本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
使用 Amazon Redshift ML 执行高级分析
Po Hong 和 Chyanna Antonio,Amazon Web Services
摘要
在 Amazon Web Services (AWS) Cloud,您可使用 Amazon Redshift machine learning (Amazon Redshift ML) 对存储在 Amazon Redshift cluster 或 Amazon Simple Storage Service (Amazon S3) 的数据执行机器学习分析。Amazon Redshift ML 支持有监督学习,这种学习常用于高级分析。Amazon Redshift ML 用例包括收入预测、信用卡欺诈检测以及客户生命周期价值 (CLV) 或客户流失预测。
Amazon Redshift ML 使数据库用户可以轻松地使用标准的 SQL 命令创建、训练和部署 ML 模型。Amazon Redshift ML 使用 Amazon A SageMaker utopilot 自动训练和调整最佳机器学习模型,以便根据您的数据进行分类或回归,同时保持控制和可见性。
亚马逊 Redshift、Amazon S3 和亚马逊之间的所有交互 SageMaker 都被抽象出来并实现了自动化。ML 模型经过训练和部署后,它将作为用户定义函数 (UDF) 在 Amazon Redshift 中使用,并可用于 SQL 查询。
此模式补充了 AWS 博客中的 “使用 SQL 在 Amazon Redshift 中创建、训练和部署机器学习模型
先决条件和限制
先决条件
一个有效的 Amazon Web Services account
Amazon Redshift 表内现有数据
技能
熟悉 Amazon Redshift ML 使用的术语和概念,包括机器学习、培训和预测。有关这方面的更多信息,请参阅 Amazon Machine Learning (Amazon ML) 文档中的ML 模型培训。
体验 Amazon Redshift 用户设置、访问管理以及标准 SQL 语法。有关的更多信息,请参阅 Amazon Redshift 文档中的 Amazon Redshift 入门。
Amazon S3 和 AWS Identity and Acess Management (IAM) 方面的专长和经验。
在 AWS 命令行界面(AWS CLI)中运行命令也是有益的,但不是必需的。
限制
Amazon Redshift 集群与 S3 存储桶必须位于同一 AWS 区域。
此模式方法仅支持有监督学习模型,例如回归、二进制分类以及多类分类。
架构
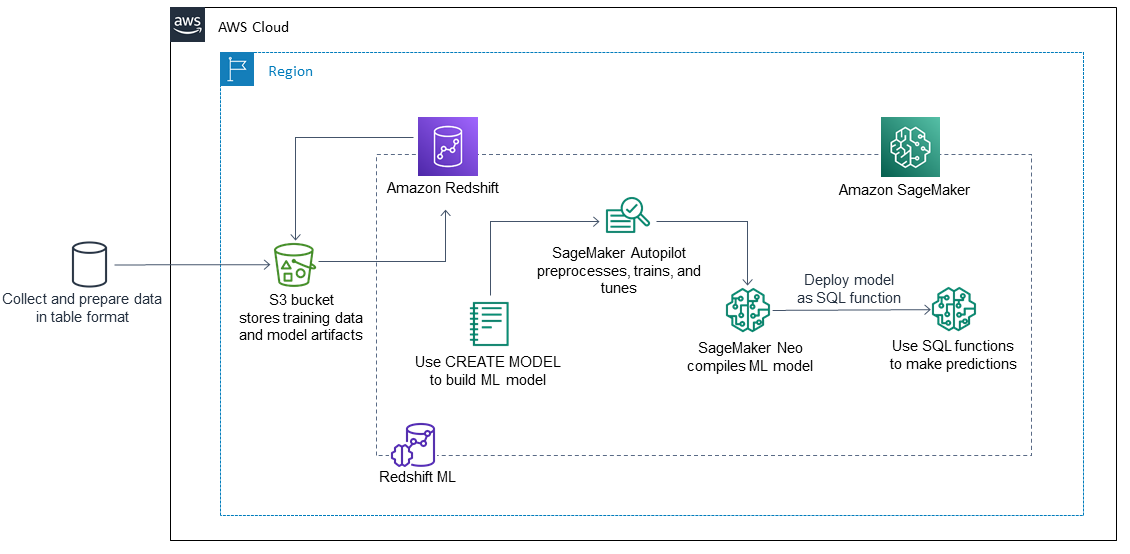
以下步骤说明了 Amazon Redshift 机器学习如何使用 SageMaker 来构建、训练和部署机器学习模型:
Amazon Redshift 将训练数据导出到 S3 存储桶中。
SageMaker Autopilot 会自动预处理训练数据。
调用该
CREATE MODEL语句后,Amazon Redshift ML 将 SageMaker 用于训练。SageMaker Autopilot 搜索并推荐用于优化评估指标的机器学习算法和最佳超参数。
Amazon Redshift ML 会在 Amazon Redshift 集群中将输出 ML 模型注册为 SQL 函数。
ML 模型的函数可用于 SQL 语句。
技术堆栈
Amazon Redshift
SageMaker
Amazon S3
工具
Amazon Redshift – Amazon Redshift 是一种完全托管的企业 PB 级数据仓库服务。
Amazon Redshift ML – Amazon Redshift 机器学习 (Amazon Redshift ML) 是一种基于云的稳健服务,能够让所有技能水平的分析人员和数据科学家都能轻松使用 ML 技术。
Amazon S3 – Amazon Simple Storage Service (Amazon S3) 是一项面向互联网的存储服务。
