适用于 Apache Flink 的亚马逊托管服务(亚马逊 MSF)以前被称为适用于 Apache Flink 的亚马逊 Kinesis Data Analytics。
本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
什么是 Apache Flink 的亚马逊托管服务?
借助适用于 Apache Flink 的亚马逊托管服务,你可以使用 Java、Scala、Python 或 SQL 来处理和分析流数据。该服务使您能够针对流媒体源和静态源编写和运行代码,以执行时间序列分析、提供实时仪表板和指标。
您可以使用基于 Apache Flink 的开源库在 Apache Flink 托管服务中使用自己选择的语言构建应用程序。
Managed Service for Apache Flink为您的 Apache Flink 应用程序提供底层基础设施。它处理核心功能,例如配置计算资源、可用区故障转移弹性、并行计算、自动扩展和应用程序备份(以检查点和快照的形式实现)。您可以使用高级 Flink 编程功能(如运算符、函数、源和接收器),使用方法与您自行托管 Flink 基础设施时一样。
决定使用适用于 Apache Flink 的托管服务还是用于 Apache Flink Studio 的托管服务
使用适用于 Apache Flink 的亚马逊托管服务运行 Flink 作业有两种选择。使用适用于 Apache Flink 的托管服务,您可以使用自己选择的 IDE 和 Apache Flink 数据流或表使用 Java、Scala 或 Python(以及嵌入式 SQL)构建 Flink 应用程序。 APIs借助适用于 Apache Flink Studio 的托管服务,您可以实时交互式查询数据流,并使用标准 SQL、Python 和 Scala 轻松构建和运行流处理应用程序。
您可以选择最适合您的用例的方法。如果您不确定,本节将提供高级指导来帮助您。
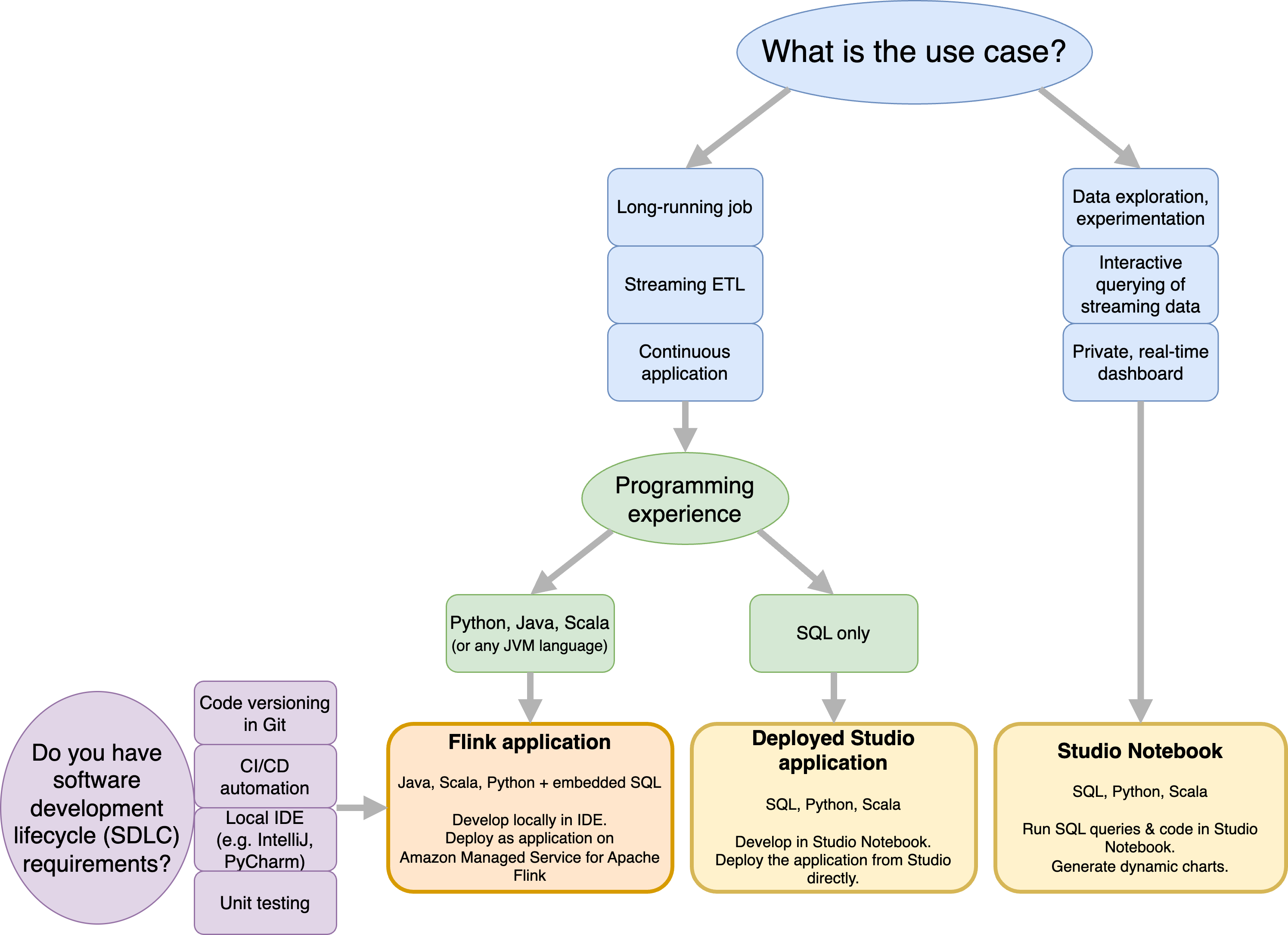
在决定使用适用于 Apache Flink 的亚马逊托管服务还是使用适用于 Apache Flink Studio 的亚马逊托管服务之前,您应该考虑自己的用例。
