本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
解决方案概述
可扩展的 ML 框架
在一个拥有数百万客户、分布在多个业务线的企业中,ML 工作流程需要整合由孤立的团队使用不同的工具所拥有和管理的数据,以释放商业价值。银行致力于保护客户的数据。同样,用于开发 ML 模型的基础设施也必须符合高安全标准。这种额外的安全性可以进一步增加复杂性,并影响新 ML 模型的价值实现时间。在可扩展的机器学习框架中,您可以使用现代化的标准化工具集来减少组合不同工具所需的工作量,并简化新机器学习 route-to-live模型的流程。
传统上,FS 行业数据科学活动的管理和支持由中央平台团队控制,该团队为整个组织的数据团队收集需求、预配置资源和维护基础设施。要在整个组织的联合团队中快速扩展 ML 的使用,您可以使用可扩展的 ML 框架,为新模型和管道的开发人员提供自助服务功能。使这些开发人员能够部署现代、预先批准、标准化和安全的基础设施。最终,这些自助服务功能可以减少组织对集中式平台团队的依赖,并缩短 ML 模型开发的价值实现时间。
可扩展的 ML 框架使数据使用者(如数据科学家或 ML 工程师)能够执行以下操作,从而释放商业价值:
浏览并发现模型训练所需的预先批准数据
快速轻松地访问预先批准数据
使用预先批准数据证明模型的可行性
将经过验证的模型投入生产,供其他人使用
下图突出显示了框架的 end-to-end流程以及机器学习用例的简化生存路线。
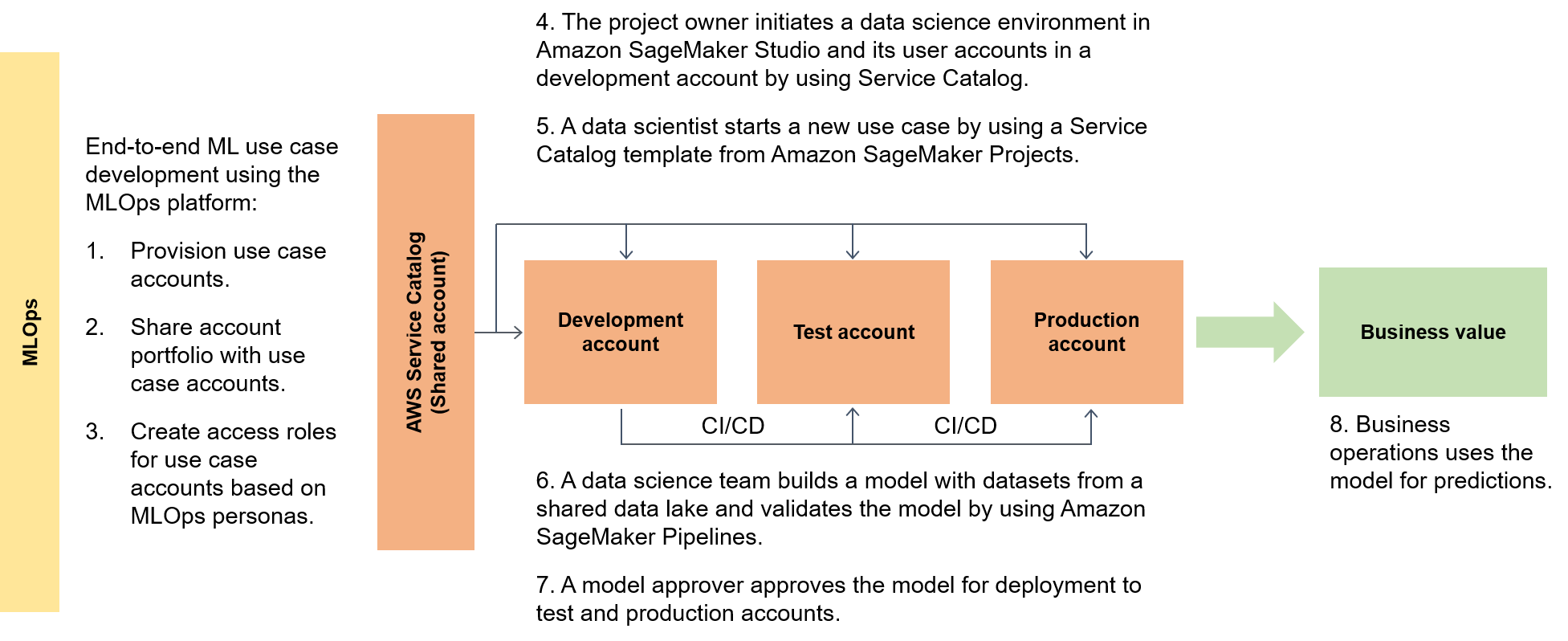
在更广泛的背景下,数据使用者使用名为 data.all 的无服务器加速器在多个数据湖中获取数据,然后使用这些数据训练模型,如下图所示。
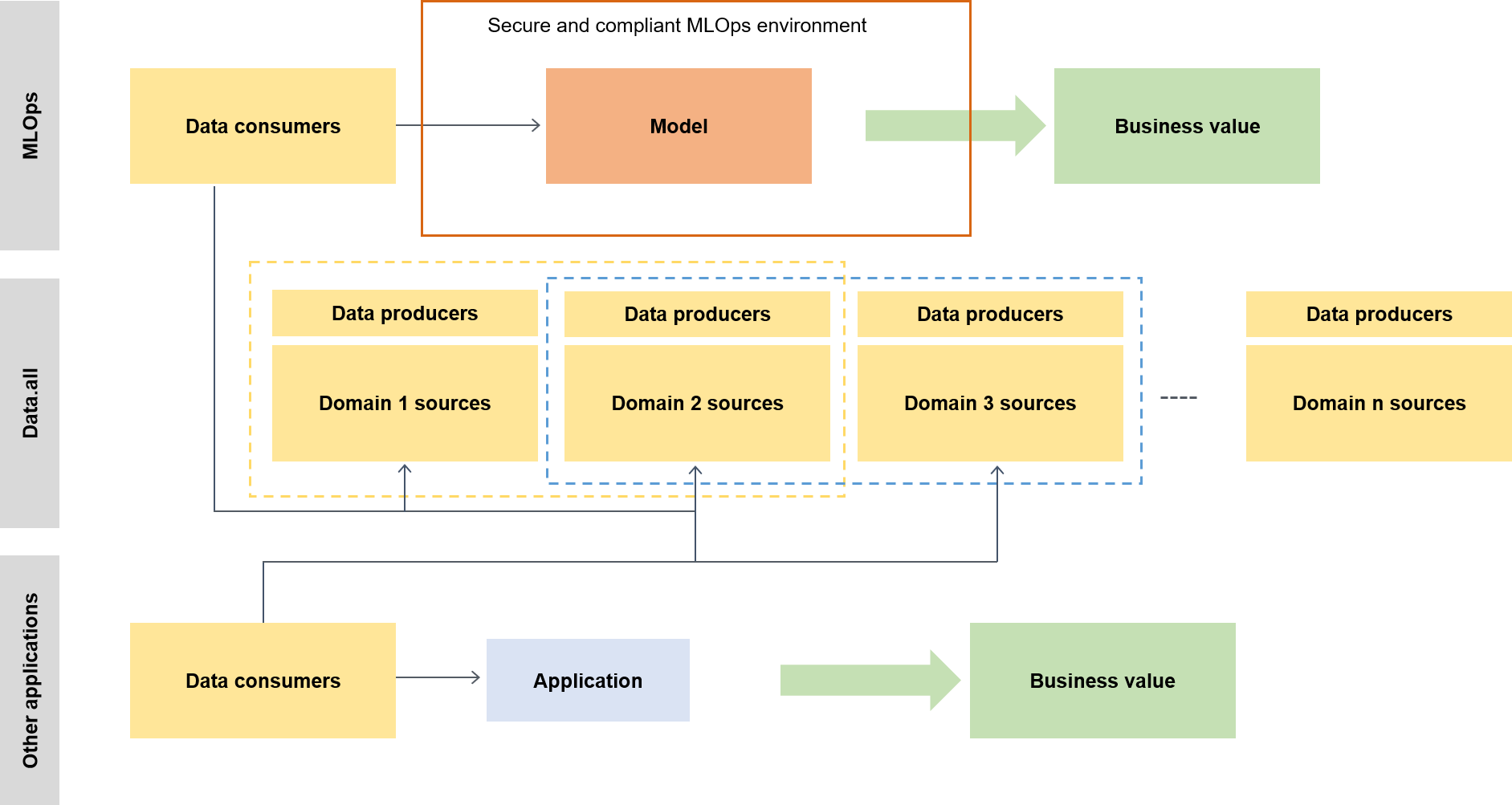
在较低级别上,可扩展的 ML 框架包含以下内容:
自助服务基础设施部署 - 减少对集中式团队的依赖。
