本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
RANDOM_CUT_FOREST_WITH_EXPLANATION
计算异常分数并针对数据流中的每条记录解释此分数。记录的异常分数指示它与最近针对流观察到的趋势有多大的不同。该函数还根据记录中每一列的数据的异常程度,返回对应列的归因分数。对于每条记录,所有列的归因分数总和等于异常分数。
您还可以选择获取有关给定列为异常的方向的信息(相对于对流中给定列最近观察到的数据趋势,该分数是高还是低)。
例如,在电子商务应用中,您可能想知道最近观察到的交易模式何时发生变化。您可能还想知道变化在多大程度上是由于每小时购买数量的变化而引起的,在多大程度上是由于每小时放弃的购物车数量的变化而引起的,这些是归因分数表示的信息。您可能还需要查看方向性,以了解是否会由于上述每个值的增加或减少而收到有关更改的通知。
注意
RANDOM_CUT_FOREST_WITH_EXPLANATION 函数检测异常的能力取决于应用程序。要确定业务问题以便通过此函数解决,需要具备领域专业知识。例如,您可能需要确定输入流中的哪些列组合传递给此函数,并且您可能因对数据规范化而受益。有关更多信息,请参阅 inputStream。
流记录可以有非数字列,但该函数仅使用数字列来分配异常分数。一条记录可以有一个或多个数字列。算法使用所有数值数据来计算异常分数。
当您启动应用程序时,该算法开始使用流中的当前记录开发机器学习模型。该算法不使用流中较旧的记录进行机器学习,也不使用来自应用程序的之前执行的统计数据。
该算法接受 DOUBLE、INTEGER、FLOAT、TINYINT、SMALLINT、REAL 和 BIGINT 数据类型。
注意
DECIMAL 不是受支持的类型。请改用 DOUBLE。
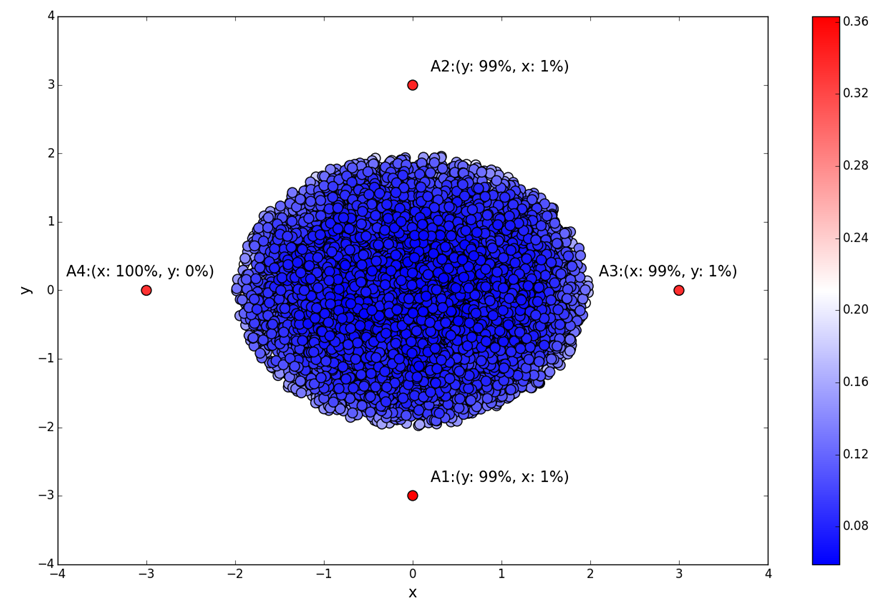
以下是在二维空间中使用不同归因分数进行异常检测的简单直观示例。该图显示了一个由蓝色数据点组成的集群和四个显示为红点的异常值。红点具有相似的异常分数,但这四个点异常的原因不同。对于点 A1 和 A2,异常在极大程度上归因于它们的离心 y 值。对于 A3 和 A4,您可以在极大程度上将异常归因于它们的离心 x 值。方向性为:A1 的 y 值为 LOW(低),A2 的 y 值为 HIGH(高),A3 的 x 值为 HIGH(高),A4 的 x 值为 LOW(低)。
语法
RANDOM_CUT_FOREST_WITH_EXPLANATION (inputStream, numberOfTrees, subSampleSize, timeDecay, shingleSize, withDirectionality )
参数
以下部分介绍 RANDOM_CUT_FOREST_WITH_EXPLANATION 函数的参数。
