本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
用例:预测患者预后和再入院率
人工智能驱动的预测分析通过预测患者疗效和实现个性化治疗计划来提供更多好处。这可以提高患者的满意度和健康结果。通过将这些 AI 功能与 Amazon Bedrock 和其他技术集成,医疗保健提供商可以显著提高工作效率、降低成本并提高患者护理的整体质量。
您可以将医疗数据(例如患者病史、临床记录、药物和治疗方法)存储在知识图
此解决方案可帮助您预测重新入院的可能性。这些预测可以改善患者的预后并降低医疗成本。该解决方案还可以帮助医院临床医生和管理人员将注意力集中在再入院风险较高的患者身上。它还可以通过警报、自助服务和数据驱动的行动,帮助他们主动干预这些患者。
解决方案概述
该解决方案使用多检索器检索增强生成 (RAG) 框架来分析患者数据。它可以预测个别患者再次入院的可能性,并帮助您计算医院级别的再入院倾向评分。该解决方案集成了以下功能:
-
知识图表 — 存储按时间顺序排列的结构化患者数据,例如医院就诊情况、以前的再入院情况、症状、实验室结果、处方治疗和药物依从性历史记录
-
矢量数据库 — 存储非结构化临床数据,例如出院摘要、医生记录以及错过预约或报告的药物副作用的记录
-
经过微调的法学硕士 — 使用知识图谱中的结构化数据和来自矢量数据库的非结构化数据,以得出有关患者行为、治疗依从性和再入院可能性的推断
风险评分模型将法学硕士的推论量化为数字分数。您可以将分数汇总为医院级别的再入院倾向分数。该分数定义了每位患者的风险敞口,您可以定期或根据需要进行计算。所有推断和风险评分都已编制索引并存储在 Amazon S OpenSearch ervice 中,以便护理经理和临床医生可以对其进行检索。通过将对话式 AI 代理与该矢量数据库集成,临床医生和护理经理可以无缝提取个人患者级别、机构范围或医学专业的见解。您还可以根据风险评分设置自动警报,以鼓励主动干预。
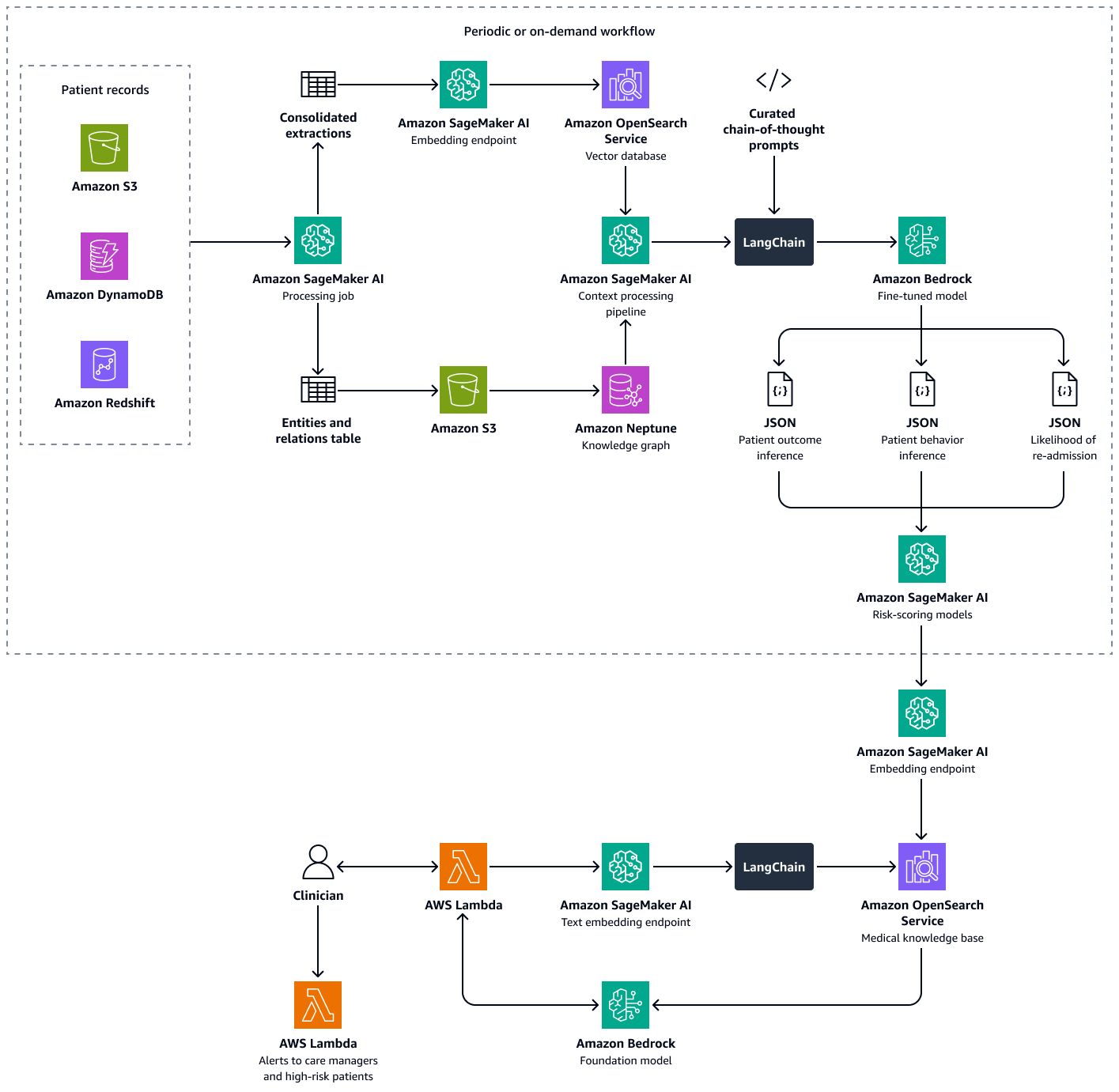
构建此解决方案包括以下步骤:
第 1 步:使用医学知识图谱预测患者预后
在 Amazon Neptune 中,您可以使用知识图来存储一段时间内有关患者就诊和结果的时间知识。构建和存储知识图谱的最有效方法是使用图模型和图形数据库。图形数据库专为存储和浏览关系而构建。图形数据库可以更轻松地对高度互联的数据进行建模和管理,并具有灵活的架构。
知识图可帮助您执行时间序列分析。以下是图表数据库中用于患者预后的时间预测的关键元素:
-
历史数据 — 患者先前的诊断、持续服药、以前使用的药物和实验室结果
-
患者就诊(按时间顺序)— 就诊日期、症状、观察到的过敏症、临床记录、诊断、手术、治疗、处方药和实验室结果
-
症状和临床参数 — 临床和基于症状的信息,包括严重程度、进展模式和患者对药物的反应
你可以利用医学知识图谱中的见解来微调 Amazon Bedrock 中的法学硕士,例如 Llama 3。你可以使用关于患者在一段时间内对一组药物或治疗的反应的顺序患者数据来微调法学硕士。使用带有标签的数据集,该数据集将一组药物或治疗方法以及患者与诊所的互动数据分为预定义的类别,以表明患者的健康状况。这些类别的例子包括健康状况恶化、改善或稳定进展。当临床医生输入有关患者及其症状的新背景时,经过微调的法学硕士可以使用训练数据集中的模式来预测潜在的患者预后。
下图显示了使用医疗保健专用训练数据集在 Amazon Bedrock 中微调 LLM 所涉及的顺序步骤。这些数据可能包括一段时间内患者的健康状况和对治疗的反应。该训练数据集将帮助模型对患者预后做出广义预测。
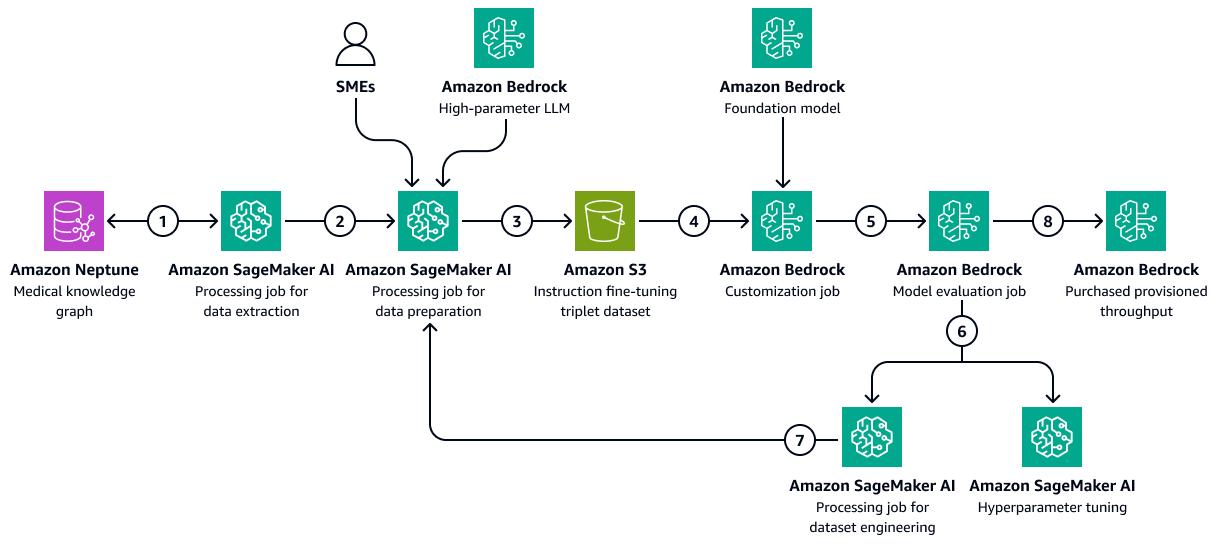
图表显示了以下工作流:
-
Amazon SageMaker AI 数据提取任务查询知识图表,以检索按时间顺序排列的数据,了解不同患者在一段时间内对一组药物或治疗的反应。
-
SageMaker 人工智能数据准备工作整合了 Amazon Bedrock LLM 和主题专家的意见 () SMEs。该工作将从知识图谱中检索到的数据分为预定义的类别(例如健康状况恶化、改善或稳定进展),这些类别表明了每位患者的健康状况。
-
该工作创建了一个微调数据集,其中包括从知识图谱中提取的信息、 chain-of-thought提示和患者结果类别。它会将此训练数据集上传到 Amazon S3 存储桶。
-
Amazon Bedrock 自定义任务使用此训练数据集来微调 LLM。
-
Amazon Bedrock 定制工作集成了训练环境中首选的 Amazon Bedrock 基础模型。它启动微调作业,并使用您配置的训练数据集和训练超参数。
-
Amazon Bedrock 评估工作使用预先设计的模型评估框架对经过微调的模型进行评估。
-
如果模型需要改进,则在仔细考虑训练数据集后,训练作业将使用更多数据重新运行。如果模型没有显示出性能的增量改进,也可以考虑修改训练超参数。
-
在模型评估符合业务利益相关者定义的标准后,您可以将经过微调的模型托管到 Amazon Bedrock 预配置的吞吐量。
第 2 步:预测患者对处方药或治疗的行为
Fine-tuned LLMs 可以处理临床记录、出院摘要和其他来自临时医学知识图的患者特定文档。他们可以评估患者是否可能服用处方药或治疗。
此步骤使用中创建的知识图谱第 1 步:使用医学知识图谱预测患者预后。知识图谱包含来自患者档案的数据,包括作为节点的患者历史依从性。它还包括药物或治疗不依从性、药物副作用、药物缺乏途径或成本壁垒,或者给药方案复杂等情况,这些都是这些节点的属性。
Fine-tuned LLMs 可以使用医学知识图谱中过去的处方配送数据和亚马逊 OpenSearch 服务矢量数据库中临床记录的描述性摘要。这些临床记录可能会提及经常错过预约或不遵守治疗。法学硕士可以使用这些注释来预测未来不遵守的可能性。
-
按如下方式准备输入数据:
-
结构化数据 — 从医学知识图中提取最近的患者数据,例如最近三次就诊和实验室结果。
-
非结构化数据 — 从 Amazon S OpenSearch ervice 矢量数据库中检索最近的临床记录。
-
-
创建包含患者病史和当前背景的输入提示。以下是提示示例:
You are a highly specialized AI model trained in healthcare predictive analytics. Your task is to analyze a patient's historical medical records, adherence patterns, and clinical context to predict the **likelihood of future non-adherence** to prescribed medications or treatments. ### **Patient Details** - **Patient ID:** {patient_id} - **Age:** {age} - **Gender:** {gender} - **Medical Conditions:** {medical_conditions} - **Current Medications:** {current_medications} - **Prescribed Treatments:** {prescribed_treatments} ### **Chronological Medical History** - **Visit Dates & Symptoms:** {visit_dates_symptoms} - **Diagnoses & Procedures:** {diagnoses_procedures} - **Prescribed Medications & Treatments:** {medications_treatments} - **Past Adherence Patterns:** {historical_adherence} - **Instances of Non-Adherence:** {past_non_adherence} - **Side Effects Experienced:** {side_effects} - **Barriers to Adherence (e.g., Cost, Access, Dosing Complexity):** {barriers} ### **Patient-Specific Insights** - **Clinical Notes & Discharge Summaries:** {clinical_notes} - **Missed Appointments & Non-Compliance Patterns:** {missed_appointments} ### **Let's think Step-by-Step to predict the patient behaviour** 1. You should first analyze past adherence trends and patterns of non-adherence. 2. Identify potential barriers, such as financial constraints, medication side effects, or complex dosing regimens. 3. Thoroughly examine clinical notes and documented patient behaviors that may hint at non-adherence. 4. Correlate adherence history with prescribed treatments and patient conditions. 5. Finally predict the likelihood of non-adherence based on these contextual insights. ### **Output Format (JSON)** Return the prediction in the following structured format: ```json { "patient_id": "{patient_id}", "likelihood_of_non_adherence": "{low | moderate | high}", "reasoning": "{detailed_explanation_based_on_patient_history}" } -
将提示传递给经过微调的 LLM。法学硕士处理提示并预测结果。以下是 LLM 的回复示例:
{ "patient_id": "P12345", "likelihood_of_non_adherence": "high", "reasoning": "The patient has a history of missed appointments, has reported side effects to previous medications. Additionally, clinical notes indicate difficulty following complex dosing schedules." } -
解析模型的响应以提取预测的结果类别。例如,上一步中示例响应的类别可能是不遵守的可能性很高。
-
(可选)使用模型对数或其他方法来分配置信度分数。对数是属于某个类别或类别的项目的非标准化概率。
第 3 步:预测患者再次入院的可能性
由于医疗管理成本高昂以及对患者健康的影响,重新入院是一个主要问题。计算再入院率是衡量患者护理质量和医疗保健提供者绩效的一种方法。
为了计算再入学率,您定义了一个指标,例如 7 天再入学率。该指标是在出院后七天内返回医院进行计划外就诊的住院患者的百分比。为了预测患者再次入院的机会,经过微调的法学硕士可以使用你在中创建的医学知识图谱中的时间数据。第 1 步:使用医学知识图谱预测患者预后该知识图按时间顺序保存了患者遭遇、手术、药物和症状的记录。这些数据记录包含以下内容:
-
自患者上次出院以来的持续时间
-
患者对过去治疗和药物的反应
-
随着时间的推移,症状或病情的进展
您可以处理这些时间序列事件,通过精心策划的系统提示来预测患者再次入院的可能性。该提示将预测逻辑传递给经过微调的 LLM。
-
按如下方式准备输入数据:
-
依从性历史记录 — 从医学知识图中提取药物取药日期、药物补充频率、诊断和用药详情、按时间顺序排列的病史以及其他信息。
-
行为指标 — 检索并包括有关错过预约和患者报告的副作用的临床记录。
-
-
创建包含依从历史记录和行为指标的输入提示。以下是提示示例:
You are a highly specialized AI model trained in healthcare predictive analytics. Your task is to analyze a patient's historical medical records, clinical events, and adherence patterns to predict the **likelihood of hospital readmission** within the next few days. ### **Patient Details** - **Patient ID:** {patient_id} - **Age:** {age} - **Gender:** {gender} - **Primary Diagnoses:** {diagnoses} - **Current Medications:** {current_medications} - **Prescribed Treatments:** {prescribed_treatments} ### **Chronological Medical History** - **Recent Hospital Encounters:** {encounters} - **Time Since Last Discharge:** {time_since_last_discharge} - **Previous Readmissions:** {past_readmissions} - **Recent Lab Results & Vital Signs:** {recent_lab_results} - **Procedures Performed:** {procedures_performed} - **Prescribed Medications & Treatments:** {medications_treatments} - **Past Adherence Patterns:** {historical_adherence} - **Instances of Non-Adherence:** {past_non_adherence} ### **Patient-Specific Insights** - **Clinical Notes & Discharge Summaries:** {clinical_notes} - **Missed Appointments & Non-Compliance Patterns:** {missed_appointments} - **Patient-Reported Side Effects & Complications:** {side_effects} ### **Reasoning Process – You have to analyze this use case step-by-step.** 1. First assess **time since last discharge** and whether recent hospital encounters suggest a pattern of frequent readmissions. 2. Second examine **recent lab results, vital signs, and procedures performed** to identify clinical deterioration. 3. Third analyze **adherence history**, checking if past non-adherence to medications or treatments correlates with readmissions. 4. Then identify **missed appointments, self-reported side effects, or symptoms worsening** from clinical notes. 5. Finally predict the **likelihood of readmission** based on these contextual insights. ### **Output Format (JSON)** Return the prediction in the following structured format: ```json { "patient_id": "{patient_id}", "likelihood_of_readmission": "{low | moderate | high}", "reasoning": "{detailed_explanation_based_on_patient_history}" } -
将提示传递给经过微调的 LLM。法学硕士处理提示并预测重新录取的可能性和原因。以下是 LLM 的回复示例:
{ "patient_id": "P67890", "likelihood_of_readmission": "high", "reasoning": "The patient was discharged only 5 days ago, has a history of more than two readmissions to hospitals where the patient received treatment. Recent lab results indicate abnormal kidney function and high liver enzymes. These factors suggest a medium risk of readmission." } -
将预测归类为标准化尺度,例如低、中或高。
-
查看法学硕士学位提供的推理,并确定有助于预测的关键因素。
-
将定性输出映射到定量分数。例如,非常高可能等于 0.9 的概率。
-
使用验证数据集根据实际再入学率校准模型输出。
第 4 步:计算再入院倾向分数
接下来,计算每位患者的再入院倾向分数。该分数反映了在前面步骤中进行的三项分析的净影响:潜在的患者预后、患者对药物和治疗的行为以及患者再次入院的可能性。通过将患者层面的再入院倾向分数汇总到专业级别,然后汇总到医院层面,您可以获得临床医生、护理经理和管理人员的见解。再入院倾向评分可帮助您按机构、专业或病情评估整体表现。然后,你可以使用这个分数来实施主动干预。
-
为每个不同的因素(结果预测、依从可能性、重新入院)分配权重。以下是权重示例:
-
结果预测权重:0.4
-
依从性预测权重:0.3
-
再入院可能性权重:0.3
-
-
使用以下计算方法计算综合分数:
ReadadmissionPropensityScore= (OutcomeScore×OutcomeWeight) + (AdherenceScore×AdherenceWeight) + (ReadmissionLikelihoodScore×ReadmissionLikelihoodWeight) -
确保所有个人分数都采用相同的等级,例如 0 到 1。
-
定义操作阈值。例如,分数高于 0.7 会启动警报。
根据上述分析和患者的再入院倾向评分,临床医生或护理经理可以设置警报,根据计算得出的分数对个别患者进行监测。如果超过预定义的阈值,则在达到该阈值时会通知他们。这有助于护理管理人员在为患者制定出院护理计划时积极主动而不是被动。以索引形式将患者的预后、行为和再入院倾向分数保存在 Amazon S OpenSearch ervice 矢量数据库中,以便护理经理可以使用对话式 AI 代理无缝检索这些分数。
下图显示了对话式 AI 代理的工作流程,临床医生或护理经理可以使用该代理来检索有关患者预后、预期行为和再入院倾向的见解。用户可以在患者层面、部门层面或医院层面检索见解。AI 代理会检索这些见解,这些见解以索引形式存储在 Amazon Serv OpenSearch ice 矢量数据库中。该代理使用查询来检索相关数据,并提供量身定制的响应,包括为再次入院风险高的患者建议的措施。根据风险程度,代理人还可以为患者和护理人员设置提醒。
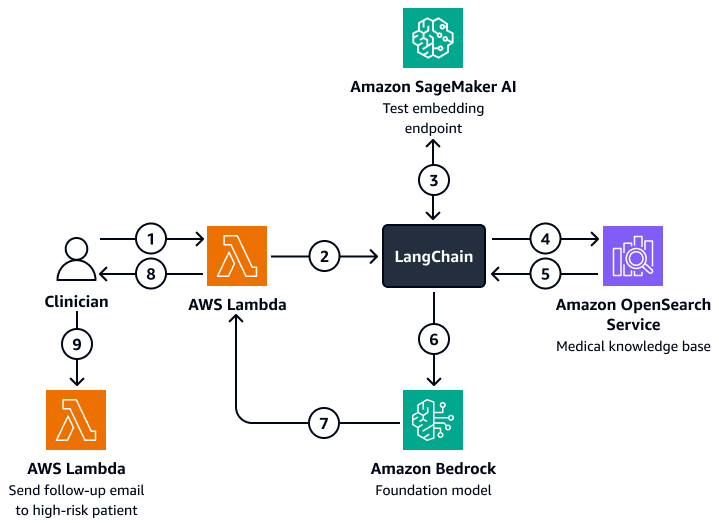
图表显示了以下工作流:
-
临床医生向对话式 AI 代理提出问题,该代理包含一个 AWS Lambda 功能。
-
Lambda 函数启动一个 LangChain 代理人。
-
这些区域有:LangChain 代理将用户的问题发送到 Amazon A SageMaker I 文本嵌入端点。端点嵌入了问题。
-
这些区域有:LangChain 代理将嵌入式问题传递到 Amazon OpenSearch 服务中的医学知识库。
-
Amazon Ser OpenSearch vice 会将与用户查询最相关的具体见解返回给 LangChain 代理人。
-
这些区域有:LangChain 代理将查询和检索到的上下文从知识库发送到 Amazon Bedrock 基础模型。
-
Amazon Bedrock 基础模型生成响应并将其发送到 Lambda 函数。
-
Lambda 函数将响应返回给临床医生。
-
临床医生启动 Lambda 函数,向再次入院风险高的患者发送一封后续电子邮件。
与 Well-Architect AWS ed 框架保持一致
用于跟踪患者行为和预测医院再入院率的架构整合了医学知识图表 AWS 服务,并在 LLMs 与 Well-Arch AWS itected Framework 的六大支柱保持一致的同时改善医疗结果:
-
卓越运营 — 该解决方案是一个独立的自动化系统,它使用 Amazon Bedrock 并发出实时 AWS Lambda 警报。
-
安全 — 此解决方案旨在遵守医疗保健法规,例如 HIPAA。您还可以实施加密、精细访问控制和 Amazon Bedrock 护栏,以帮助保护患者数据。
-
可靠性-该架构使用容错、无服务器。 AWS 服务
-
性能效率 — Amazon Service 和经过微调的 OpenSearch 服务 LLMs 可以提供快速而准确的预测。
-
成本优化 — 无服务器技术和 pay-per-inference模型有助于最大限度地降低成本。尽管使用微调的 LLM 可能会产生额外费用,但该模型使用 RAG 方法,可以减少微调过程所需的数据和计算时间。
-
可持续性 — 该架构通过使用无服务器基础架构,最大限度地减少了资源消耗。它还支持高效、可扩展的医疗保健运营。