中央 Python 程序包管理系统 - 使预先批准的 Python 程序包可用于模型开发。
用于模型开发和推广的 CI/CD 管道 - 通过将持续集成和持续(CI/CD)管道作为基础设施即代码(IaC)模板的一部分,缩短上线时间。
模型测试功能-利用新模型自动提供的单元测试、模型 end-to-end测试、集成测试和测试功能。
模型解耦和编排 — 根据计算资源要求解耦模型步骤,并使用 Amazon AI Pipelines 编排不同的步骤,从而避免不必要的计算,使您的部署更加稳健。 SageMaker
代码标准化 — 使用 CI/CD 管道集成来验证 Python 增强提案 (PEP 8)
标准,从而提高代码质量。 快速入门通用机器学习模板 — 使用 SageMaker AI Projects 进行部署,只需单击一下按钮,即可获取实例化机器学习建模环境(开发、预生产和生产)和相关管道的 Service Catalog 模板。
数据和模型质量监控 — 使用 Amazon A SageMaker I Model Monitor 自动监控数据和模型质量的偏差,确保您的模型性能符合操作要求并在您的风险承受能力范围内。
偏差监控 - 通过自动检查数据失衡以及世界变化是否给模型带来偏差,使模型所有者能够做出公平公正的决策。
元数据的中央枢纽
Data.all
SageMaker 验证
为了证明 SageMaker 人工智能在一系列数据处理和机器学习架构中的能力,实现这些功能的团队与银行领导团队一起从银行客户的不同部门中选择复杂程度不同的用例。 用例数据经过混淆处理,并可在功能验证阶段的用例开发账户的本地亚马逊简单存储服务 (Amazon S3) Simp
模型从原始训练环境迁移到 A SageMaker I 架构完成后,您的云托管数据湖将使数据可供生产模型读取。 然后,生产模型生成的预测会被写回数据湖中。
候选用例迁移完成后,可扩展的 ML 框架会为目标指标设定一个初始基线。您可以将基线与之前的本地或其他云提供商计时进行比较,以证明可扩展的 ML 框架可以实现的时间方面的改善。