inputStream
指向输入流的指针。您可以使用 CURSOR 函数设置指针。例如,以下语句将设置指向 InputStream 的指针。
CURSOR(SELECT STREAM * FROM InputStream) CURSOR(SELECT STREAM IntegerColumnX, IntegerColumnY FROM InputStream) -– Perhaps normalize the column X value. CURSOR(SELECT STREAM IntegerColumnX / 100, IntegerColumnY FROM InputStream) –- Combine columns before passing to the function. CURSOR(SELECT STREAM IntegerColumnX - IntegerColumnY FROM InputStream)
CURSOR 函数是 RANDOM_CUT_FOREST_WITH_EXPLANATION 函数的唯一必需参数。该函数假设其他参数的默认值如下:
numberOfTrees = 100
subSampleSize = 256
timeDecay = 100,000
shingleSize = 1
withDirectionality = FALSE
使用此函数时,输入流最多可以有 30 个数值列。
numberOfTrees
使用此参数,您可以指定森林中随机砍伐的树木数量。
注意
默认情况下,该算法会构造许多树,每棵树都是使用输入流中给定数量的样本记录(请参阅本列表后面的 subSampleSize)构造的。该算法使用每棵树来分配异常分数。所有这些分数的平均值是最终的异常分数。
numberOfTrees 的默认值为 100。您可以将此值设置为介于 1 和 1000 之间(含 1 和 1000)。通过增加森林中树的数量,您可以获得异常分数和归因分数的更准确估算,但这也会延长运行时间。
subSampleSize
使用此参数,您可以指定在构造每棵树时希望算法使用的随机样本的大小。森林中每棵树都是使用记录的一个(不同的)随机样本构建的。该算法使用每棵树来分配异常分数。当样本达到 subSampleSize 条记录时,会随机删除记录,较旧记录的删除概率高于较新记录。
subSampleSize 的默认值为 256。您可以将此值设置为介于 10 和 1,000 之间(含 10 和 1,000)。
subSampleSize 必须小于 timeDecay 参数(默认情况下设置为 100,000)。增大样本大小将为每棵树提供更大的数据视图,但它也会延长运行时间。
注意
在训练机器学习模型时,算法为首批 subSampleSize 个记录返回零。
timeDecay
