本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
使用 Amazon Textract 从 PDF 文件中自动提取内容
贾天霞,亚马逊 Web Services
摘要
许多组织需要从上传至其业务应用程序的 PDF 文件中提取信息。例如,组织可能需要准确地从税务或医疗 PDF 文件中提取用于税务分析或医疗索赔处理的信息。
在 Amazon Web Services (AWS) Cloud 上,Amazon Textract 会自动从 PDF 文件中提取信息(例如已打印文本、表单和表格),并生成包含原始 PDF 文件信息的 JSON 格式文件。您可以在 AWS 管理控制台 中使用 Amazon Textract,也可以通过 API 调用使用。建议使用编程 API 调用
当 Amazon Textract 处理文件时,它会创建以下 Block 对象列表:页面、文本行和单词、表单(键值对)、表格和单元格以及选择元素。还包括其他对象信息,例如边界框、置信区间和关系。 IDsAmazon Textract 将提取字符串形式的内容信息。需要正确识别和转换数据值,以便下游应用程序更轻松的使用。
此模式描述了使用 Amazon Textract 自动从 PDF 文件中提取内容并将其处理成干净输出 step-by-step的工作流程。此模式使用模板匹配技术正确识别必填字段、密钥名称和表,然后对每种数据类型进行后期处理更正。您可以使用此模式处理不同类型的 PDF 文件,然后可以扩展和自动化此工作流程,以处理相同格式的 PDF 文件。
先决条件和限制
先决条件
一个有效的 Amazon Web Services account。
用于存储待转换为 JPEG 格式以供 Amazon Textract 处理的 PDF 文件的现有 Amazon Simple Storage Service(Amazon S3) 存储桶。有关 S3 存储桶的更多信息,请参阅 Amazon S3 文档中的存储桶概述。
Textract_PostProcessing.ipynbJupyter 笔记本(附件),已安装并配置。有关 Jupyter 笔记本的更多信息,请参阅亚马逊文档中的创建 Jupyter 笔记本。 SageMaker格式相同的现有 PDF 文件。
了解 Python。
限制
您的 PDF 文件必须质量良好、且清晰可读。建议使用原生 PDF 文件,但如果所有单词均清晰可见,则可以使用转换至 PDF 格式的扫描文档。有关这方面的更多信息,请参阅 AWS 机器学习博客上的使用 Amazon Textract 预处理 PDF 文档:视觉效果检测和删除
。 对于多页文件,您可以使用异步操作,或将 PDF 文件拆分为单个页面并使用同步操作。有关这两个选项的更多信息,请参阅 Amazon Textract 文档中的检测和分析多页文档的文本和检测和分析单页文档的文本。
架构
此模式的工作流程是首先在示例 PDF 文件上运行 Amazon Textract(首次运行),然后在与首个 PDF 文件相同格式的 PDF 文件上运行(重复运行)。下图显示了首次运行和重复运行的组合工作流程,该工作流程自动重复地从相同格式的 PDF 文件中提取内容。
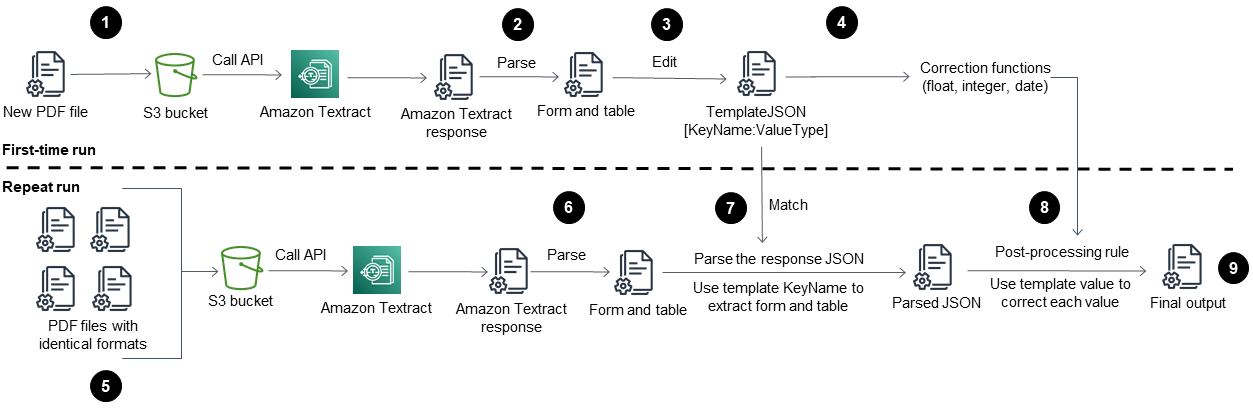
图表显示了此模式的以下工作流程:
将 PDF 文件转换为 JPEG 格式,并将其存储在 S3 存储桶中。
调用 Amazon Textract API 并解析 Amazon Textract 响应 JSON 文件。
