使用 Docker 映像在本地开发和测试 AWS Glue 作业
对于生产就绪型数据平台,AWS Glue 任务的开发过程和 CI/CD 管道是一个关键主题。您可以在 Docker 容器中灵活地开发和测试 AWS Glue 作业。AWS Glue 在 Docker Hub 上托管 Docker 映像,以使用其他实用程序设置开发环境。您可以使用首选 IDE、笔记本或使用 AWS Glue ETL 库的 REPL。本主题介绍如何使用 Docker 映像在 Docker 容器中开发和测试 AWS Glue 版本 5.0 作业。
可用的 Docker 映像
以下 Docker 映像可用于 Amazon ECR
-
对于 AWS Glue 版本 5.0:
public.ecr.aws/glue/aws-glue-libs:5 -
对于 AWS Glue 版本 4.0:
public.ecr.aws/glue/aws-glue-libs:glue_libs_4.0.0_image_01 -
对于 AWS Glue 版本 3.0:
public.ecr.aws/glue/aws-glue-libs:glue_libs_3.0.0_image_01 -
对于
public.ecr.aws/glue/aws-glue-libs:glue_libs_2.0.0_image_01版本 2.0:AWS Glue
注意
AWS Glue Docker 映像与 x86_64 和 arm64 兼容。
在本示例中,我们使用了 public.ecr.aws/glue/aws-glue-libs:5,并在本地计算机上运行容器(Mac、Windows 或 Linux)。此容器映像已经过 AWS Glue 版本 5.0 Spark 作业测试。此映像包含以下内容:
-
Amazon Linux 2023
-
AWS Glue ETL 库
-
Apache Spark 3.5.4
-
开放表格式库:Apache Iceberg 1.7.1、Apache Hudi 0.15.0 和 Delta Lake 3.3.0
-
AWS Glue Data Catalog 客户端
-
适用于 Apache Spark 的 Amazon Redshift 连接器
-
适用于 Apache Hadoop 的 Amazon DynamoDB 连接器
要设置自己的容器,请从 ECR Public Gallery 中拉取映像,然后运行该容器。本主题演示如何根据您的要求,使用下列方法运行容器:
-
spark-submit -
REPL shell
(pyspark) -
pytest -
Visual Studio Code
先决条件
在开始之前,请确保已安装 Docker 并且 Docker 守护进程正在运行。有关安装说明,请参阅 Mac
有关在本地开发 AWS Glue 代码时的限制的更多信息,请参阅本地开发限制。
配置 AWS
要从容器启用 AWS API 调用,请按照以下步骤设置 AWS 凭证。在以下部分中,我们将使用此 AWS 命名配置文件。
-
打开 Windows 上的
cmd或 Mac/Linux 上的终端,并在终端中运行以下命令:PROFILE_NAME="<your_profile_name>"
在以下部分中,我们将使用此 AWS 命名配置文件。
如果您在 Windows 上运行 Docker,请选择 Docker 图标(右键单击),然后在拉取映像之前选择切换到 Linux 容器。
请运行以下命令从 ECR Public 中拉取映像:
docker pull public.ecr.aws/glue/aws-glue-libs:5
运行容器
您现在可以使用此镜像运行容器。您可以根据您的要求选择以下任何选项。
spark-submit
您可以通过在容器上运行 spark-submit 命令来运行 AWS Glue 任务脚本。
-
编写脚本并将其作为
sample.py保存在以下示例中,然后使用以下命令将其保存在/local_path_to_workspace/src/目录下:$ WORKSPACE_LOCATION=/local_path_to_workspace $ SCRIPT_FILE_NAME=sample.py $ mkdir -p ${WORKSPACE_LOCATION}/src $ vim ${WORKSPACE_LOCATION}/src/${SCRIPT_FILE_NAME} -
这些变量用于下面的 docker run 命令。下面 spark-submit 命令中使用的示例代码 (sample.py) 包含在本主题末尾的附录里。
运行以下命令以在容器上执行
spark-submit命令,以提交新的 Spark 应用程序:$ docker run -it --rm \ -v ~/.aws:/home /hadoop/.aws \ -v $WORKSPACE_LOCATION:/home/hadoop/workspace/ \ -e AWS_PROFILE=$PROFILE_NAME \ --name glue5_spark_submit \ public.ecr.aws/glue/aws-glue-libs:5 \ spark-submit /home/hadoop/workspace/src/$SCRIPT_FILE_NAME -
(可选)配置
spark-submit以匹配您的环境。例如,您可以将依赖关系与--jars配置一起传递。有关更多信息,请参阅 Spark 文档中的 Dynamically Loading Spark Properties。
REPL shell(Pyspark)
您可以运行 REPL (read-eval-print loops) shell 进行交互式开发。运行以下命令在容器上执行 PySpark 命令以启动 REPL shell:
$ docker run -it --rm \ -v ~/.aws:/home/hadoop/.aws \ -e AWS_PROFILE=$PROFILE_NAME \ --name glue5_pyspark \ public.ecr.aws/glue/aws-glue-libs:5 \ pyspark
输出内容如下所示:
Python 3.11.6 (main, Jan 9 2025, 00:00:00) [GCC 11.4.1 20230605 (Red Hat 11.4.1-2)] on linux Type "help", "copyright", "credits" or "license" for more information. Setting default log level to "WARN". To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel). Welcome to ____ __ / __/__ ___ _____/ /__ _\ \/ _ \/ _ `/ __/ '_/ /__ / .__/\_,_/_/ /_/\_\ version 3.5.4-amzn-0 /_/ Using Python version 3.11.6 (main, Jan 9 2025 00:00:00) Spark context Web UI available at None Spark context available as 'sc' (master = local[*], app id = local-1740643079929). SparkSession available as 'spark'. >>>
有此 REPL shell,便能以交互方式进行编码和测试。
Pytest
若要进行单元测试,可将 pytest 用于 AWS Glue Spark 作业脚本。运行以下命令进行准备。
$ WORKSPACE_LOCATION=/local_path_to_workspace $ SCRIPT_FILE_NAME=sample.py $ UNIT_TEST_FILE_NAME=test_sample.py $ mkdir -p ${WORKSPACE_LOCATION}/tests $ vim ${WORKSPACE_LOCATION}/tests/${UNIT_TEST_FILE_NAME}
使用 docker run 运行以下命令来运行 pytest:
$ docker run -i --rm \ -v ~/.aws:/home/hadoop/.aws \ -v $WORKSPACE_LOCATION:/home/hadoop/workspace/ \ --workdir /home/hadoop/workspace \ -e AWS_PROFILE=$PROFILE_NAME \ --name glue5_pytest \ public.ecr.aws/glue/aws-glue-libs:5 \ -c "python3 -m pytest --disable-warnings"
在 pytest 执行完单元测试后,输出内容如下所示:
============================= test session starts ============================== platform linux -- Python 3.11.6, pytest-8.3.4, pluggy-1.5.0 rootdir: /home/hadoop/workspace plugins: integration-mark-0.2.0 collected 1 item tests/test_sample.py . [100%] ======================== 1 passed, 1 warning in 34.28s =========================
将容器设置为使用 Visual Studio 代码
要使用 Visual Studio Code 设置容器,请完成以下步骤:
安装 Visual Studio 代码。
安装 Python
。 在 Visual Studio 代码中打开工作区文件夹。
按
Ctrl+Shift+P(Windows/Linux)或Cmd+Shift+P(Mac)。键入
Preferences: Open Workspace Settings (JSON)。按 Enter。
粘贴以下 JSON 并保存它。
{ "python.defaultInterpreterPath": "/usr/bin/python3.11", "python.analysis.extraPaths": [ "/usr/lib/spark/python/lib/py4j-0.10.9.7-src.zip:/usr/lib/spark/python/:/usr/lib/spark/python/lib/", ] }
要设置容器,请按如下步骤操作:
-
运行 Docker 容器。
$ docker run -it --rm \ -v ~/.aws:/home/hadoop/.aws \ -v $WORKSPACE_LOCATION:/home/hadoop/workspace/ \ -e AWS_PROFILE=$PROFILE_NAME \ --name glue5_pyspark \ public.ecr.aws/glue/aws-glue-libs:5 \ pyspark -
启动 Visual Studio 代码。
-
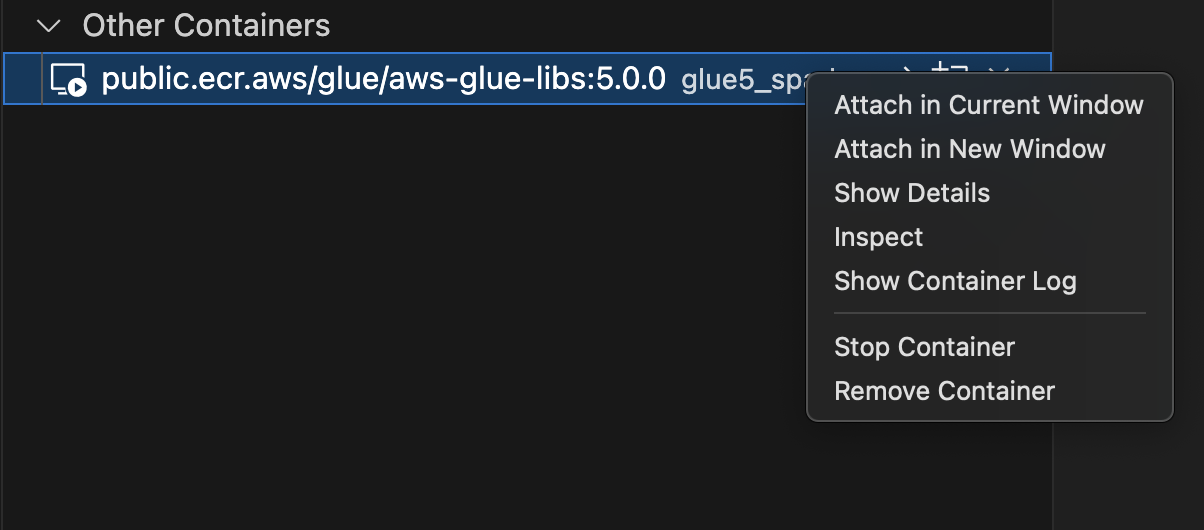
请选择左侧菜单中的 Remote Explorer,然后选择
amazon/aws-glue-libs:glue_libs_4.0.0_image_01。 -
右键单击,然后选择在当前窗口中附加。
-
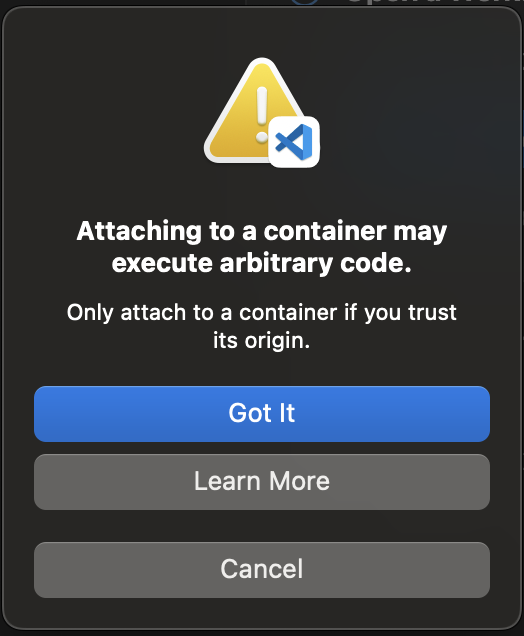
如果出现以下对话框,请选择知道了。
-
打开
/home/handoop/workspace/。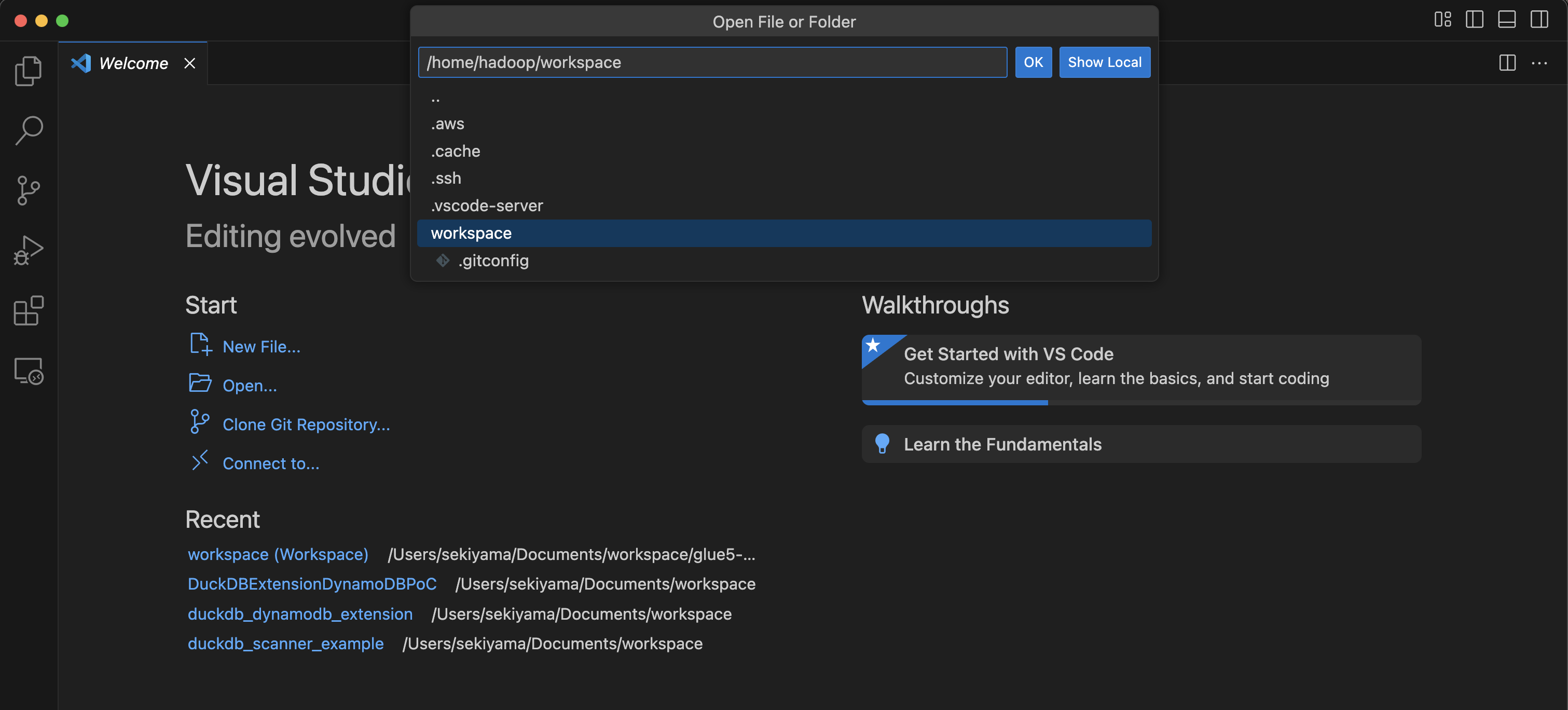
-
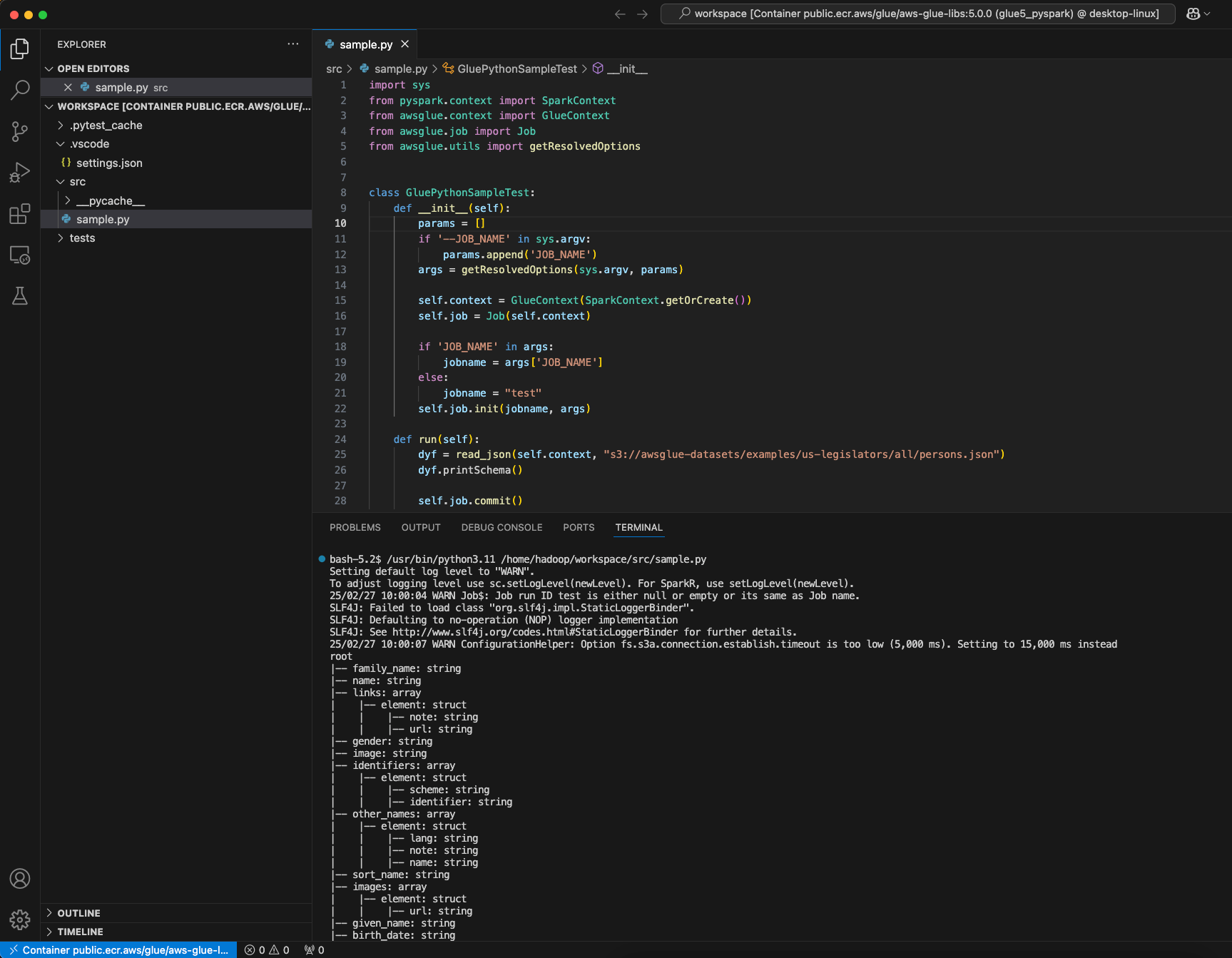
创建 AWS Glue PySpark 脚本,然后选择运行。
您将看到脚本成功运行。
