本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
架构
下图描述了本指南中描述的解决方案的架构。 AWS Glue 任务从亚马逊简单存储服务 (Amazon S3) 存储桶读取数据,该存储桶是一种基于云的对象存储服务,可帮助您存储、保护和检索数据。你可以启动 AWS Glue Spark SQL 通过 AWS Management Console、AWS Command Line Interface (AWS CLI) 或 AWS Glue API 完成任务。的 AWS Glue Spark SQL job 处理 Amazon S3 存储桶中的原始数据,然后将处理后的数据存储在另一个存储桶中。

举个例子,本指南描述了一个基本的 AWS GlueSpark SQL job,写在 Python 以及 Spark SQL (PySpark)。 这 AWS Glue 份工作用于演示以下方面的最佳实践 Spark SQL 调音。尽管本指南侧重于此 AWS Glue,但本指南中的最佳实践也适用于 Amazon EMR Spark SQL 工作。
下图描述了生命周期 Spark SQL 查询。这些区域有:Spark SQL Catalyst 优化器生成查询计划。查询计划是一系列步骤,例如指令,用于访问 SQL 关系数据库系统中的数据。开发性能优化的产品 Spark
SQL 查询计划,第一步是查看EXPLAIN计划,解释计划,然后调整计划。您可以使用 Spark SQL 用户界面 (UI) 或 Spark SQL 历史服务器用于可视化计划。
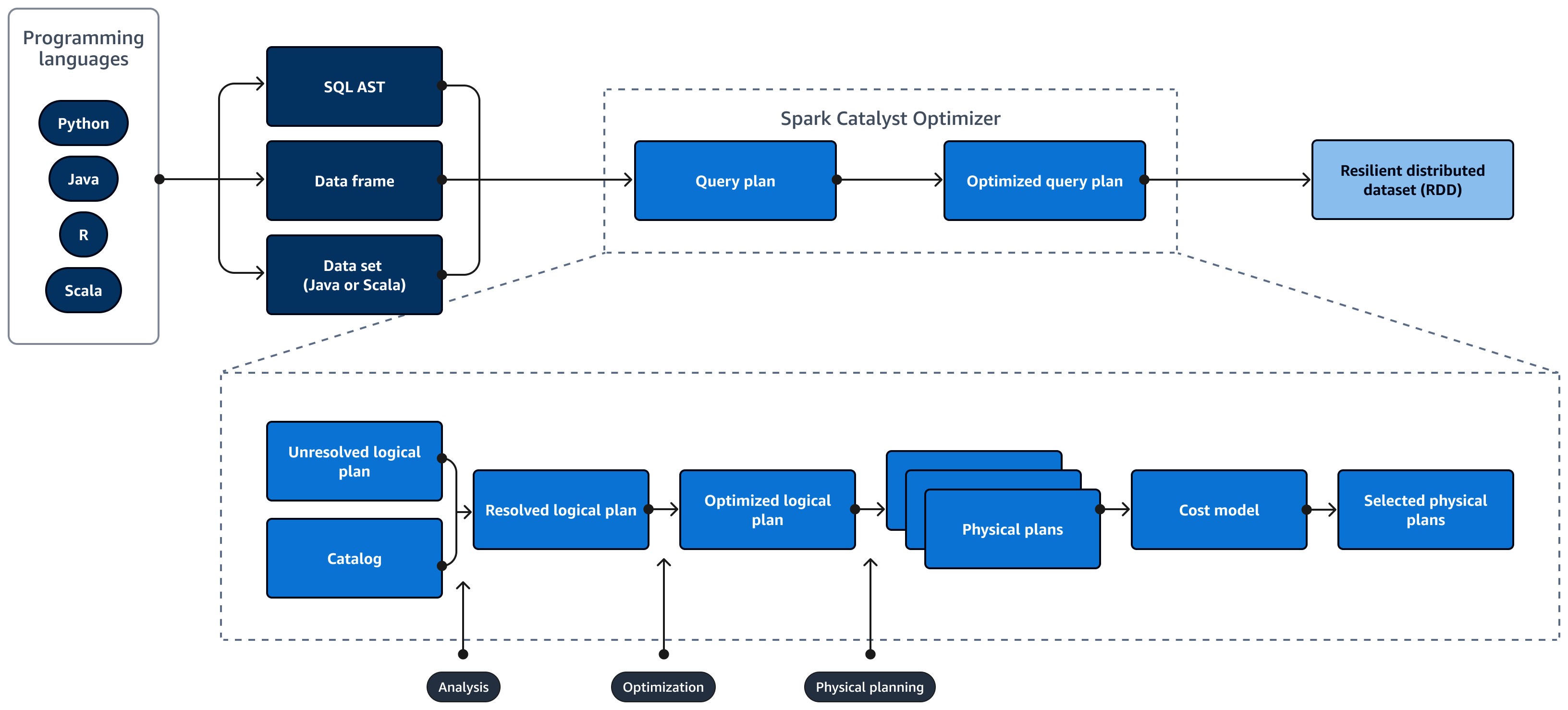
Spark Catalyst Optimizer 将初始查询计划转换为优化的查询计划,如下所示:
-
分析和陈述 APIs — 分析阶段是第一步。未解析的逻辑计划是使用未绑定的属性和数据类型生成的,其中 SQL 查询中引用的对象未知或与输入表不匹配。这些区域有:Spark SQL 然后,Catalyst Optimizer 会应用一组规则来制定逻辑计划。SQL 解析器可以生成 SQL 抽象语法树 (AST),并将其作为逻辑计划的输入提供。输入也可能是使用 API 构造的数据框或数据集对象。下表显示了何时应使用 SQL、数据框或数据集。
SQL 数据帧 数据集 语法错误 运行时 编译时间 编译时间 分析错误 运行时 运行时 编译时间 有关输入类型的更多信息,请查看以下内容:
-
数据集 API 提供类型化版本。由于严重依赖用户定义的 lambda 函数,这会降低性能。RDD 或数据集是静态类型的。例如,在定义 RDD 时,需要明确提供架构定义。
-
数据框 API 提供非类型化关系操作。数据框是动态键入的。与 RDD 类似,在定义数据框时,架构保持不变。数据仍然是结构化的。但是,此信息仅在运行时可用。这允许编译器编写类似 SQL 的语句并即时定义新列。例如,它可以在现有数据框中追加列,而无需为每个操作都定义一个新类。
-
A Spark SQL 在运行时对查询进行语法和分析错误评估,从而提供更快的运行时间。
-
-
目录 —Spark SQL uses Apache Hive Metastore (HMS) 管理持久关系实体(例如数据库、表、列和分区)的元数据。
-
优化-优化器使用启发式方法和成本重写查询计划。它会执行以下操作来生成优化的逻辑计划:
-
修剪列
-
向下推谓词
-
重新排序加入
-
-
物理计划和计划器 — Spark SQL Catalyst Optimizer 将逻辑计划转换为一组物理计划。这意味着它会将内容转换为方式。
-
精选物理计划 — Spark SQL Catalyst 优化器选择最具成本效益的物理计划。
-
优化的查询计划 — Spark SQL 运行性能优化和成本优化的查询计划。Spark SQL 内存管理跟踪内存使用情况,并在任务和操作员之间分配内存。这些区域有:Spark SQL 钨引擎可以显著提高内存和CPU效率 Spark SQL 应用程序。它还实现了二进制数据模型处理,并且直接对二进制数据进行操作。这就绕过了反序列化的需求,显著减少了与数据转换和反序列化相关的开销。
