Amazon Forecast 不再向新买家开放。Amazon Forecast 的现有客户可以继续照常使用该服务。了解更多
本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
DeepAR+ 算法
Amazon Forecast Deepar+ 是一种监督学习算法,用于使用循环神经网络 () 预测标量(一维)时间序列。RNNs经典预测方法,如自回归积分滑动平均模型 (ARIMA) 或指数平滑法 (ETS),将一个模型拟合到各个单独的时间序列,然后使用该模型外推时间序列到未来的情况。但是,在很多应用中,您有跨一组具有代表性单元的多个相似时间序列。这些时间序列分组需要不同的产品、服务器负载和网页请求。在此情况下,联合所有时间序列来训练单个模型会非常有益。DeepAR+ 采用此方法。当您的数据集包含数百个特征时间序列时,DeepAR+ 算法的效果将超过标准 ARIMA 和 ETS 方法。您还可以使用训练后的模型生成与其训练过的时间序列类似的新时间序列的预测。
Python 笔记本
有关使用 Deepar+ 算法的 step-by-step指南,请参阅 Deepar+ 入门
DeepAR+ 的工作原理
在训练过程中,DeepAR+ 将使用训练数据集和可选的测试数据集。它将使用测试数据集评估训练后的模型。通常,训练数据集和测试数据集不必包含相同的时间序列集。您可以使用在给定训练集上训练的模型来生成训练集中时间序列的未来以及其他时间序列的预测。训练数据集和测试数据集都由(最好是多个)目标时间序列组成。或者,它们可以与特征时间序列向量和分类特征向量相关联(有关详细信息,请参阅 AI 开发者指南中的 SageMaker Deepar 输入/输出接口)。以下示例说明如何对由 i 索引的训练数据集的元素执行此操作。训练数据集包含一个目标时间序列 zi,t 和两个关联的特征时间序列 xi,1,t 和 xi,2,t。
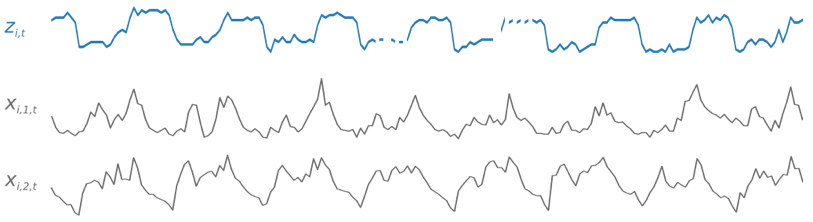
目标时间序列可能包含缺失值(在图表中用时间序列中的断点表示)。DeepAR+ 仅支持将来已知的特征时间序列。这允许您运行反事实的“假设”场景。例如,“如果我以某种方式改变产品的价格,会发生什么?”
每个目标时间序列也可以与大量分类特征关联。您可以使用它们对属于特定分组的时间序列进行编码。使用分类特征允许模型学习这些分组的典型行为,这可以提高准确性。模型通过学习每个组的嵌入向量来实现这一点,该嵌入向量捕获组中所有时间序列的公共属性。
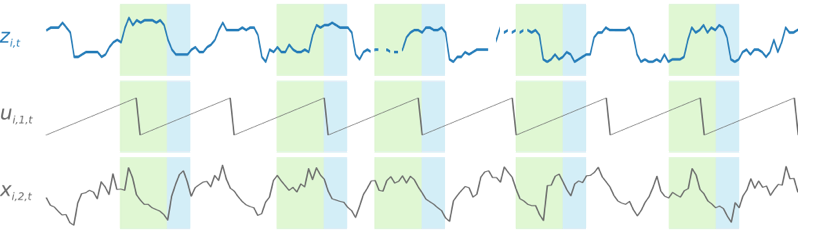
为了便于学习与时间相关的模式(如周末的峰值),DeepAR+ 将根据时间序列粒度自动创建特征时间序列。例如,DeepAR+ 按每周时间序列频率创建两个特征时间序列(一月中的某天和一年中的某天)。它使用这些派生的特征时间序列以及您在训练和推理期间提供的自定义特征时间序列。以下示例说明了两个派生的时间序列特征:ui,1,t 表示一天中的几点,ui,2,t 表示一周中的某天。

DeepAR+ 将根据数据频率和训练数据的大小自动包括这些特征时间序列。下表列出了可为每个支持的基本时间频率派生的特征。
| 时间序列的频率 | 派生的特征 |
|---|---|
| 分钟 | minute-of-hour, hour-of-day, day-of-week, day-of-month, day-of-year |
| 小时 | hour-of-day, day-of-week, day-of-month, day-of-year |
| 天 | day-of-week, day-of-month, day-of-year |
| 周 | week-of-month, week-of-year |
| Month | month-of-year |
通过从训练数据集中的每个时间序列中随机抽取多个训练示例来训练 DeepAR+ 模型。每个训练示例包括一对具有固定的预定义长度的相邻上下文和预测窗口。context_length 超参数控制网络可以往前回顾多长时间,ForecastHorizon 参数控制可以往后预测多长时间。训练期间,Amazon Forecast 将忽略训练数据集中的时间序列短于指定的预测长度的元素。以下示例显示了五个样本,其中上下文长度(以绿色突出显示)为 12 小时,预测长度(以蓝色突出显示)为 6 小时,从元素 i 中提取。为简洁起见,我们排除了特征时间序列 xi,1,t 和 ui,2,t。
为了捕获季节性模式,DeepAR+ 还自动提供目标时间序列的延迟(过去的时段)值。在我们的以小时频率采样的示例中,对于每个时间索引 t = T,模型会公开 zi,t 值,过去大约 1 天、2 天和 3 天(以粉色突出显示)执行此操作一次。
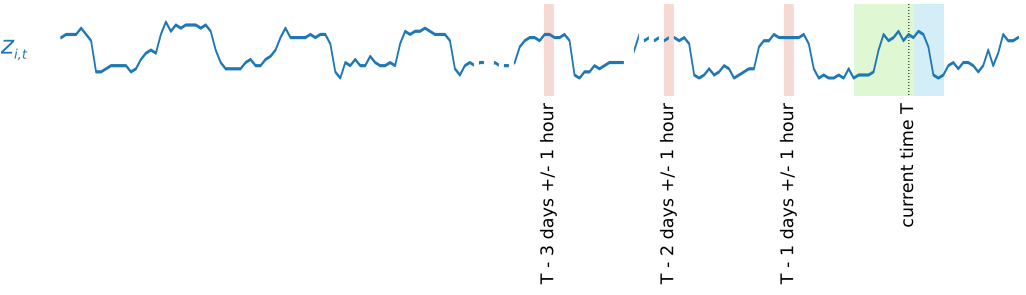
对于推理,训练后的模型将目标时间序列(这些时间序列在训练期间可能已使用,也可能未使用),并预测后续的 ForecastHorizon 值的概率分布。由于 DeepAR+ 是在整个数据集上进行训练的,因此,预测会考虑来自类似时间序列的学习模式。
有关 DeepAR+ 背后的数学运算的更多信息,请参阅康奈尔大学图书馆 (Cornell University Library) 网站上的 DeepAR:使用自回归递归网络进行概率预测
DeepAR+ 超参数
下表列出了可在 DeepAR+ 算法中使用的超参数。粗体显示的参数参与超参数优化 (HPO)。
| 参数名称 | 描述 |
|---|---|
context_length |
模型在进行预测之前读入的时间点数。此参数的值应该与
|
epochs |
扫描训练数据的最大次数。最佳值取决于您的数据大小和学习率。较小的数据集和较低的学习率都需要有更多的周期,才能获得良好的效果。
|
learning_rate |
训练中使用的学习率。
|
learning_rate_decay |
学习率降低的速度。学习率最多降低
|
likelihood |
模型生成一个概率预测,并可以提供分布的分位数和返回样本。根据您的数据,选择用于不确定性估算的适当可能性(噪声模型)。 有效值
|
max_learning_rate_decays |
应发生的学习率降低的最大数量。
|
num_averaged_models |
在 DeepAR+ 中,一个训练轨迹可以遇到多个模型。每种模型可能具有不同的预测优势和劣势。DeepAR+ 可以平均模型行为以利用所有模型的优势。
|
num_cells |
RNN 的各个隐藏层中使用的单元数。
|
num_layers |
RNN 中的隐藏层数。
|
优化 DeepAR+ 模型
要优化 Amazon Forecast DeepAR+ 模型,请遵循这些建议来优化训练流程和硬件配置。
流程优化的最佳实践
要实现最佳结果,请遵循以下建议:
-
除了分割训练和测试数据集之外,始终提供用于训练和测试的整个时间序列,以及在调用模型进行推理时。无论您如何设置
context_length,都不要划分时间序列或仅提供时间序列的一部分。对于滞后值特征,该模型将使用的数据点比context_length更早。 -
对于模型优化,您可以将数据集拆分为训练数据集和测试数据集。在典型的评估方案中,您应该采用训练所用的相同时间序列,但在未来的
ForecastHorizon个时间点(紧跟着在训练期间可见的最后一个时间点)上测试模型。要创建满足这些条件的训练数据集和测试数据集,请使用整个数据集(所有时间序列)作为测试数据集,并从每个时间序列中删除最后的ForecastHorizon个点来作为训练数据集。这样一来,在训练期间,模型将看不到测试期间评估它的时间点的目标值。在测试阶段,会保留测试数据集中每个时间序列的最后ForecastHorizon个点并生成预测。随后,将预测与最后ForecastHorizon个点的实际值进行比较。您可以在测试数据集中多次重复时间序列,但在不同的终端节点处切割它们来创建更复杂的评估。这将生成针对不同时间点的多个预测平均的准确率指标。 -
避免对
ForecastHorizon使用非常大的值(大于 400),因为这会降低模型的速度和准确性。如果您想进一步预测将来的情况,请考虑以更高的频率进行聚合。例如,使用5min而不是1min。 -
由于滞后,模型的预测范围可以比
context_length更大。因此,您不必将此参数设置为较大的值。此参数的一个好的起点是其值与ForecastHorizon相同。 -
使用尽可能多的时间序列训练 DeepAR+ 模型。尽管在单个时间序列上训练的 DeepAR+ 模型可能正常工作,但标准预测方法(如 ARIMA 或 ETS)可能更准确,并且更适合此使用案例。当数据集包含数百个特征时间序列时,DeepAR+ 方法开始优于标准方法。目前,DeepAR+ 要求所有训练时间序列中可用的观察总数至少为 300。