您可以使用 timeDecay 参数指定计算异常分数时要考虑过去的多长时间。数据流会随着时间的推移而自然演变。例如,随着时间的推移,电子商务网站的收入可能会不断增加,或者全球温度可能会逐渐升高。在这种情况下,您希望根据最近的数据而不是遥远过去的数据来标记异常。
默认值为 100000 条记录(如果使用瓦形,则为 100000 个瓦形,如下一节所述)。您可以将此值设置为介于 1 和最大整数(即 2147483647)之间。该算法以指数方式降低了旧数据的重要性。
如果您选择 timeDecay 的默认值 100000,则异常检测算法将执行以下操作:
-
在计算中仅使用最近的 100000 条记录(并忽略较早的记录)。
-
在最近的 100000 条记录中,进行异常检测计算时,近期记录的权重呈指数级增长,而较早记录的权重则呈指数级下降。
timeDecay 参数决定了在异常检测算法的工作集中保留的最大最近记录数量。如果数据改变得很快,则需要较小的 timeDecay 值。怎样的 timeDecay 值最合适取决于应用程序。
shingleSize
此处给出的说明适用于一维流(即,只有一个数值列的流),但瓦形也可用于多维流。
瓦形是最近记录的连续序列。例如,时间 t 处大小为 10 的 shingleSize 对应于截至时间 t(含该时间)收到的最后 10 条记录的向量。该算法将此序列视为跨最后 shingleSize 条记录的向量。
如果数据以统一的时间到达,则时间 t 处大小为 10 的瓦形对应于在时间 t-9、t-8、…、t 处收到的数据。在时间 t+1 处,瓦形跨一个单位滑动,且包含来自时间 t-8、t-7、…、t、t+1 的数据。随着时间的推移收集的这些瓦形记录对应于一个 10 维向量集合,异常检测算法将对该集合运行。
直觉告诉我们,瓦形可以捕获近期的形状。您的数据可能有典型的形状。例如,如果您的数据是每小时收集一次,大小为 24 的瓦形可以捕获您的数据的每日节奏。
默认 shingleSize 是一个记录(因为瓦形大小取决于数据)。您可以将此值设置为介于 1 和 30 之间(含 1 和 30)。
请注意有关设置 shingleSize 的以下内容:
-
如果将
shingleSize设置得过小,算法更容易受数据的细微波动的影响,从而导致并非异常的记录获得高异常分数。 -
如果将
shingleSize设置得过大,则可能需要更多时间来检测异常记录,因为非异常的瓦形中有更多记录。此外,还可能需要更多时间才能确定异常已经结束。 -
确定正确的瓦形大小取决于应用程序。使用不同的瓦形大小进行实验来确定效果。
withDirectionality
默认为 false 的布尔参数。设置为 true 时,它会告诉您每个维度对异常分数的贡献方向。它还提供了针对该方向性的推荐强度。
结果
该函数返回 0 或更高的异常分数,并返回 JSON 格式的解释。
当算法进入学习阶段时,流中所有记录的异常分数从 0 开始。然后,您开始看到异常分数的正值。并非所有正的异常分数都是重要的;只有最高的分数才是重要的。为了更好地理解结果,请查看解释。
该解释为记录中的每个列提供了以下值:
-
归因分数:指示此列对记录的异常分数的贡献程度的非负数。换句话说,它表示此列的值与基于最近观察到的趋势的预期值有多大的不同。记录的所有列的归因分数总和等于异常分数。
-
强度:表示方向推荐强度的非负数。强度值高,表示对函数返回的方向性具有高的置信度。在学习阶段,强度为 0。
-
方向性:如果列的值高于最近观察到的趋势,则为 HIGH(高);如果低于趋势,则为 LOW(低)。在学习阶段,此值默认为 LOW(低)。
注意
当 Kinesis Data Analytics 服务进行服务维护时,机器学习功能用于确定分析分数的趋势很少会被重置。发生服务维护后,您可能意外地看到分析分数为 0。我们建议您设置筛选条件或其他机制,以便在这些值出现时适当地处理它们。
示例
股票代码数据示例
此示例基于样本股票数据集,后者是 Amazon Kinesis Analytics 开发人员指南中的入门练习的一部分。要运行此示例,您需要一个具有样本股票代码输入流的 Kinesis Data Analytics 应用程序。要了解如何创建 Kinesis Data Analytics 应用程序和配置样本股票代码输入流,请参阅 Amazon Kinesis Data Analytics 开发人员指南中的入门。
样本股票数据集的架构如下:
(ticker_symbol VARCHAR(4), sector VARCHAR(16), change REAL, price REAL)
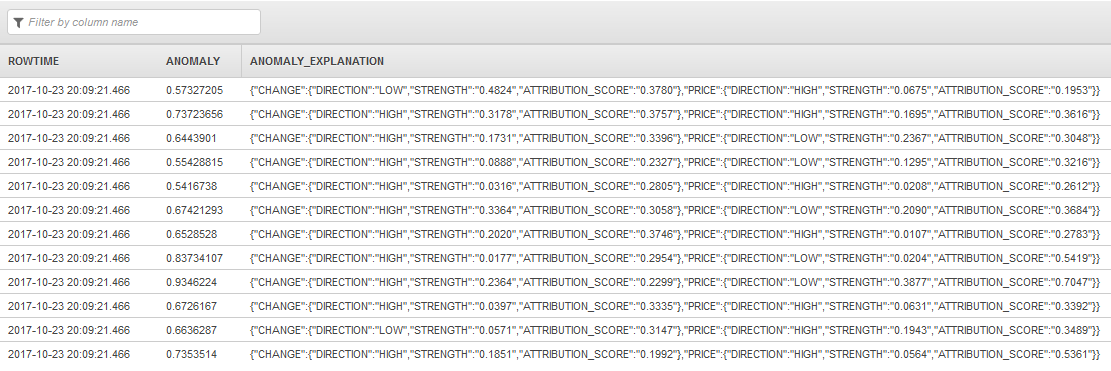
在此示例中,应用程序为记录计算异常分数,并为 PRICE 和 CHANGE 列计算归因分数,这些是输入流中仅有的数值列。
CREATE OR REPLACE STREAM "DESTINATION_SQL_STREAM" (anomaly REAL, ANOMALY_EXPLANATION VARCHAR(20480)); CREATE OR REPLACE PUMP "STREAM_PUMP" AS INSERT INTO "DESTINATION_SQL_STREAM" SELECT "ANOMALY_SCORE", "ANOMALY_EXPLANATION" FROM TABLE (RANDOM_CUT_FOREST_WITH_EXPLANATION(CURSOR(SELECT STREAM * FROM "SOURCE_SQL_STREAM_001"), 100, 256, 100000, 1, true)) WHERE ANOMALY_SCORE > 0
上一示例输出的流与以下内容类似。
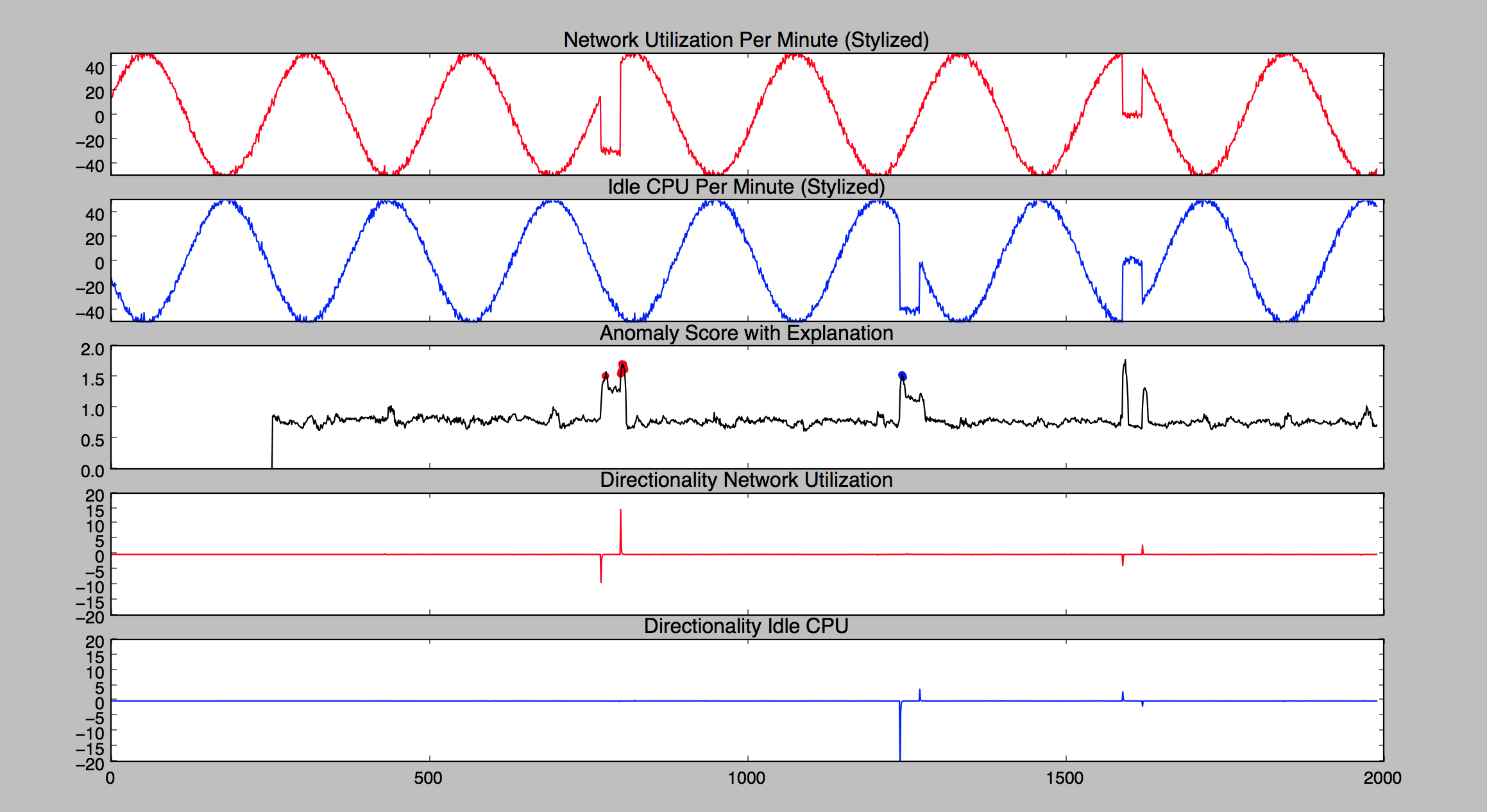
网络和 CPU 利用率示例
