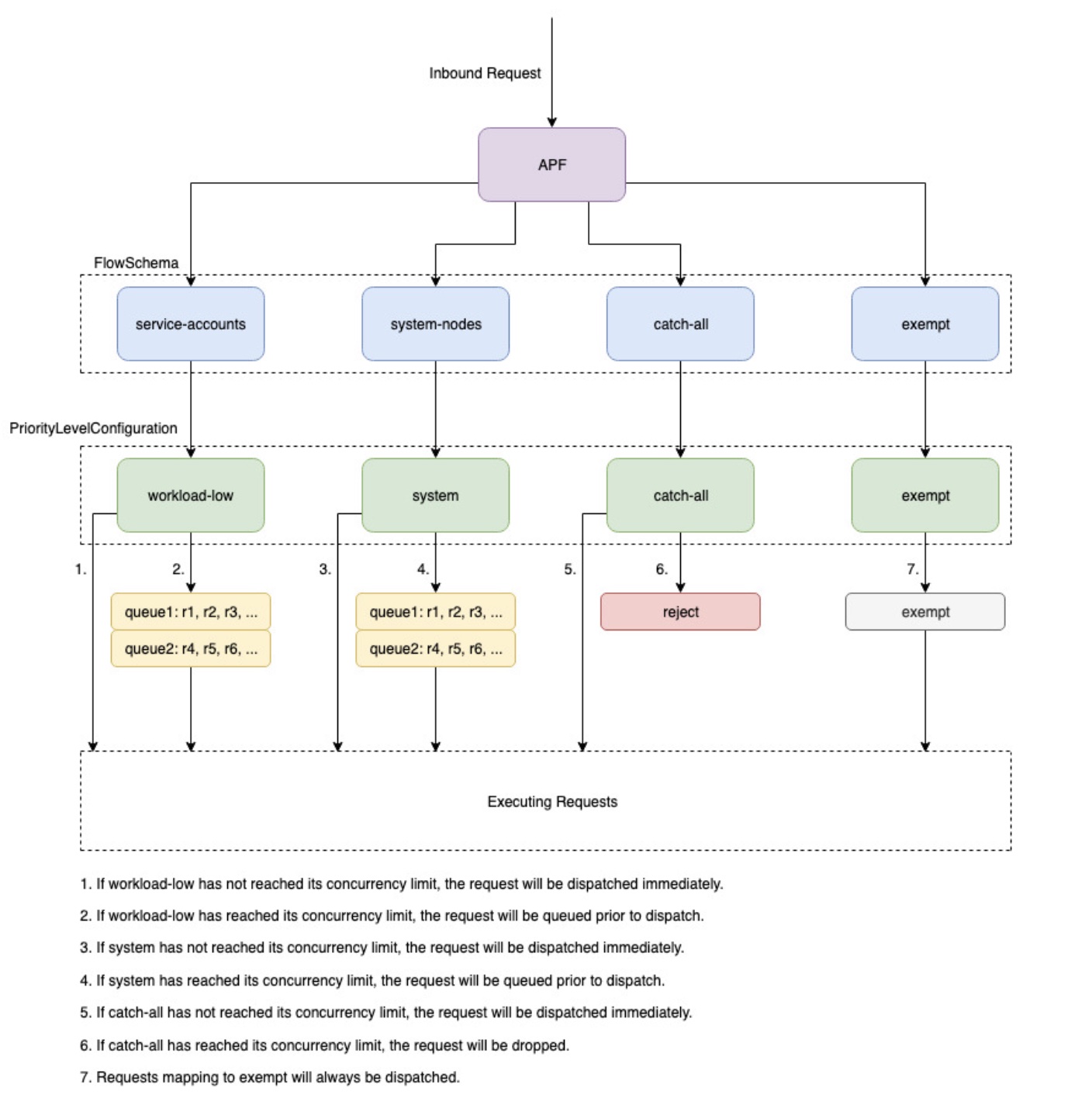
概览
为了防止自己在请求增加期间过载,API 服务器限制了在给定时间内可能未完成的飞行中请求的数量。超过此限制后,API 服务器将开始拒绝请求,并将 “请求过多” 的 429 HTTP 响应代码返回给客户端。服务器丢弃请求并让客户端稍后再试比服务器端对请求数量没有限制和控制平面过载更可取,后者可能会导致性能下降或不可用。
Kubernetes 用来配置如何在不同请求类型之间划分这些机上请求的机制称为 API--max-requests-inflight --max-mutating-requests-inflightEKS 对这些标志使用默认值 400 和 200 个请求,允许在给定时间总共发送 600 个请求。但是,由于它将控制平面扩展到更大的大小以应对利用率的增加和工作负载流失,因此它相应地将机上请求配额一直增加到2000年(可能会发生变化)。APF 规定了如何在不同的请求类型之间进一步细分这些机上请求配额。请注意,EKS 控制平面高度可用,每个集群至少注册了 2 个 API 服务器。这意味着您的集群可以处理的飞行中请求总数是每个 kube-apiserver 设置的机上配额的两倍(如果进一步横向扩展,则更高)。在最大的 EKS 集群 requests/second 上,这相当于数千个。
两种名为 “ PriorityLevelConfigurations 和 FlowSchemas” 的 Kubernetes 对象配置如何在不同的请求类型之间分配请求总数。这些对象由 API 服务器自动维护,EKS 使用给定的 Kubernetes 次要版本中这些对象的默认配置。 PriorityLevelConfigurations 仅占允许请求总数的一小部分。例如,在总共 600 个请求中 PriorityLevelConfiguration ,分配了工作负载最高的 98 个。分配给所有请求的总和 PriorityLevelConfigurations 将等于 600(或略高于 600,因为如果向给定级别授予请求的一小部分,API 服务器将向上舍入)。要检查集群 PriorityLevelConfigurations 中的以及分配给每个集群的请求数,可以运行以下命令。以下是 EKS 1.24 的默认设置:
$ kubectl get --raw /metrics | grep apiserver_flowcontrol_request_concurrency_limit apiserver_flowcontrol_request_concurrency_limit{priority_level="catch-all"} 13 apiserver_flowcontrol_request_concurrency_limit{priority_level="global-default"} 49 apiserver_flowcontrol_request_concurrency_limit{priority_level="leader-election"} 25 apiserver_flowcontrol_request_concurrency_limit{priority_level="node-high"} 98 apiserver_flowcontrol_request_concurrency_limit{priority_level="system"} 74 apiserver_flowcontrol_request_concurrency_limit{priority_level="workload-high"} 98 apiserver_flowcontrol_request_concurrency_limit{priority_level="workload-low"} 245
第二种物体是 FlowSchemas。具有给定属性集的 API 服务器请求被归入同一组属性下 FlowSchema。这些属性包括经过身份验证的用户或请求的属性,例如 API 组、命名空间或资源。A FlowSchema 还指定应映射到哪 PriorityLevelConfiguration 种类型的请求。这两个对象一起说:“我希望这种类型的请求计入机上请求的份额。” 当请求到达 API 服务器时,它将检查每个请求, FlowSchemas 直到找到一个与所有必需属性相匹配的请求。如果多个请求 FlowSchemas 匹配,API 服务器将选择匹配优先级最小的,该优先级被指定为对象中的属性。 FlowSchema
PriorityLevelConfigurations 可以使用以下命令查看 FlowSchemas 到的映射:
$ kubectl get flowschemas NAME PRIORITYLEVEL MATCHINGPRECEDENCE DISTINGUISHERMETHOD AGE MISSINGPL exempt exempt 1 <none> 7h19m False eks-exempt exempt 2 <none> 7h19m False probes exempt 2 <none> 7h19m False system-leader-election leader-election 100 ByUser 7h19m False endpoint-controller workload-high 150 ByUser 7h19m False workload-leader-election leader-election 200 ByUser 7h19m False system-node-high node-high 400 ByUser 7h19m False system-nodes system 500 ByUser 7h19m False kube-controller-manager workload-high 800 ByNamespace 7h19m False kube-scheduler workload-high 800 ByNamespace 7h19m False kube-system-service-accounts workload-high 900 ByNamespace 7h19m False eks-workload-high workload-high 1000 ByUser 7h14m False service-accounts workload-low 9000 ByUser 7h19m False global-default global-default 9900 ByUser 7h19m False catch-all catch-all 10000 ByUser 7h19m False
PriorityLevelConfigurations 可以有 “队列”、“拒绝” 或 “豁免” 的类型。对于 Queue 和 Reject 类型,将对该优先级的最大机上请求数施加限制,但是,当达到该限制时,行为会有所不同。例如,workload-high PriorityLevelConfiguration 使用 Queue 类型,有 98 个请求可供控制器管理器、端点控制器、调度器、eks 相关控制器以及在 kube-system 命名空间中运行的 pod 使用。由于使用了 Queue 类型,API 服务器将尝试将请求保留在内存中,并希望在这些请求超时之前将正在运行的请求数量降至 98 以下。如果给定请求在队列中超时,或者已经排队的请求太多,API 服务器别无选择,只能放弃该请求并向客户端返回 429。请注意,排队可能会阻止请求接收 429,但需要权衡请求 end-to-end延迟时间增加。
现在考虑一下映射到包罗万 FlowSchema 象的 “拒绝” 类型 PriorityLevelConfiguration 。如果客户端达到 13 个机上请求的限制,API 服务器将不会进行排队,而是使用 429 响应代码立即丢弃请求。最后,映射到类型为 “豁免” PriorityLevelConfiguration 的请求将永远不会收到 429,并且始终会立即分发。这用于高优先级请求,例如 healthz 请求或来自 system: masters 组的请求。
监控 APF 和已删除的请求
要确认是否有任何请求因 APF 而被丢弃,apiserver_flowcontrol_rejected_requests_total可以监控 API 服务器指标以检查受影响的 FlowSchemas 和 PriorityLevelConfigurations。例如,此指标显示,由于请求在工作负载较低的队列中超时,来自服务帐号的 100 个请求 FlowSchema 被丢弃:
% kubectl get --raw /metrics | grep apiserver_flowcontrol_rejected_requests_total
apiserver_flowcontrol_rejected_requests_total{flow_schema="service-accounts",priority_level="workload-low",reason="time-out"} 100
要检查给定对象与接收 429 的 PriorityLevelConfiguration 距离有多近,或者由于排队而出现延迟增加,您可以比较并发限制和正在使用的并发数之间的差异。在此示例中,我们有一个包含 100 个请求的缓冲区。
% kubectl get --raw /metrics | grep 'apiserver_flowcontrol_request_concurrency_limit.*workload-low' apiserver_flowcontrol_request_concurrency_limit{priority_level="workload-low"} 245 % kubectl get --raw /metrics | grep 'apiserver_flowcontrol_request_concurrency_in_use.*workload-low' apiserver_flowcontrol_request_concurrency_in_use{flow_schema="service-accounts",priority_level="workload-low"} 145
