为 Amazon Redshift 执行概念验证(POC)。
Amazon Redshift 是一种流行的云数据仓库,它提供完全托管的基于云的服务,可与组织的 Amazon Simple Storage Service 数据湖、实时流、机器学习(ML)工作流、事务性工作流等集成。以下各节将指导您完成对 Amazon Redshift 执行概念验证(POC)的过程。此处的信息可帮助您为 POC 设定目标,并利用可自动为 POC 预置和配置服务的工具。
注意
如需 PDF 格式的信息副本,请选择 Amazon Redshift 资源
执行 Amazon Redshift 的 POC 时,您需要测试、证明和采用各种功能,包括出色的安全功能、弹性扩展、易于集成和摄取以及灵活的去中心化数据架构选项。

请遵循以下步骤,以成功执行 POC。
步骤 1:确定 POC 的范围

执行 POC 时,您可以选择使用自己的数据,也可以选择使用基准测试数据集。选择自己的数据时,您可以对数据运行自己的查询。使用基准测试数据时,基准测试中提供了示例查询。如果您尚未准备好使用自己的数据执行 POC,请参阅使用示例数据集了解更多详细信息。
一般来说,我们建议 Amazon Redshift POC 使用两周的数据。
首先执行以下步骤:
确定您的业务和功能需求,然后进行倒推。常见的示例有:更快的性能、更低的成本、测试新的工作负载或功能,或者将 Amazon Redshift 与其他数据仓库进行比较。
设定具体目标,这些目标将成为 POC 的成功标准。例如,从更快的性能出发,列出您希望加速的前五个流程,并将当前的运行时间和所需的运行时间一并列出。这些可以是报告、查询、ETL 流程、数据摄取,或者您当前的任何棘手问题。
确定运行测试所需的具体范围和构件。您需要哪些数据集才能迁移或持续摄取到 Amazon Redshift 中,以及需要哪些查询和流程来运行测试以根据成功标准进行衡量? 有两种方式可执行此操作:
自带数据
要测试自己的数据,请列出测试成功标准所需的最低可行数据构件清单。例如,如果您当前的数据仓库有 200 个表,但您要测试的报告只需要 20 个表,则仅使用较小的表子集可以更快地运行 POC。
使用示例数据集
如果您没有准备好自己的数据集,仍可使用行业标准的基准数据集(如 TPC-DS
或 TPC-H )开始对 Amazon Redshift 执行 POC,并运行示例基准测试查询以利用 Amazon Redshift 的强大功能。创建 Amazon Redshift 数据仓库后,可以从其内部访问这些数据集。有关如何访问这些数据集和示例查询的详细说明,请参阅步骤 2:启动 Amazon Redshift。
步骤 2:启动 Amazon Redshift

Amazon Redshift 可通过快速、简单且安全的大规模云数据仓库服务,使您更快地获得见解。您可以通过在 Redshift Serverless 控制台
设置 Amazon Redshift Serverless
首次使用 Redshift Serverless 时,控制台会引导您完成启动仓库所需的步骤。您也可能有资格获得账户中的 Redshift Serverless 使用积分。有关选择免费试用的更多信息,请参阅 Amazon Redshift 免费试用
如果您之前在自己的账户中启动过 Redshift Serverless,请按照《Amazon Redshift 管理指南》中的创建带有命名空间的工作组中的步骤进行操作。仓库可用后,您可以选择加载 Amazon Redshift 中提供的示例数据。有关使用 Amazon Redshift 查询编辑器 v2 以加载数据的信息,请参阅《Amazon Redshift 管理指南》中的加载示例数据。
如果您自带数据而不是加载示例数据集,请参阅步骤 3:加载数据。
步骤 3:加载数据

启动 Redshift Serverless 后,下一步是为 POC 加载数据。无论您是上传简单的 CSV 文件、从 S3 中摄取半结构化数据,还是直接流式传输数据,Amazon Redshift 都能灵活地将数据从源位置快速轻松地移动到 Amazon Redshift 表中。
选择以下方法之一以加载数据。
上传本地文件
为了快速摄取和分析,您可以使用 Amazon Redshift 查询编辑器 v2 轻松从本地桌面加载数据文件。它能够处理各种格式的文件,如 CSV、JSON、AVRO、PARQUET、ORC 等。要让您的用户以管理员身份使用查询编辑器 v2 从本地桌面加载数据,您必须指定一个通用 Amazon S3 存储桶,并且必须为该用户账户配置适当的权限。您可以遵循使用查询编辑器 V2 在 Amazon Redshift 中轻松安全地加载数据
加载 Amazon S3 文件
要将数据从 Amazon S3 存储桶加载到 Amazon Redshift 中,请首先使用 COPY 命令,指定源 Amazon S3 位置和目标 Amazon Redshift 表。确保正确配置 IAM 角色和权限,以允许 Amazon Redshift 访问指定的 Amazon S3 存储桶。请遵循教程:从 Amazon S3 加载数据,以获取分步指导。您也可以选择查询编辑器 v2 中的加载数据选项,直接从 S3 存储桶加载数据。
持续数据摄取
自动复制(预览版)是 COPY 命令的扩展,可自动从 Amazon S3 存储桶持续加载数据。当您创建 COPY 作业时,Amazon Redshift 会检测何时在指定路径中创建新的 Amazon S3 文件,然后自动加载这些文件,无需您的干预。Amazon Redshift 会跟踪加载的文件,以确认它们只加载一次。有关创建 COPY 作业的说明,请参阅COPY JOB
注意
自动复制目前处于预览状态,仅在特定 AWS 区域的预置集群中受支持。要创建用于自动复制的预览集群,请参阅从 Amazon S3 持续摄取文件(预览版)。
加载流数据
串流摄取直接以低延迟、高速度的方式将流数据从 Amazon Kinesis Data Streams
步骤 4:分析数据