如果您计划运行长时间运行的应用程序来承担流式传输 ETL 或连续应用程序等工作负载,则应考虑使用适用于 Apache Flink 的托管服务。这是因为您可以 APIs 直接在自己选择的 IDE 中使用 Flink 创建 Flink 应用程序。使用 IDE 进行本地开发还可以确保您可以利用软件开发生命周期 (SDLC) 的常见流程和工具,例如 Git 中的代码版本控制、CI/CD 自动化或单元测试。
如果您对临时数据探索感兴趣,想要以交互方式查询流数据或创建私有实时仪表板,那么适用于 Apache Flink Studio 的托管服务只需点击几下即可帮助您实现这些目标。熟悉 SQL 的用户可以考虑直接从 Studio 部署长时间运行的应用程序。
注意
您可以将 Studio 笔记本升级为长时间运行的应用程序。但是,如果您想与 SDLC 工具(例如 Git 上的代码版本控制和 CI/CD 自动化)或单元测试等技术集成,我们建议使用您选择的 IDE 进行适用于 Apache Flink 的托管服务。
选择要在 Apache Flink APIs 的托管服务中使用哪个 Apache Flink
你可以在自己选择的 IDE 中使用 Apache Flink 在 Apache Flink 的托管服务 APIs 中使用 Java、Python 和 Scala 构建应用程序。您可以在文档中找到有关如何使用 Flink 数据流和表 API 构建应用程序的指南。您可以选择创建 Flink 应用程序时使用的语言以及最 APIs 能满足应用程序和操作需求的语言。如果您不确定,本节将提供高级指导来帮助您。
选择一个 Flink API
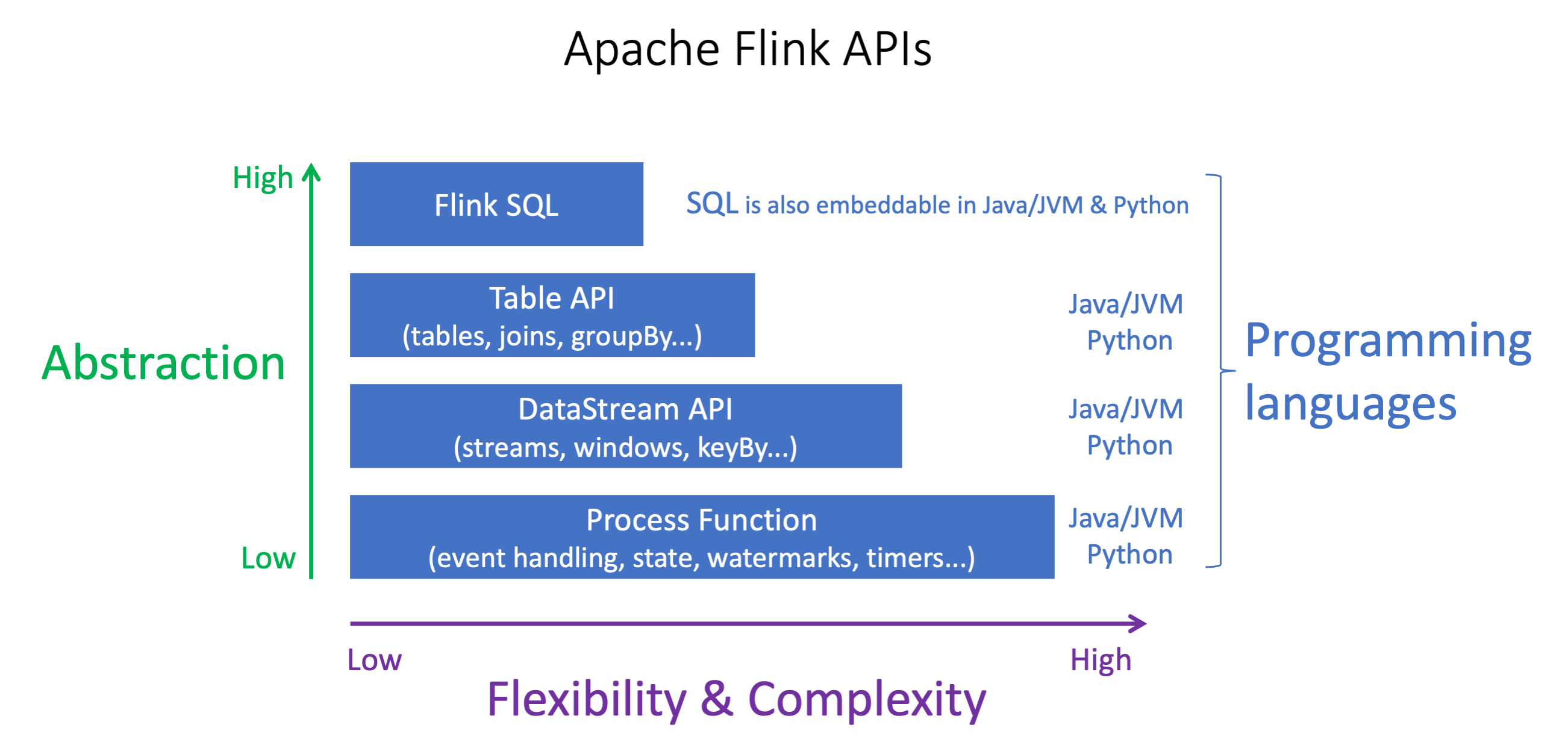
Apache Flink APIs 具有不同的抽象级别,这可能会影响你决定如何构建应用程序。它们富有表现力和灵活性,可以一起使用来构建您的应用程序。您不必只使用一个 Flink API。你可以在 Apache Flink 文档 APIs 中了解有关 Fl
