数据质量定义语言(DQDL)引用
数据质量定义语言(DQDL)是一种特定领域的语言,用于定义 AWS Glue Data Quality 规则。
本指南介绍了关键的 DQDL 概念,以帮助您理解该语言。它还通过语法和示例为 DQDL 规则类型提供了参考。在使用本指南之前,我们建议您熟悉 AWS Glue Data Quality。有关更多信息,请参阅 AWS Glue Data Quality。
注意
只有 AWS Glue ETL 支持动态规则。
目录
DL 语法
DQDL 文档区分大小写,并包含一个规则集,该规则集将各个数据质量规则组合在一起。要构造规则集,必须创建一个名为 Rules(大写)的列表,由一对方括号分隔。该列表应包含一个或多个以逗号分隔的 DQDL 规则,如下例所示。
Rules = [ IsComplete "order-id", IsUnique "order-id" ]
规则结构
DQDL 规则的结构取决于规则类型。但是,DQDL 规则通常符合以下格式。
<RuleType> <Parameter> <Parameter> <Expression>
RuleType 是要配置的规则类型的区分大小写名称。例如,IsComplete、IsUnique 或 CustomSql。每种规则类型的规则参数都不同。有关 DQDL 规则类型及其参数的完整参考,请参阅DL 规则类型引用。
复合规则
DQDL 支持以下逻辑运算符,您可以使用这些运算符来组合规则。这些规则被称为复合规则。
- 以及
-
当且仅当逻辑
and运算符连接的规则为true,逻辑运算符才会产生结果true。否则,组合规则将导致false。与and运算符连接的每条规则都必须用圆括号括起来。以下示例使用
and运算符将两个 DL 规则组合。(IsComplete "id") and (IsUnique "id") - 或者
-
当且仅当逻辑
or运算符连接的一个或多个规则为true,逻辑运算符才会产生结果true。与or运算符连接的每条规则都必须用圆括号括起来。以下示例使用
or运算符将两个 DL 规则组合。(RowCount "id" > 100) or (IsPrimaryKey "id")
您可以使用同一个运算符连接多个规则,因此允许使用以下规则组合。
(Mean "Star_Rating" > 3) and (Mean "Order_Total" > 500) and (IsComplete "Order_Id")
您可以将逻辑运算符组合成一个表达式。例如:
(Mean "Star_Rating" > 3) and ((Mean "Order_Total" > 500) or (IsComplete "Order_Id"))
您还可以编写更复杂的嵌套规则。
(RowCount > 0) or ((IsComplete "colA") and (IsUnique "colA"))
复合规则的工作原理
默认情况下,复合规则将作为整个数据集或表中的单个规则进行评估,然后合并结果。换句话说,它会首先评估整列,然后应用运算符。下面举例说明这种默认行为:
# Dataset +------+------+ |myCol1|myCol2| +------+------+ | 2| 1| | 0| 3| +------+------+ # Overall outcome +----------------------------------------------------------+-------+ |Rule |Outcome| +----------------------------------------------------------+-------+ |(ColumnValues "myCol1" > 1) OR (ColumnValues "myCol2" > 2)|Failed | +----------------------------------------------------------+-------+
在上面的示例中,AWS Glue Data Quality 会首先评估会导致失效的 (ColumnValues "myCol1" > 1)。然后它将评估同时也会出现失效的 (ColumnValues "myCol2" > 2)。两个结果的组合将被标记为 FAILED。
但是,如果您更喜欢与 SQL 类似的行为,即需要评估整行,则必须显式设置 ruleEvaluation.scope 参数,如下面代码片段中的 additionalOptions 所示。
object GlueApp { val datasource = glueContext.getCatalogSource( database="<db>", tableName="<table>", transformationContext="datasource" ).getDynamicFrame() val ruleset = """ Rules = [ (ColumnValues "age" >= 26) OR (ColumnLength "name" >= 4) ] """ val dq_results = EvaluateDataQuality.processRows( frame=datasource, ruleset=ruleset, additionalOptions=JsonOptions(""" { "compositeRuleEvaluation.method":"ROW" } """ ) ) }
在 AWS Glue Data Catalog 中,您可以在用户界面中轻松配置此选项,如下所示。
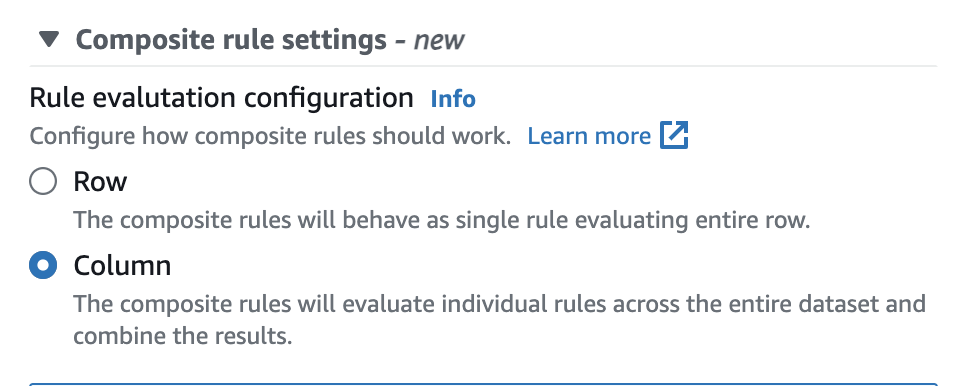
设置完成后,复合规则将作为评估整行的单个规则运行。以下示例说明了此行为。
# Row Level outcome +------+------+------------------------------------------------------------+---------------------------+ |myCol1|myCol2|DataQualityRulesPass |DataQualityEvaluationResult| +------+------+------------------------------------------------------------+---------------------------+ |2 |1 |[(ColumnValues "myCol1" > 1) OR (ColumnValues "myCol2" > 2)]|Passed | |0 |3 |[(ColumnValues "myCol1" > 1) OR (ColumnValues "myCol2" > 2)]|Passed | +------+------+------------------------------------------------------------+---------------------------+
此功能不支持某些规则,因为其总体结果依赖阈值或比率。不支持的规则列举如下。
依赖比率的规则:
-
完整性
-
DatasetMatch
-
ReferentialIntegrity
-
独特性
依赖阈值的规则:
当以下规则包含阈值时,则不支持这些规则。但是,不涉及 with threshold 的规则仍受支持。
-
ColumnDataType
-
ColumnValues
-
CustomSQL
Expressions
如果规则类型不生成布尔响应,则必须提供表达式作为参数才能创建布尔响应。例如,以下规则根据表达式检查列中所有值的均值(平均值),以返回真或假结果。
Mean "colA" between 80 and 100
某些规则类型(例如 IsUnique 和 IsComplete)已经返回布尔响应。
下表列出了您可在 DL 规则中使用的表达式。
| Expression | 描述 | 示例 |
|---|---|---|
=x |
如果规则类型响应等于 x,则解析为 true。 |
|
!=x |
x 如果规则类型响应不等于 x,则解析为 true。 |
|
> x |
如果规则类型响应大于 x,则解析为 true。 |
|
< x |
如果规则类型响应小于 x,则解析为 true。 |
|
>= x |
如果规则类型响应大于 x,则解析为 true。 |
|
<= x |
如果规则类型响应小于或等于 x,则解析为 true。 |
|
介于 x 与 y 之间 |
如果规则类型响应在指定范围内(不包括),则解析为 true。仅将此表达式类型用于数字和日期类型。 |
|
not between x and y |
如果规则类型响应不在指定范围内(包括首尾数),则解析为 true。您只能将此表达式类型用于数字和日期类型。 |
|
在 [a, b, c, ...] 中 |
如果规则类型响应在指定的集合中,则解析为 true。 |
|
not in [a, b, c, ...] |
如果规则类型响应不在指定的集合中,则解析为 true。 |
|
匹配 /ab+c/i |
如果规则类型响应与正则表达式匹配,则解析为 true。 |
|
not matches /ab+c/i |
如果规则类型响应与正则表达式不匹配,则解析为 true。 |
|
now() |
仅适用于创建日期表达式的 ColumnValues 规则类型。 |
|
matches/in […]/not matches/not in [...] with threshold |
指定符合规则条件的值的百分比。仅适用于 ColumnValues、ColumnDataType 和 CustomSQL 规则类型。 |
|
NULL、EMPTY 和 WHITESPACE_ONLY 的关键字
如果要验证字符串列是否为零、空或属于仅包含空格的字符串,则可以使用以下关键字:
-
NULL/null – 对于字符串列中的
null值,此关键字解析为 true。如果超过 50% 的数据没有零值,则
ColumnValues "colA" != NULL with threshold > 0.5将返回 true。对于所有具有零值或长度大于 5 的行,
(ColumnValues "colA" = NULL) or (ColumnLength "colA" > 5)都将返回 true。请注意,这将需要使用“compositeRuleEvaluation.method” = “ROW”选项。 -
EMPTY/empty – 对于字符串列中的空字符串(“”)值,此关键字将解析为 true。某些数据格式会将字符串列中的零值转换为空字符串。此关键字有助于过滤掉数据中的空字符串。
如果一行为空、“a”或“b”,
(ColumnValues "colA" = EMPTY) or (ColumnValues "colA" in ["a", "b"])将返回 true。请注意,这需要使用“compositeRuleEvaluation.method” = “ROW”选项。 -
WHITESPACES_ONLY /whitespaces_only – 对于字符串列中只有空格(“ ”)值的字符串,此关键字解析为 true。
如果一行既不是“a”或“b”,也不只是空格,
ColumnValues "colA" not in ["a", "b", WHITESPACES_ONLY]将返回 true。支持的规则:
对于基于数值或日期的表达式,如果要验证列是否包含零值,则可以使用以下关键字。
-
NULL/null – 对于字符串列中的零值,此关键字解析为 true。
如果列中的日期为
2023-01-01或零,ColumnValues "colA" in [NULL, "2023-01-01"]将返回 true。对于所有具有零值或值介于 1 到 9 之间的行,
(ColumnValues "colA" = NULL) or (ColumnValues "colA" between 1 and 9)都将返回 true。请注意,这将需要使用“compositeRuleEvaluation.method” = “ROW”选项。支持的规则:
使用 Where 子句进行筛选
注意
仅 AWS Glue 4.0 中支持 Where 子句。
您可以在编写规则时筛选数据。当您想要应用条件规则时,这会很有用。
<DQDL Rule> where "<valid SparkSQL where clause> "
必须使用 where 关键字指定筛选条件,后跟一个用引号 ("") 括起有效 SparkSQL 语句。
如果您希望将 where 子句添加到具有阈值的规则中,则应在指定阈值条件之前指定 where 子句。
<DQDL Rule> where "valid SparkSQL statement>" with threshold <threshold condition>
您可以使用此语法编写如下规则。
Completeness "colA" > 0.5 where "colB = 10" ColumnValues "colB" in ["A", "B"] where "colC is not null" with threshold > 0.9 ColumnLength "colC" > 10 where "colD != Concat(colE, colF)"
我们将验证所提供的 SparkSQL 语句是否有效。如果无效,规则评估将失败,我们将按照以下格式引发 IllegalArgumentException:
Rule <DQDL Rule> where "<invalid SparkSQL>" has provided an invalid where clause : <SparkSQL Error>
启用行级错误记录识别时的 where 子句行为
借助 AWS Glue 数据质量自动监测功能,您可以识别失败的特定记录。将 where 子句应用于支持行级结果的规则时,我们会将 where 子句筛选出的行标记为 Passed。
如果您希望将筛选出的行单独标记为 SKIPPED,则可以为 ETL 作业设置以下 additionalOptions。
object GlueApp { val datasource = glueContext.getCatalogSource( database="<db>", tableName="<table>", transformationContext="datasource" ).getDynamicFrame() val ruleset = """ Rules = [ IsComplete "att2" where "att1 = 'a'" ] """ val dq_results = EvaluateDataQuality.processRows( frame=datasource, ruleset=ruleset, additionalOptions=JsonOptions(""" { "rowLevelConfiguration.filteredRowLabel":"SKIPPED" } """ ) ) }
请参阅以下规则和数据框作为示例:
IsComplete att2 where "att1 = 'a'"
| id | att1 | att2 | 行级结果(默认) | 行级结果(跳过的选项) | 注释 |
|---|---|---|---|---|---|
| 1 | a | f | PASSED | PASSED | |
| 2 | b | d | PASSED | SKIPPED | 行已被筛选出,因为 att1 不是 "a" |
| 3 | a | null | FAILED | FAILED | |
| 4 | a | f | PASSED | PASSED | |
| 5 | b | null | PASSED | SKIPPED | 行已被筛选出,因为 att1 不是 "a" |
| 6 | a | f | PASSED | PASSED |
动态规则
注意
动态规则仅在 AWS Glue ETL 中受支持,在 AWS Glue Data Catalog 中不受支持。
现在,您可以编写动态规则,将规则生成的当前指标与其历史值进行比较。这些历史比较通过在表达式中使用 last() 运算符启用。例如,当前运行中的行数大于同一数据集之前最近一次的行数时,RowCount >
last() 规则就会成功。last() 采用一个可选的自然数参数,描述要考虑的先前指标数量;k
>= 1 将引用的最后一个 k 指标 last(k)。
-
如果没有可用的数据点,
last(k)将返回默认值 0.0。 -
如果少于可用的
k指标,则last(k)将返回所有之前的指标。
要形成有效的表达式,请使用 last(k),其中 k > 1 需要聚合函数以将多个历史结果简化为单个数字。例如,RowCount > avg(last(5)) 将检查当前数据集的行数是否严格大于同一数据集最后五行计数的平均值。RowCount > last(5) 将产生错误,因为无法将当前数据集的行数与列表进行有意义的比较。
支持的聚合函数:
-
avg -
median -
max -
min -
sum -
std(标准偏差) -
abs(绝对值) -
index(last(k), i)将允许从最后一个k中选择第i最新的值。i为零索引,因此index(last(3), 0)将返回最新的数据点,并且index(last(3), 3)将导致错误,因为只有三个数据点,而我们尝试编制第四最新数据点的索引。
示例表达式
ColumnCorrelation
ColumnCorrelation "colA" "colB" < avg(last(10))
DistinctValuesCount
DistinctValuesCount "colA" between min(last(10))-1 and max(last(10))+1
大多数具有数字条件或阈值的规则类型都支持动态规则;请参阅提供的分析器和规则表,以确定您的规则类型是否支持动态规则。
从动态规则中排除统计信息
有时,您需要从动态规则计算中排除数据统计信息。假设您加载了历史数据,但不希望其影响您的平均值。为此,请在 AWS Glue ETL 中打开作业并选择数据质量选项卡,然后依次选择统计信息和要排除的统计信息。您将能够看到趋势图和统计表。选择要排除的值,然后选择排除统计信息。排除的统计信息将不会包含在动态规则计算中。

分析器
注意
AWS Glue Data Catalog 不支持分析器。
DQDL 规则使用名为分析器的功能收集有关您的数据的信息。规则的布尔表达式使用此信息确定规则应该成功还是失败。例如,RowCount 规则 RowCount > 5 将使用行计数分析器发现数据集中的行数,并将其与表达式 > 5 进行比较,以检查当前数据集中是否存在超过五行。
有时,我们建议创建分析器(而不是编写规则),然后让其生成可用于检测异常的统计信息。对于此类实例,您可以创建分析器。分析器在以下方面与规则不同。
| 特征 | 分析器 | 规则 |
|---|---|---|
| 规则集的一部分 | 是 | 是 |
| 生成统计信息 | 是 | 是 |
| 生成观测值 | 是 | 是 |
| 可以评估和断言条件 | 否 | 是 |
| 您可以配置操作,例如在失败时停止作业、继续处理作业 | 否 | 是 |
分析器无需规则即可独立存在,因此您可以快速配置分析器并逐步构建数据质量规则。
可以在规则集的 Analyzers 块中输入某些规则类型,以运行分析器所需的规则并收集信息,而无需对任何条件进行检查。有些分析器与规则无关,只能在 Analyzers 块中输入。下表显示每个项目是作为规则还是作为独立分析器支持,以及每种规则类型的其他详细信息。
带分析器的示例规则集
以下规则集使用:
-
一条动态规则,用于检查数据集在过去三次作业运行中,是否增长超过其尾随平均值
-
DistinctValuesCount分析器,用于记录数据集Name列中不同值的数量 -
ColumnLength分析器,用于跟踪一段时间内最小和最大Name大小
可以在作业运行的“数据质量”选项卡中,查看分析器指标结果。
Rules = [ RowCount > avg(last(3)) ] Analyzers = [ DistinctValuesCount "Name", ColumnLength "Name" ]
AWS Glue 数据质量自动监测功能支持以下分析器。
| 分析器名称 | 功能 |
|---|---|
RowCount |
计算数据集的行数 |
Completeness |
计算列的完整性百分比 |
Uniqueness |
计算列的唯一性百分比 |
Mean |
计算数字列的平均值 |
Sum |
计算数字列的总和 |
StandardDeviation |
计算数字列的标准差 |
Entropy |
计算数字列的熵 |
DistinctValuesCount |
计算列中独特值的数量 |
UniqueValueRatio |
计算列中的唯一值比率 |
ColumnCount |
计算数据集中的列数 |
ColumnLength |
计算列的长度 |
ColumnValues |
计算数字列的最小值和最大值。计算非数字列的最小列长和最大列长 |
ColumnCorrelation |
计算给定列的列相关性 |
CustomSql |
计算 CustomSQL 返回的统计信息 |
AllStatistics |
计算以下统计信息:
|
注释
您可以使用“#”字符在 DQDL 文档中添加注释。DQDL 会忽略在“#”字符之后以及直到行尾的任何内容。
Rules = [ # More items should generally mean a higher price, so correlation should be positive ColumnCorrelation "price" "num_items" > 0 ]