Amazon SageMaker — SageMaker 是一项完全托管的机器学习服务。
Amazon A SageMaker uto SageMaker pil ot — Autopilot 是一款功能集,可自动执行自动机器学习 (AutoML) 过程中的关键任务。
代码
您可使用以下代码,在 Amazon Redshift 中创建受监管的 ML 模型:
"CREATE MODEL customer_churn_auto_model FROM (SELECT state, account_length, area_code, total_charge/account_length AS average_daily_spend, cust_serv_calls/account_length AS average_daily_cases, churn FROM customer_activity WHERE record_date < '2020-01-01' ) TARGET churn FUNCTION ml_fn_customer_churn_auto IAM_ROLE 'arn:aws:iam::XXXXXXXXXXXX:role/Redshift-ML' SETTINGS ( S3_BUCKET 'your-bucket' );")
注意
该SELECT州可以参考亚马逊 Redshift 常规表、亚马逊 Redshift Spectrum 外部表,或两者兼而有之。
操作说明
| Task | 描述 | 所需技能 |
|---|---|---|
准备训练与测试数据集。 | 登录 AWS 管理控制台并打开亚马逊 SageMaker 控制台。按照构建、训练和部署机器学习模型 注意我们建议您将原始数据集进行洗牌并拆分为用于模型训练的训练集(70%)和用于模型性能评估的测试集(30%)。 | 数据科学家 |
| Task | 描述 | 所需技能 |
|---|---|---|
创建和配置 Amazon Redshift 集群。 | 在 Amazon Redshift 控制台,根据您的要求创建集群。有关更多信息,请参阅 Amazon Redshift 文档中的创建集群。 重要必须使用 | 数据库管理员、云架构师 |
创建 S3 存储桶以存储训练数据和模型构件。 | 在 Amazon S3 控制台,创建 S3 存储桶以训练和测试数据。有关创建 S3 存储桶的更多信息,请参阅 AWS 快速入门中的创建 S3 存储桶。 重要确保您的 Amazon Redshift 集群和 S3 存储桶位于同一区域。 | 数据库管理员、云架构师 |
创建 IAM policy,并将其附加至 Amazon Redshift 集群。 | 创建 IAM 策略以允许 Amazon Redshift 集群访问 SageMaker 和亚马逊 S3。有关说明和步骤,请参阅 Amazon Redshift 文档中的使用 Amazon Redshift ML 的集群设置。 | 数据库管理员、云架构师 |
允许 Amazon Redshift 用户和群组访问架构和表格。 | 授予权限,允许 Amazon Redshift 中的用户和群组访问内部和外部架构和表格。有关步骤和说明,请参阅 Amazon Redshift 文档的管理权限和所有权。 | 数据库管理员 |
| Task | 描述 | 所需技能 |
|---|---|---|
在 Amazon Redshift 中创建和训练 ML 模型。 | 在 Amazon Redshift ML 中创建和训练您的 ML 模型。有关更多信息,请参阅 Amazon Redshift 文档中的 | 开发人员、数据科学家 |
| Task | 描述 | 所需技能 |
|---|---|---|
使用生成的 ML 模型函数执行推理。 | 有关使用生成 ML 模型函数执行推理的更多信息,请参阅 Amazon Redshift 文档中的预测。 | 数据科学家、商业智能用户 |
相关资源
准备训练与测试数据集
准备与配置技术堆栈
在 Amazon Redshift 中创建和训练 ML 模型
在 Amazon Redshift 中执行批量推理与预测
其他资源