通过为每个必填字段添加正确的
KeyName:DataType对编辑 JSON 文件。为重复运行阶段创建TemplateJSON文件。为每种数据类型(例如浮点数、整数和日期)定义后处理校正函数。
准备与首个 PDF 文件格式相同的 PDF 文件。
调用 Amazon Textract API 并解析 Amazon Textract 响应 JSON。
将已解析 JSON 文件与
TemplateJSON文件相匹配。实施后期处理校正。
最终的 JSON 输出文件包含了每个必需字段的正确 KeyName 和 Value。
目标技术堆栈
Amazon SageMaker
Amazon S3
Amazon Textract
自动化和扩缩
您可以使用 AWS Lambda 函数自动执行重复运行工作流程,该函数会在新的 PDF 文件添加至 Amazon S3 中时启动 Amazon Textract。然后,Amazon Textract 会运行处理脚本,并将最终输出保存至存储位置。有关这方面的更多信息,请参阅 Lambda 文档中的使用 Amazon S3 触发器调用 Lambda 函数。
工具
Amazon SageMaker 是一项完全托管的机器学习服务,可帮助您快速轻松地构建和训练机器学习模型,然后将其直接部署到可用于生产的托管环境中。
Amazon Simple Storage Service (Amazon S3) 是一项基于云的对象存储服务,可帮助您存储、保护和检索任意数量的数据。
Amazon Textract 可以轻松地将文档文本检测和分析添加至您的应用程序。
操作说明
| Task | 描述 | 所需技能 |
|---|---|---|
转换 PDF 文件。 | 为首次运行准备 PDF 文件,方式为将 PDF 文件拆分为单页,并将其转换为适合 Amazon Textract 同步操作( 注意您也可以对多页 PDF 文件使用 Amazon Textract 异步操作 ( | 数据科学家,开发人员 |
解析 Amazon Textract 响应 JSON。 | 打开
使用以下代码将响应 JSON 解析为表单与表格:
| 数据科学家,开发人员 |
编辑 TemplateJSON 文件。 | 对每个 此模板用于每种单独的 PDF 文件类型,这意味着该模板可重复用于相同格式的 PDF 文件。 | 数据科学家,开发人员 |
定义后处理校正函数。 | Amazon Textract 对 使用以下代码根据
| 数据科学家,开发人员 |
| Task | 描述 | 所需技能 |
|---|---|---|
准备 PDF 文件。 | 准备 PDF 文件,方式为将 PDF 文件拆分为单页,并将其转换为适合 Amazon Textract 同步操作 ( 注意您也可以对多页 PDF 文件使用 Amazon Textract 异步操作 ( | 数据科学家,开发人员 |
调用 Amazon Textract API。 | 使用以下代码调用 Amazon Textract API:
| 数据科学家,开发人员 |
解析 Amazon Textract 响应 JSON。 | 使用以下代码将响应 JSON 解析为表单与表格:
| 数据科学家,开发人员 |
加载 templateJSON 文件并使其与已解析 JSON 匹配。 | 通过以下命令使用
| 数据科学家,开发人员 |
后期处理校正。 | 在
| 数据科学家,开发人员 |
相关资源
附件
要访问与此文档相关联的其他内容,请解压以下文件:attachment.zip