Flink 提供四个级别的 API 抽象:Flink SQL、Table DataStream API、API 和与 API 配合使用的流程函数。 DataStream 适用于 Apache Flink 的亚马逊托管服务均支持这些内容。建议尽可能从更高级别的抽象开始,但是有些 Flink 功能仅在 Datastream API 中可用,您可以在其中使用 Java、Python 或 Scala 创建应用程序。在以下情况下,您应该考虑使用 Datastream API:
你需要对状态进行精细的控制
你想利用异步调用外部数据库或端点的功能(例如用于推理)
你想使用自定义计时器(例如,实现自定义窗口或后期事件处理)
-
您希望能够在不重置状态的情况下修改应用程序的流程
注意
使用 DataStream API 选择语言:
无论选择哪种编程语言,SQL 都可以嵌入到任何 Flink 应用程序中。
如果你打算使用 DataStream API,那么 Python 并不支持所有连接器。
如果你需要 low-latency/high-throughput you should consider Java/Scala 不管 API 如何。
如果您计划在 Process Functions API 中使用异步 IO,则需要使用 Java。
API 的选择还会影响您在不必重置状态的情况下改进应用程序逻辑的能力。这取决于一项特定的功能,即在运算符上设置 UID 的功能,该功能仅在 Java 和 Python DataStream 的 API 中都可用。有关更多信息,请参阅 Apache Flink 文档中的设置 UUIDs 为所有运算符
开始使用流数据应用程序
您可以从创建持续读取和处理流数据的 Managed Service for Apache Flink应用程序开始。然后,使用所选的 IDE 编写代码,并使用实时流数据对其进行测试。您还可以配置 Managed Service for Apache Flink 要将结果发送到的目标。
首先,我们建议您阅读以下章节:
或者,您可以先创建一个适用于 Apache Flink Studio 的托管服务,该笔记本允许您以交互方式实时查询数据流,并使用标准 SQL、Python 和 Scala 轻松构建和运行流处理应用程序。只需在中单击几下 AWS Management Console,即可启动无服务器笔记本来查询数据流并在几秒钟内获得结果。首先,我们建议您阅读以下章节:
