本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
用例:管理和提高医护人员的技能
实施人才转型和技能提升策略可以帮助员工保持在医疗和医疗保健服务中使用新技术和实践的能力。积极的技能提升计划可确保医疗保健专业人员能够提供高质量的患者护理,优化运营效率并遵守监管标准。此外,人才转型促进了持续学习的文化。这对于适应不断变化的医疗保健格局和应对新出现的公共卫生挑战至关重要。传统的培训方法,例如课堂培训和静态学习模块,可为广大受众提供统一的内容。他们通常缺乏个性化的学习路径,而这对于满足个别从业者的特定需求和熟练程度至关重要。这种 one-size-fits-all策略可能导致脱离接触和知识保留率不理想。
因此,医疗保健组织必须采用创新、可扩展和技术驱动的解决方案,以确定每位员工在当前状态和潜在的未来状态下的差距。这些解决方案应推荐高度个性化的学习途径和正确的学习内容集。这有效地让员工为医疗保健的未来做好了准备。
在医疗保健行业,你可以应用生成式人工智能来帮助你了解和提高员工的技能。通过大型语言模型 (LLMs) 和高级检索器的连接,组织可以了解他们目前拥有的技能,并确定将来可能需要的关键技能。这些信息可帮助您通过雇用新员工和提高现有员工的技能来弥合差距。使用 Amazon Bedrock 和知识图表,医疗保健组织可以开发特定领域的应用程序,以促进持续学习和技能发展。
此解决方案提供的知识可帮助您有效地管理人才、优化员工绩效、推动组织成功、识别现有技能和制定人才战略。此解决方案可以帮助您在几周而不是几个月内完成这些任务。
解决方案概述
该解决方案是一个医疗保健人才转型框架,由以下部分组成:
-
智能简历解析器 — 该组件可以读取候选人的简历并精确提取候选人信息,包括技能。智能信息提取解决方案使用 Amazon Bedrock 中经过微调的 Llama 2 模型构建,其专有培训数据集涵盖了 19 多个行业的简历和人才概况。这个基于 LLM 的流程通过自动执行简历的人工审核流程并将最佳候选人与空缺职位进行匹配,节省了数百个小时。
-
知识图表 — 建立在 Amazon Neptune 之上的知识图表,Amazon Neptune 是一个统一的人才信息存储库,包括组织和行业的角色和技能分类,使用技能、角色及其属性、关系和逻辑约束的定义来捕捉医疗保健人才的语义。
-
技能本体论 — 通过本体论算法发现候选人技能与理想的当前状态或未来状态技能(使用知识图进行检索)之间的技能接近性,该算法衡量候选人技能和目标状态技能之间的语义相似性。
-
学习途径和内容 — 此组件是一个学习推荐引擎,可以根据已确定的技能差距,从任何供应商提供的学习材料目录中推荐正确的学习内容。通过分析技能差距并推荐优先的学习内容,为每位候选人确定最佳的技能提升途径,从而使每位候选人在向新职位过渡期间能够实现无缝和持续的专业发展。
这种基于云的自动化解决方案由机器学习服务 LLMs、知识图和检索增强生成 (RAG) 提供支持。它可以扩展到在最短的时间内处理成千上万份简历,创建即时候选人档案,确定他们当前或潜在的未来状态中的差距,然后有效地推荐正确的学习内容来缩小这些差距。
下图显示了框架的 end-to-end流程。该解决方案建立在 Amazon Bedrock LLMs 中经过微调的基础上。它们从 Amazon Neptune 的医疗保健人才知识库中 LLMs 检索数据。数据驱动的算法为每位候选人提供最佳学习途径的建议。
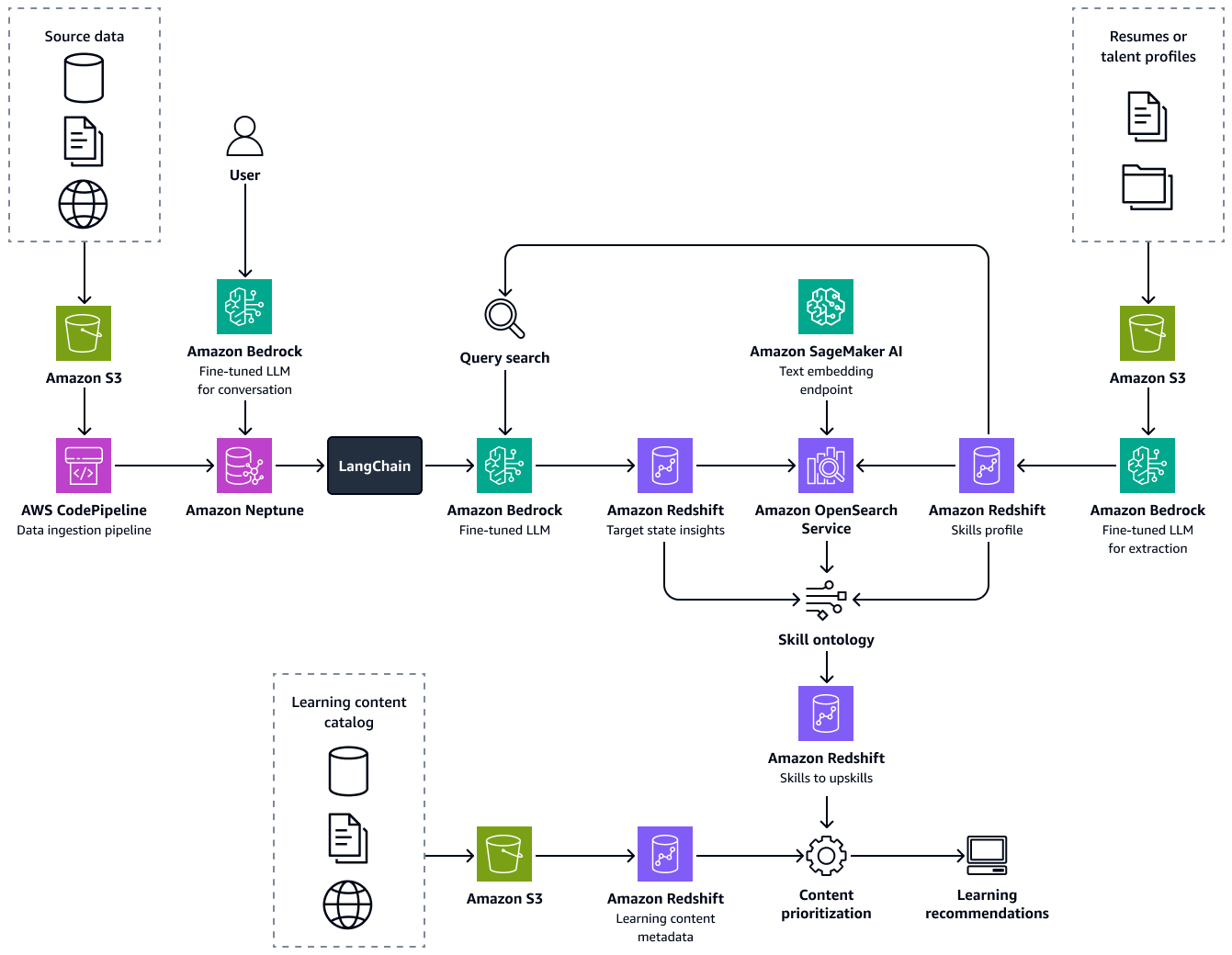
构建此解决方案包括以下步骤:
第 1 步:提取人才信息并建立技能档案
首先,您可以使用自定义数据集对 Amazon Bedrock 中的大型语言模型(例如 Llama 2)进行微调。这会根据用例调整法学硕士。在培训期间,您可以准确、一致地从候选人简历或类似人才档案中提取关键人才属性。这些天赋属性包括技能、当前职称、带日期跨度的经验头衔、教育和认证。有关更多信息,请参阅 Amazon Bedrock 文档中的自定义模型以提高其针对您的用例的性能。