要检查给定对象 PriorityLevelConfiguration 是否遇到排队但请求不一定被丢弃的情况,apiserver_flowcontrol_current_inqueue_requests可以参考以下指标:
% kubectl get --raw /metrics | grep 'apiserver_flowcontrol_current_inqueue_requests.*workload-low'
apiserver_flowcontrol_current_inqueue_requests{flow_schema="service-accounts",priority_level="workload-low"} 10
其他有用的 Prometheus 指标包括:
-
apiserver_flowcontrol_dispatched_request_t
-
apiserver_flowcontrol_requestion_exection
-
apiserver_flowcontrol_request_wait_duration_se
有关 APF 指标
防止请求被丢弃
通过更改工作负载来防止 429 秒
当 APF 因给定请求 PriorityLevelConfiguration 超过其允许的最大机上请求数而丢弃请求时,受影响的客户端 FlowSchemas 可以减少在给定时间执行的请求数。这可以通过减少在发生 429 的时段内发出的请求总数来实现。请注意,长时间运行的请求(例如昂贵的列表调用)尤其成问题,因为它们在整个执行期间都算作飞行中请求。减少这些昂贵的请求的数量或优化这些列表调用的延迟(例如,通过减少每个请求获取的对象数量或切换到使用监视请求)可以帮助减少给定工作负载所需的总并发量。
通过更改 APF 设置来防止 429 秒
警告
只有在知道自己在做什么时才更改默认 APF 设置。APF 设置配置不当可能会导致 API 服务器请求丢失和工作负载严重中断。
防止请求被丢弃的另一种方法是更改默认值 FlowSchemas 或在 EKS 集群上 PriorityLevelConfigurations 安装的设置。EKS 为 FlowSchemas 给定的 Kubernetes 次要版本安装上游默认设置。 PriorityLevelConfigurations 如果修改了这些对象,API 服务器会自动将这些对象协调回其默认值,除非这些对象的以下注释设置为 false:
metadata:
annotations:
apf.kubernetes.io/autoupdate-spec: "false"
简而言之,可以将 APF 设置修改为:
-
为您关心的请求分配更多机上容量。
-
隔离不必要或昂贵的请求,这些请求可能会导致其他请求类型的容量不足。
这可以通过更改默认值 FlowSchemas 和 PriorityLevelConfigurations 或通过创建这些类型的新对象来实现。操作员可以增加相关 PriorityLevelConfigurations 对象 assuredConcurrencyShares 的值,以增加分配给它们的飞行中请求的比例。此外,如果应用程序能够处理因请求在调度之前排队而造成的额外延迟,则在给定时间可以排队的请求数量也可以增加。
或者,可以创建特定于客户工作负载的新 PriorityLevelConfigurations 对象 FlowSchema 和对象。请注意, assuredConcurrencyShares 向现有 PriorityLevelConfigurations 或新存储桶分配更多请求 PriorityLevelConfigurations 将导致其他存储桶可以处理的请求数量减少,因为每个 API 服务器的总体限制将保持在 600 个正在进行中。
更改 APF 默认值时,应在非生产集群上监控这些指标,以确保更改设置不会导致意外的 429:
-
apiserver_flowcontrol_rejected_requests_total应监控所有人的指标, FlowSchemas 以确保没有存储桶开始丢弃请求。 -
apiserver_flowcontrol_request_concurrency_in_use应比较apiserver_flowcontrol_request_concurrency_limit和的值,以确保使用的并发不会因为突破该优先级的限制而面临风险。
定义新的 and 的一个常见用例 PriorityLevelConfiguration 是 FlowSchema 隔离。假设我们想将来自 pod 的长时间运行的列表事件调用隔离到它们自己的请求份额。这将防止来自使用现有服务帐户 FlowSchema 的 pod 的重要请求接收 429 并导致请求容量不足。回想一下,飞行中请求的总数是有限的,但是,此示例显示可以修改 APF 设置以更好地划分给定工作负载的请求容量:
用于隔离列表事件请求的示例 FlowSchema 对象:
apiVersion: flowcontrol.apiserver.k8s.io/v1beta1
kind: FlowSchema
metadata:
name: list-events-default-service-accounts
spec:
distinguisherMethod:
type: ByUser
matchingPrecedence: 8000
priorityLevelConfiguration:
name: catch-all
rules:
- resourceRules:
- apiGroups:
- '*'
namespaces:
- default
resources:
- events
verbs:
- list
subjects:
- kind: ServiceAccount
serviceAccount:
name: default
namespace: default
-
这将 FlowSchema 捕获默认命名空间中服务帐号发出的所有列表事件调用。
-
匹配优先级 8000 低于现有服务帐户使用的值 9000, FlowSchema 因此这些列表事件调用将匹配 list-events-default-service-accounts 而不是服务帐户。
-
我们正在使用包罗万象 PriorityLevelConfiguration 来隔离这些请求。此存储桶仅允许这些长时间运行的列表事件调用使用 13 个飞行中请求。当 Pod 尝试同时发出超过 13 个这样的请求时,它们就会开始收到 429。
在 API 服务器中检索资源
对于任何规模的集群,从 API 服务器获取信息都是一种预期行为。在扩展集群中的资源数量时,请求频率和数据量很快就会成为控制平面的瓶颈,并导致 API 延迟和缓慢。根据延迟的严重程度,如果不小心,它会导致意外停机。
了解您的要求以及避免此类问题的第一步是多久一次。以下是根据扩展最佳实践限制查询量的指南。本节中的建议是按顺序提供的,从已知可以最佳扩展的选项开始。
使用共享举报人
在构建与 Kubernetes API 集成的控制器和自动化时,您通常需要从 Kubernetes 资源中获取信息。如果您定期轮询这些资源,可能会导致 API 服务器负载过重。
使用 client-go 库中的告密器
控制器应避免在没有标签和字段选择器的情况下轮询集群范围内的资源,尤其是在大型集群中。每个未过滤的民意调查都需要通过 API 服务器从 etcd 发送大量不必要的数据,然后由客户端进行过滤。通过根据标签和命名空间进行筛选,可以减少 API 服务器为完成发送到客户端的请求和数据而需要执行的工作量。
优化 Kubernetes API 的使用情况
使用自定义控制器或自动化调用 Kubernetes API 时,请务必将调用限制在所需的资源上。没有限制,您可能会在 API 服务器和 etcd 上造成不必要的负载。
建议尽可能使用 watch 参数。如果没有参数,则默认行为是列出对象。要使用监视而不是列表,您可以在 API 请求?watch=true的末尾追加。例如,要使用手表获取默认命名空间中的所有 pod,请使用:
/api/v1/namespaces/default/pods?watch=true
如果您要列出对象,则应限制所列内容的范围和返回的数据量。您可以通过在请求中添加limit=500参数来限制返回的数据。fieldSelector参数和/namespace/路径对于确保列表的范围根据需要缩小范围很有用。例如,要仅列出默认命名空间中正在运行的 Pod,请使用以下 API 路径和参数。
/api/v1/namespaces/default/pods?fieldSelector=status.phase=Running&limit=500
或者列出所有正在使用以下命令运行的 pod:
/api/v1/pods?fieldSelector=status.phase=Running&limit=500
限制监视调用或列出的对象的另一种选择是使用它 resourceVersions,你可以在 Kubernetes 文档中阅读相关内容resourceVersion参数,您将收到最新的可用版本,该版本需要 etcd 法定读取,这是数据库中最昂贵和最慢的读取。ResourceVersion 取决于你要查询的资源,这些资源可以在现场找到。metadata.resourseVersion如果使用监视通话,而不仅仅是列出通话,也建议这样做
有一种特殊功能resourceVersion=0可以从 API 服务器缓存中返回结果。这可以减少 etcd 的负载,但它不支持分页。
/api/v1/namespaces/default/pods?resourceVersion=0
建议使用 watch,将 ResourceVersion 设置为从其先前的列表或监视中收到的最新已知值。这是在 client-go 中自动处理的。但是,如果您使用的是其他语言的 k8s 客户端,建议您仔细检查一下。
/api/v1/namespaces/default/pods?watch=true&resourceVersion=362812295
如果你在没有任何参数的情况下调用 API,它将是 API 服务器和 etcd 资源最密集的。此调用将在不进行分页或限制范围的情况下获取所有命名空间中的所有 pod,并且需要从 etcd 读取法定人数。
/api/v1/pods
防止 DaemonSet 雷鸣般的牛群
A DaemonSet 可确保所有(或部分)节点都运行 Pod 的副本。当节点加入集群时,守护程序集控制器会为这些节点创建 Pod。当节点离开集群时,这些 Pod 会被垃圾回收。删除 a DaemonSet 会清理它创建的 pod。
a 的一些典型用法 DaemonSet 是:
-
在每个节点上运行集群存储守护程序
-
在每个节点上运行日志收集守护程序
-
在每个节点上运行节点监视守护程序
在拥有数千个节点的集群上 DaemonSet,创建新节点 DaemonSet、更新节点或增加节点数量可能会导致控制平面上的负载过高。如果 DaemonSet Pod 在 Pod 启动时发出昂贵的 API 服务器请求,则大量并发请求可能会导致控制层面的资源使用率过高。
在正常操作中,您可以使用RollingUpdate来确保逐步推出新 DaemonSet pod。使用RollingUpdate更新策略,在你更新 DaemonSet 模板后,控制器会以受控的方式杀死旧 DaemonSet 的 p DaemonSet od 并自动创建新的 pod。在整个更新过程中 DaemonSet ,每个节点上最多只能运行一个 pod。您可以通过将设置maxUnavailable为 1、0 和 minReadySeconds 60 maxSurge 来执行逐步部署。如果您未指定更新策略,Kubernetes 将默认为创建一个,其值RollingUpdatemaxUnavailable为 1、maxSurge为 0 和 minReadySeconds 0。
minReadySeconds: 60
strategy:
type: RollingUpdate
rollingUpdate:
maxSurge: 0
maxUnavailable: 1
如果已经创建了新的 DaemonSet pod,并且所有节点上 DaemonSet 的 pod 数量都达到预期,则RollingUpdate可以确保逐步推出新Ready的 pod。在战略未涵盖的某些条件下,可能会出现雷鸣般的牛群问题。RollingUpdate
防止在创建时出现雷鸣般的牛群 DaemonSet
默认情况下,无论RollingUpdate配置如何,在创建新节点时,中的守护程序集控制器 kube-controller-manager都会同时为所有匹配的节点创建 pod。 DaemonSet要在创建 pod 之后强制逐步推出 pod DaemonSet,你可以使用NodeSelector或NodeAffinity。这将创建一个匹配零个节点的 DaemonSet ,然后你可以逐渐更新节点,使它们有资格以受控的速率从中 DaemonSet 运行 Pod。你可以遵循这种方法:
-
为的所有节点添加标签
run-daemonset=false。
kubectl label nodes --all run-daemonset=false
-
使用 DaemonSet 与任何没有
run-daemonset=false标签的节点相匹配的NodeAffinity设置来创建。最初,这将导致你 DaemonSet 没有相应的 pod。
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: run-daemonset
operator: NotIn
values:
- "false"
-
以受控的速率从节点上移除
run-daemonset=false标签。你可以用这个 bash 脚本作为示例:
#!/bin/bash
nodes=$(kubectl get --raw "/api/v1/nodes" | jq -r '.items | .[].metadata.name')
for node in ${nodes[@]}; do
echo "Removing run-daemonset label from node $node"
kubectl label nodes $node run-daemonset-
sleep 5
done
-
(可选)从 DaemonSet 对象中移除该
NodeAffinity设置。请注意,由于 DaemonSet 模板已更改,这也会触发RollingUpdate并逐渐替换所有现有的 DaemonSet pod。
防止节点横向扩展时出现雷鸣般的牛群
与 DaemonSet 创建类似,快速创建新节点可能会导致大量 DaemonSet Pod 同时启动。您应该以受控的速率创建新节点,以便控制器以相同的速率创建 DaemonSet Pod。如果无法做到这一点,则可以使用使新节点最初不符合现有 DaemonSet 节点的资格。NodeAffinity接下来,你可以逐渐为新节点添加标签,这样 daemonset-controller 就可以以受控的速率创建 Pod。你可以遵循这种方法:
-
为所有现有节点添加标签
run-daemonset=true
kubectl label nodes --all run-daemonset=true
-
DaemonSet 使用设置更新您的
NodeAffinity设置,以匹配任何带有run-daemonset=true标签的节点。请注意,由于 DaemonSet 模板已更改,这也会触发RollingUpdate并逐渐替换所有现有的 DaemonSet pod。您应该等RollingUpdate到完成后再进入下一步。
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: run-daemonset
operator: In
values:
- "true"
-
在集群中创建新节点。请注意,这些节点没有
run-daemonset=true标签,因此 DaemonSet 不会与这些节点匹配。 -
以受控的速率将
run-daemonset=true标签添加到您的新节点(当前没有run-daemonset标签)。你可以用这个 bash 脚本作为示例:
#!/bin/bash
nodes=$(kubectl get --raw "/api/v1/nodes?labelSelector=%21run-daemonset" | jq -r '.items | .[].metadata.name')
for node in ${nodes[@]}; do
echo "Adding run-daemonset=true label to node $node"
kubectl label nodes $node run-daemonset=true
sleep 5
done
-
或者,从 DaemonSet 对象中移除
NodeAffinity设置并从所有节点上移除run-daemonset标签。
防止更新时出现雷鸣般的牛群 DaemonSet
RollingUpdate策略只会尊重符合条件的 DaemonSet Pod 的maxUnavailable设置Ready。如果 a 只 DaemonSet 有 NotReady pod 或很大比例的 NotReady pod,并且您更新了其模板,则守护程序控制器将同时为任何 pod 创建新的 pod。NotReady如果有大量的 NotReady pod,这可能会导致雷鸣般的牛群问题,例如,如果 pod 持续崩溃循环或无法提取图像。
要在更新 a DaemonSet 且有 pod 时强制逐步推出 NotReady pod,可以暂时将更新策略 DaemonSet 从 from 更改RollingUpdate为OnDelete。在更新 DaemonSet 模板后OnDelete,控制器会在您手动删除旧的 pod 之后创建新的 pod,这样您就可以控制新 pod 的推出了。你可以遵循这种方法:
-
检查您的
NotReady吊舱里是否有吊舱 DaemonSet。 -
如果不是,您可以放心地更新 DaemonSet 模板,该
RollingUpdate策略将确保逐步推出。 -
如果是,则应先更新您的策略 DaemonSet 以使用该
OnDelete策略。
updateStrategy: type: OnDelete
-
接下来,使用所需的更改更新您的 DaemonSet 模板。
-
更新后,您可以通过以受控的速率发出删除 pod 请求来删除旧 DaemonSet pod。你可以用这个 bash 脚本作为示例,其中 kube-system 命名空间中的 DaemonSet 名字是 fluentd-elasticsearch:
#!/bin/bash
daemonset_pods=$(kubectl get --raw "/api/v1/namespaces/kube-system/pods?labelSelector=name%3Dfluentd-elasticsearch" | jq -r '.items | .[].metadata.name')
for pod in ${daemonset_pods[@]}; do
echo "Deleting pod $pod"
kubectl delete pod $pod -n kube-system
sleep 5
done
-
最后,你可以更新 DaemonSet 到之前的
RollingUpdate策略。
