使用您自己的 JDBC 驱动程序添加 JDBC 连接
使用 JDBC 连接时,您可以使用自己的 JDBC 驱动程序。当 AWS Glue 爬网程序使用的默认驱动程序无法连接到数据库时,您可以使用自己的 JDBC 驱动程序。例如,如果您想在 Postgres 数据库中使用 SHA-256,而较早的 Postgres 驱动程序不支持此功能,则可以使用自己的 JDBC 驱动程序。
支持的数据来源
| 支持的数据来源 | 不支持的数据来源 |
|---|---|
| MySQL | Snowflake |
| Postgres | |
| Oracle | |
| Redshift | |
| SQL Server | |
| Aurora* |
* 如果使用原生 JDBC 驱动程序,则支持。并非所有驱动程序功能都可以利用。
向 JDBC 连接中添加 JDBC 驱动程序
注意
如果您选择引入自己的 JDBC 驱动程序版本,则 AWS Glue 爬网程序将消耗 AWS Glue 作业 和 Amazon S3 存储桶中的资源,以确保您提供的驱动程序在您的环境中运行。额外的资源使用量将反映在您的账户中。AWS Glue 爬网程序和作业的成本属于计费 AWS Glue 类别。此外,提供自己的 JDBC 驱动程序并不意味着爬网程序能够利用该驱动程序的所有功能。
将您自己的 JDBC 驱动程序添加到 JDBC 连接:
-
将 JDBC 驱动程序文件添加到 Amazon S3 位置。您可以创建存储桶和/或文件夹,或使用现有存储桶和/或文件夹。
-
在 AWS Glue 控制台中,选择 Data Catalog 下方左侧菜单中的连接,然后创建新连接。
-
填写连接属性字段,然后为连接类型选择 JDBC。
-
在连接访问中,输入 JDBC URL 和 JDBC 驱动程序类名 - (可选)。驱动程序类名必须是 AWS Glue 爬网程序支持的数据来源的名称。
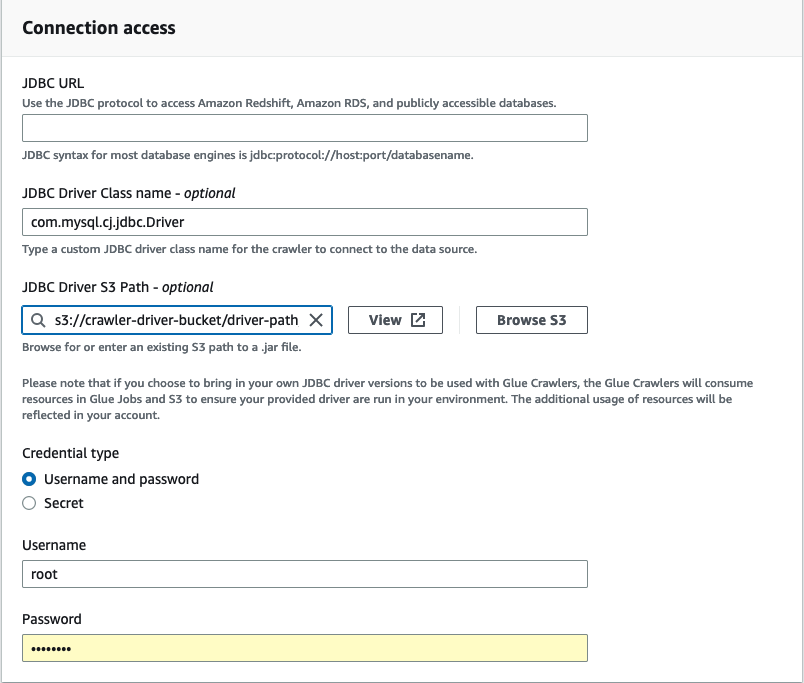
-
在 JDBC 驱动程序 Amazon S3 路径 - 可选字段中选择 JDBC 驱动程序所在的 Amazon S3 路径。
-
如果输入用户名和密码或密钥,请填写“凭证类型”字段。完成后,选择创建连接。
注意
目前不支持测试连接。使用您提供的 JDBC 驱动程序对数据来源进行爬取时,爬网程序会跳过此步骤。
-
将新创建的连接添加到爬网程序。在 AWS Glue 控制台中,选择 Data Catalog 下方左侧菜单中的爬网程序,然后创建新爬网程序。
-
在添加爬网程序向导中,在步骤 2 中选择添加数据来源。
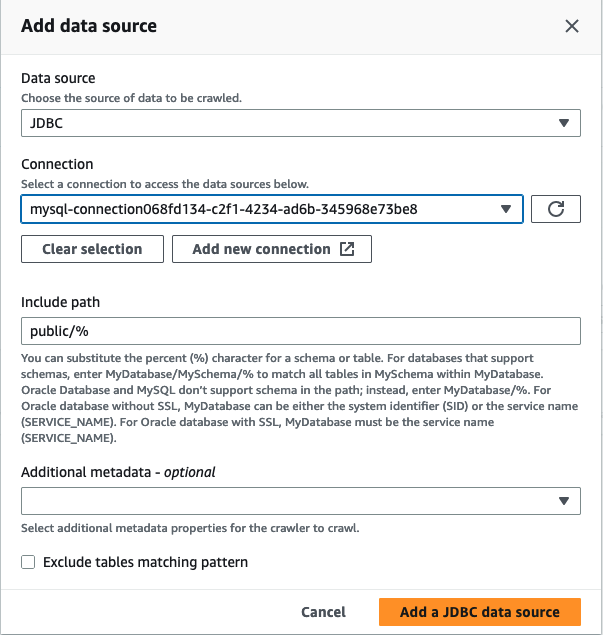
-
选择 JDBC 作为数据来源,然后选择在前面的步骤中创建的连接。完成
-
要将自己的 JDBC 驱动程序与 AWS Glue 爬网程序一起使用,请向该爬网程序使用的角色添加以下权限:
-
授予以下作业操作的权限:
CreateJob、DeleteJob、GetJob、GetJobRun、StartJobRun。 -
授予 IAM 操作的权限:
iam:PassRole -
授予 Amazon S3 操作的权限:
s3:DeleteObjects、s3:GetObject、s3:ListBucket、s3:PutObject。 -
在 IAM policy 中授予服务主体访问存储桶/文件夹的权限。
示例 IAM policy:
AWS Glue 爬网程序会创建两个文件夹:_glue_job_crawler 和 _crawler。
如果驱动程序 jar 位于
s3://amzn-s3-demo-bucket/driver.jar"文件夹中,则请添加以下资源:"Resource": [ "arn:aws:s3:::amzn-s3-demo-bucket/_glue_job_crawler/*", "arn:aws:s3:::amzn-s3-demo-bucket/_crawler/*" ]如果驱动程序 jar 位于
s3://amzn-s3-demo-bucket/tmp/driver/subfolder/driver.jar"文件夹中,则请添加以下资源:"Resource": [ "arn:aws:s3:::amzn-s3-demo-bucket/tmp/_glue_job_crawler/*", "arn:aws:s3:::amzn-s3-demo-bucket/tmp/_crawler/*" ] -
-
如果您使用的是 VPC,则必须通过创建接口端点并将其添加到您的路由表中来允许访问 AWS Glue 端点。有关更多信息,请参阅 Creating an interface VPC endpoint for AWS Glue
-
在 Data Catalog 中使用加密时,请创建 AWS KMS 接口端点并将其添加到您的路由表中。有关更多信息,请参阅为 AWS KMS 创建 VPC 端点。