本理论示例显示了两组遵循振荡模式的数据。在下图中,它们由顶部的红色曲线和蓝色曲线表示。红色曲线显示随时间推移的网络利用率,蓝色曲线显示同一计算机系统随时间推移的闲置 CPU。这两个彼此有相位差的信号在大多数时间是有规律的。但它们都显示偶尔的异常,这些异常在图表中显示为不规则。下面解释图形中的曲线所表示的内容(按从顶部曲线到底部曲线的顺序)。
顶部曲线为红色,表示随时间推移的网络利用率。它遵循循环模式,大部分时间是有规律的,除了两个异常期间(每个期间都表示利用率下降)之外。第一个异常期间发生在时间值 500 到 1,000 之间。第二个异常期间发生在时间值 1,500 到 2,000 之间。
顶部的第二条曲线(蓝色)是随着时间推移的空闲 CPU。它遵循循环模式,大部分时间是有规律的,除了两个异常期间之外。第一个异常期间发生在时间值 1,000 到 1,500 之间,并显示空闲 CPU 时间下降。第二个异常期间发生在时间值 1,500到 2,000 之间,并显示空闲 CPU 时间增加。
顶部的第三条曲线显示异常分数。在开始时,有一个学习阶段,此时异常分数为 0。在学习阶段之后,曲线上有稳定的噪声,但异常很突出。
第一个异常在黑色异常分数曲线上以红色标记,它更多地归因于网络利用率数据。第二个异常标记为蓝色,它更多地归因于 CPU 数据。此图中提供红色和蓝色标记以更好地显示效果。它们不是由
RANDOM_CUT_FOREST_WITH_EXPLANATION函数生成的。以下是获得这些红色和蓝色标记的方法:运行函数后,我们选择了前 20 个异常分数值。
从这个前 20 个异常分数值的集合中,我们选择其网络利用率归因大于或等于 CPU 归因的 1.5 倍的那些值。我们在图中使用红色标记来给此新值集中的点着色。
-
我们使用蓝色标记对其 CPU 归因分数大于或等于网络利用率归因分数的 1.5 倍的点进行着色。
底部的第二条曲线是网络利用率信号方向性的图形表示。我们通过以下方法获得此曲线:运行此函数,将强度乘以 -1 以表示 LOW(低)方向性,乘以 +1 以表示 HIGH(高)方向性,并根据时间绘制结果。
当网络利用率的周期性模式下降时,方向性会出现相应的负峰值。当网络利用率显示回升到常规模式时,方向性显示与该升高幅度相对应的正峰值。后来,出现了另一个负峰值,紧接着是另一个正峰值。它们共同表示网络利用率曲线中出现的第二个异常。
底部曲线是 CPU 信号方向性的图形表示。我们通过以下方法获得此曲线:将强度乘以 -1 以表示 LOW(低)方向性,乘以 +1 以表示 HIGH(高)方向性,并根据时间绘制结果。
对于空闲 CPU 曲线中的第一个异常,此方向性曲线会显示一个负峰值,随后立即出现一个较小的正峰值。空闲 CPU 曲线中的第二个异常产生正峰值,然后产生一个方向性负峰值。
血压示例
有关更详细的示例以及检测和解释血压读数异常的代码,请参阅示例:检测数据异常并获取解释。