AWS Glue 4.0 和 AWS Glue 5.0 Docker 映像之间的更改
AWS Glue 4.0 和 AWS Glue 5.0 Docker 映像之间的主要更改:
-
在 AWS Glue 5.0 中,批处理和流式处理作业都有一个容器映像。这与 Glue 4.0 不同,Glue 4.0 中有一个映像用于批处理,另一个映像用于流式处理。
-
在 AWS Glue 5.0 中,容器的默认用户名为
hadoop。在 AWS Glue 4.0 中,默认用户名为glue_user。 -
在 AWS Glue 5.0 中,映像中已删除其他几个库,包括 JupyterLab 和 Livy。但可以手动安装这些库。
-
在 AWS Glue 5.0 中,所有 Iceberg、Hudi 和 Delta 库都是默认预加载,不再需要环境变量
DATALAKE_FORMATS。在 AWS Glue 4.0 之前,环境变量DATALAKE_FORMATS用于指定应加载哪些特定表格式。
上述列表与 Docker 映像相关。要了解有关 AWS Glue 5.0 更新的更多信息,请参阅 Introducing AWS Glue 5.0 for Apache Spark
注意事项
请记住,使用 AWS Glue 容器映像在本地开发作业脚本时,不支持以下功能。
-
AWS Glue Parquet 写入器(在 AWS Glue 中使用 Parquet 格式)
-
用于从 Amazon S3 路径加载 JDBC 驱动程序的属性 customJdbcDriverS3Path
-
AWS Lake Formation 基于权限的凭证售卖
附录:添加 JDBC 驱动程序和 Java 库
要添加容器中当前不可用的 JDBC 驱动程序,可以在工作空间下创建包含所需 JAR 文件的新目录,然后在 docker run 命令中将该目录挂载到 /opt/spark/jars/。在容器内的 /opt/spark/jars/ 下找到的 JAR 文件会自动添加到 Spark Classpath 中,并可在作业运行期间使用。
例如,使用以下 docker run 命令将 JDBC 驱动程序 jar 添加到 PySpark REPL shell 中。
docker run -it --rm \ -v ~/.aws:/home/hadoop/.aws \ -v $WORKSPACE_LOCATION:/home/hadoop/workspace/ \ -v $WORKSPACE_LOCATION/jars/:/opt/spark/jars/ \ --workdir /home/hadoop/workspace \ -e AWS_PROFILE=$PROFILE_NAME \ --name glue5_jdbc \ public.ecr.aws/glue/aws-glue-libs:5 \ pyspark
正如注意事项中强调的那样,customJdbcDriverS3Path 连接选项不能用于在 AWS Glue 容器映像中从 Amazon S3 导入自定义 JDBC 驱动程序。