下图显示了使用 Amazon Bedrock 微调简历解析模型的过程。真实和综合创建的简历都将传递给法学硕士,以提取关键信息。一组数据科学家根据原始原始文本验证提取的信息。然后,通过使用chain-of-thought
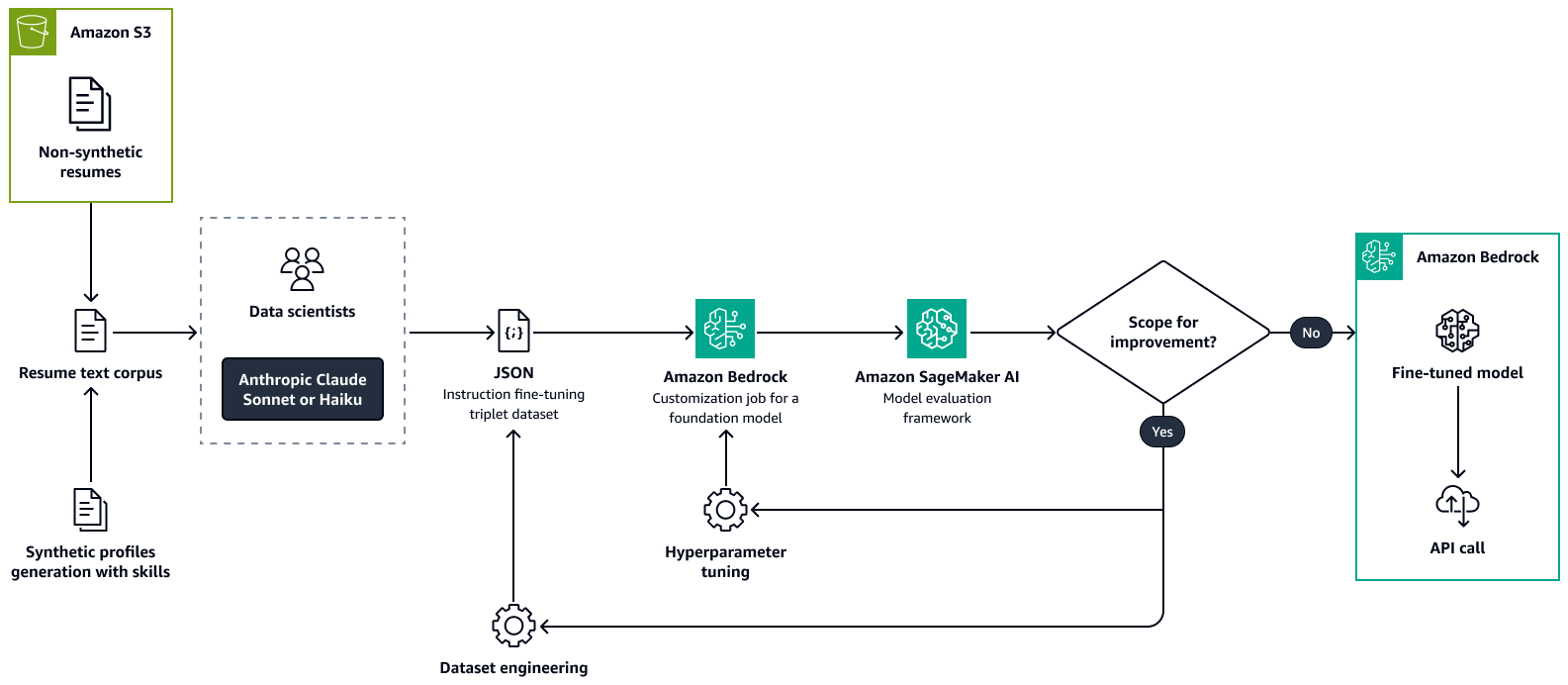
第 2 步:从知识图谱中发现 role-to-skill相关性
接下来,您将创建一个知识图表,其中概述了您的组织和医疗保健行业其他组织的技能和角色分类法。这个内容丰富的知识库来自于 Amazon Red shift 中的汇总人才和组织数据。您可以从一系列劳动力市场数据提供商以及组织特定的结构化和非结构化数据源收集人才数据,例如企业资源规划 (ERP) 系统、人力资源信息系统 (HRIS)、员工简历、职位描述和人才架构文档。
在 Amazon Neptune 上构建知识图谱。节点代表技能和角色,边缘代表它们之间的关系。使用元数据丰富此图表,包括组织名称、行业、职系、技能类型、角色类型和行业标签等详细信息。
接下来,您将开发一个图形检索增强生成 (Graph RAG) 应用程序。Graph RAG 是一种 RAG 方法,用于从图形数据库中检索数据。以下是 Graph RAG 应用程序的组件:
-
与 Amazon Bedrock 中的 LLM 集成 — 该应用程序使用 Amazon Bedrock 中的 LLM 来理解自然语言和生成查询。用户可以使用自然语言与系统进行交互。这使得非技术利益相关者可以访问它。
-
编排和信息检索 — 使用或 LlamaIndex
LangChain 协调员,以促进法学硕士和海王星知识图谱之间的整合。他们管理将自然语言查询转换为 OpenCyph er 查询的过程。然后,他们在知识图上运行查询。使用提示工程来指导 LLM 了解构建 OpenCypher 查询的最佳实践。这有助于优化查询以检索相关的子图,该子图包含与所查询的角色和技能有关的所有相关实体和关系。 -
洞察生成 — Amazon Bedrock 中的 LLM 处理检索到的图表数据。它可以生成有关当前状态的详细见解,并预测所查询角色和相关技能的未来状态。
下图显示了根据源数据构建知识图谱的步骤。您将结构化和非结构化源数据传递到数据摄取管道。该管道提取信息并将其转换为与 Amazon Neptune 兼容的 CSV 批量加载格式。批量加载器 API 将存储在 Amazon S3 存储桶中的 CSV 文件上传到 Neptune 知识图表。对于与人才未来状态、相关角色或技能相关的用户查询,Amazon Bedrock 中经过微调的 LLM 会通过以下方式与知识图谱进行交互 LangChain 管弦乐师。协调器从知识图中检索相关上下文,并将响应推送到 Amazon Redshift 中的见解表。这些区域有:LangChain 像 Gr aph QAChain
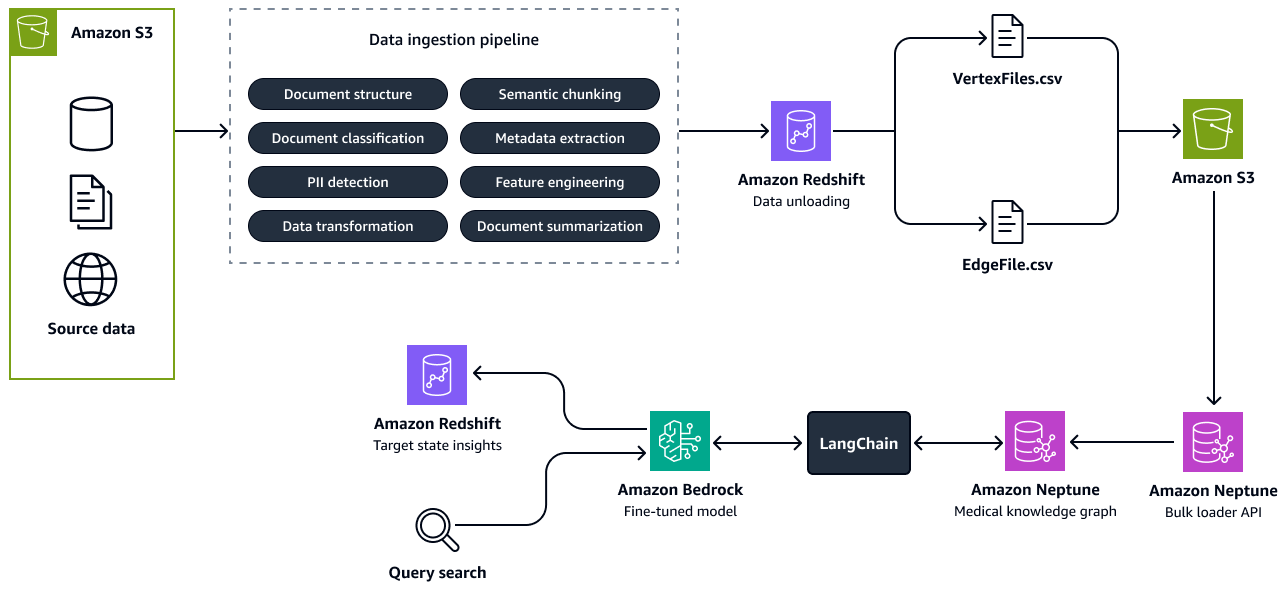
第 3 步:找出技能差距并推荐培训
在此步骤中,您可以准确计算医疗保健专业人员的当前状态与潜在的未来州角色之间的接近程度。为此,您可以通过将个人的技能组合与工作角色进行比较来进行技能亲和力分析。在 A mazon S OpenSearch ervic e 矢量数据库中,您可以存储技能分类信息和技能元数据,例如技能描述、技能类型和技能集群。使用 Amazon Bedrock 嵌入模型,例如 Amazon Titan 文本嵌入模型,将已识别的关键技能嵌入到向量中。通过向量搜索,您可以检索当前状态技能和目标状态技能的描述,并进行本体分析。该分析提供了当前状态和目标状态技能对之间的接近分数。对于每对,您可以使用计算出的本体论分数来确定技能亲和力的差距。然后,你推荐提升技能的最佳途径,候选人在角色过渡期间可以考虑这个路径。
对于每个角色,推荐正确的学习内容以提高技能或重新培养技能都需要一种系统的方法,首先要创建全面的学习内容目录。该目录存储在 Amazon Redshift 数据库中,汇总了来自不同提供商的内容,并包括元数据,例如内容时长、难度级别和学习模式。下一步是提取每篇内容提供的关键技能,然后将其映射到目标角色所需的个人技能。您可以通过技能接近度分析来分析内容提供的覆盖范围,从而实现此映射。该分析评估了内容所教授的技能与该职位所需技能的密切程度。元数据在为每项技能选择最合适的内容方面起着至关重要的作用,可确保学员获得适合其学习需求的量身定制的推荐。 LLMs 在 Amazon Bedrock 中使用可以从内容元数据中提取技能、执行功能工程和验证内容推荐。这提高了技能提升或技能再培训过程中的准确性和相关性。
与 Well-Architect AWS ed 框架保持一致
该解决方案符合 Well-Ar AWS chitected
-
卓越运营 — 模块化的自动化管道可增强卓越运营。管道的关键组件是分离和自动化的,因此可以更快地更新模型,更轻松地进行监控。此外,自动训练管道支持更快地发布经过微调的模型。
-
安全 — 该解决方案处理敏感和个人身份信息 (PII),例如简历和人才档案中的数据。在 AWS Identity and Access Management (IAM) 中,实施精细的访问控制策略,并确保只有经过授权的人员才能访问这些数据。
-
可靠性 — 该解决方案使用的诸如 Neptune AWS 服务、Amazon Bedrock 和 OpenSearch 服务等,即使在需求旺盛的情况下也能提供容错能力、高可用性和不间断地访问见解。
-
性能效率 — LLMs 在 Amazon Bedrock 和 S OpenSearch ervice 矢量数据库中进行了微调,旨在快速准确地处理大型数据集,从而提供及时、个性化的学习建议。
-
成本优化 — 该解决方案使用 RAG 方法,可减少对模型进行持续预训练的需求。系统不会反复微调整个模型,而是仅微调特定的流程,例如从简历中提取信息和构造输出。这可以显著节省成本。通过最大限度地减少资源密集型模型训练的频率和规模以及使用 pay-per-use云服务,医疗保健组织可以在保持高性能的同时优化运营成本。
-
可持续性 — 该解决方案使用可扩展的云原生服务,可动态分配计算资源。这减少了能源消耗和对环境的影响,同时仍然支持大规模的数据密集型人才转型计划。