创建 Redshift Serverless 工作组和命名空间并加载数据后,您可以通过从 Redshift Serverless 控制台
使用 Amazon Redshift 查询编辑器 v2 进行查询
您可以从 Amazon Redshift 控制台访问查询编辑器 v2。有关如何使用查询编辑器 v2 配置、连接和运行查询的完整指南,请参阅使用 Amazon Redshift 查询编辑器 v2 简化数据分析
或者,如果您想在 POC 中运行负载测试,则可以通过以下步骤来安装和运行 Apache JMeter。
使用 Apache JMeter 运行负载测试
要执行负载测试以模拟“N”个用户同时向 Amazon Redshift 提交查询,可以使用基于 Java 的开源工具 Apache JMeter
要安装和配置 Apache JMeter 以在 Redshift Serverless 工作组中运行,请按照使用 AWS 分析自动化工具包自动进行 Amazon Redshift 负载测试
完成自定义 SQL 语句并最终确定测试计划后,请进行保存并在 Redshift Serverless 工作组中运行测试计划。要监控测试进度,请打开 Redshift Serverless 控制台
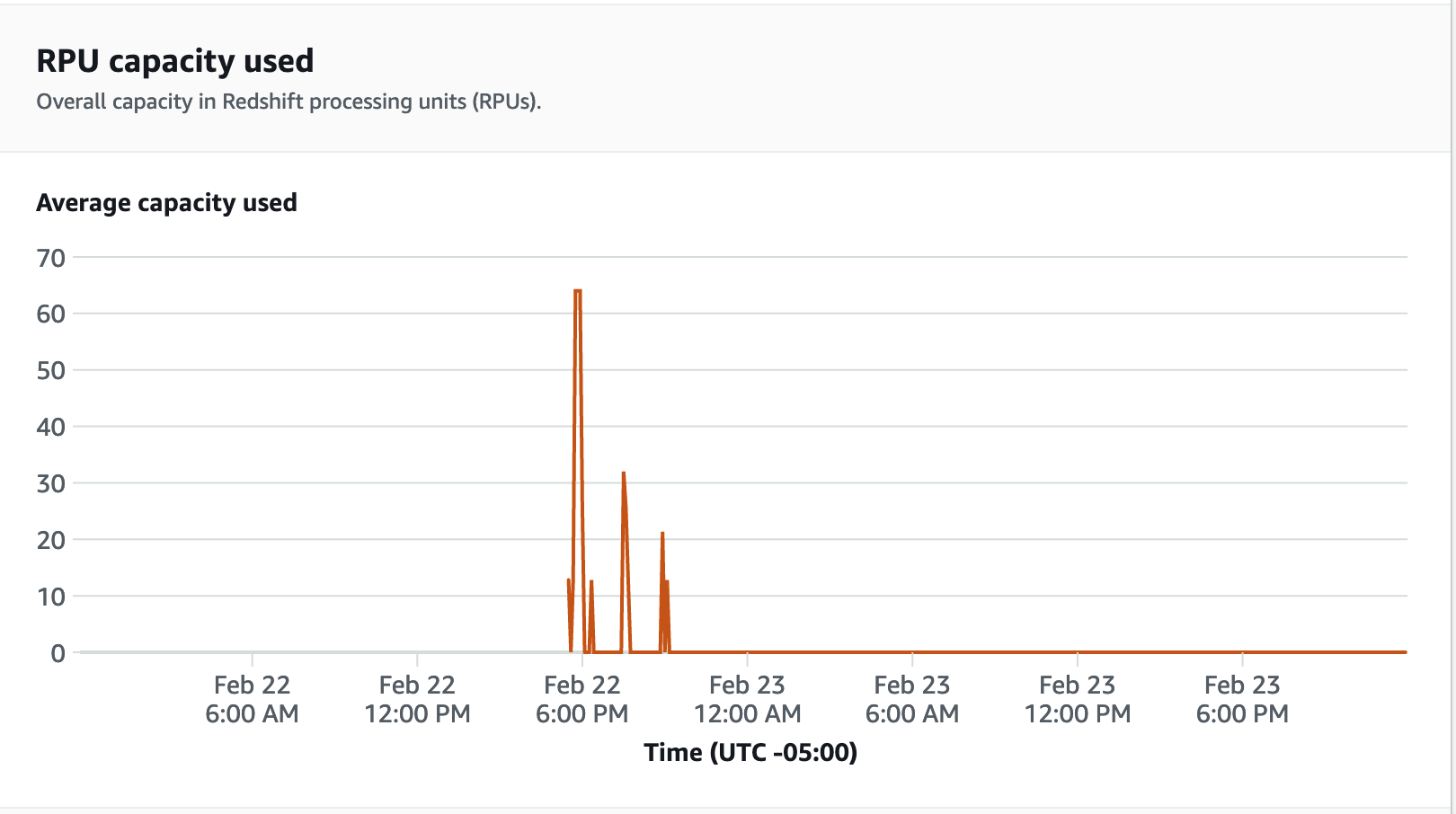
要查看性能指标,请在 Redshift Serverless 控制台上选择数据库性能选项卡,以监控数据库连接和 CPU 利用率等指标。在这里,您可以查看图表以监控使用的 RPU 容量,并观察在工作组上运行负载测试时 Redshift Serverless 如何自动扩展以满足并发工作负载需求。
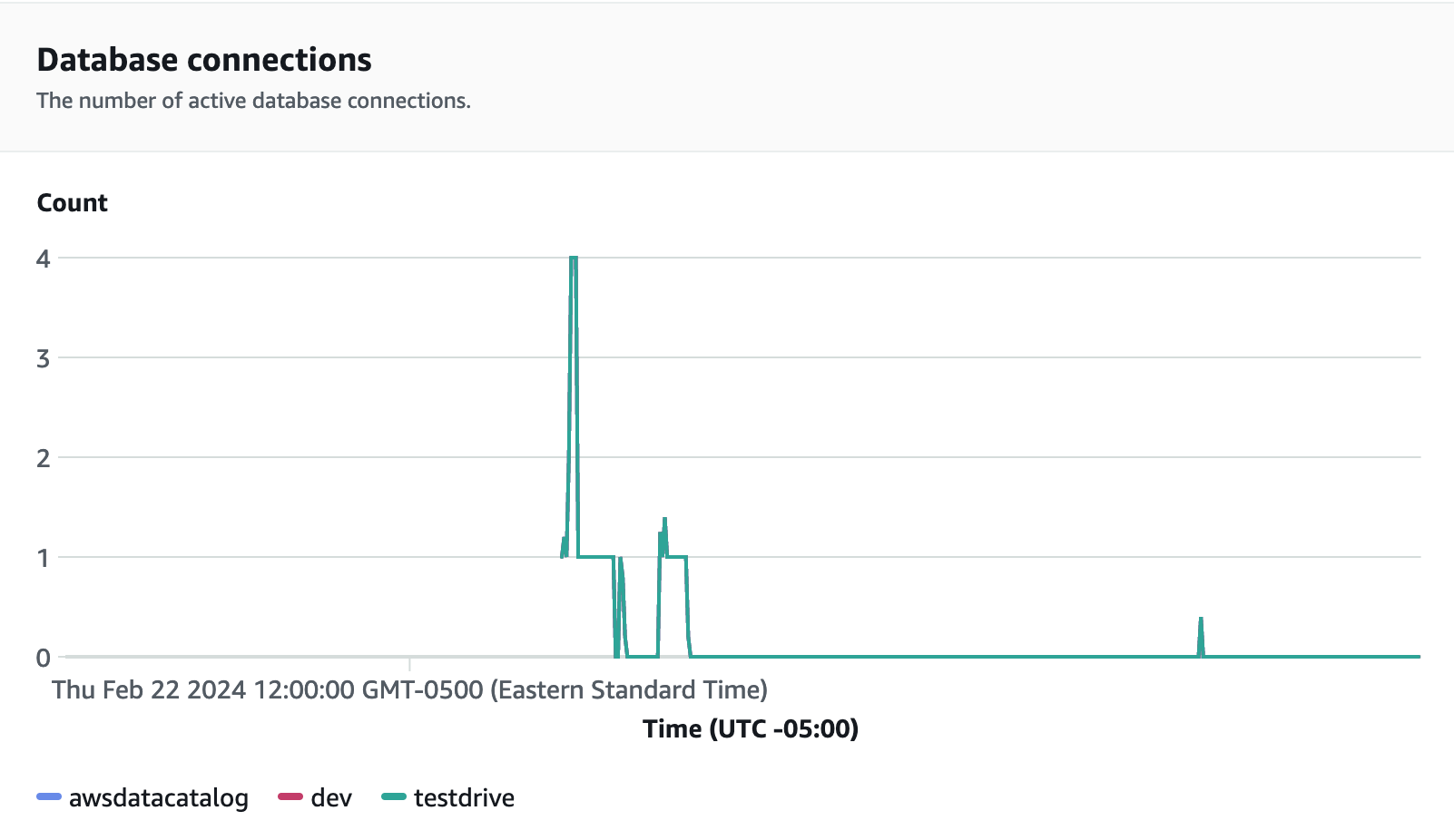
数据库连接是在运行负载测试时要监控的另一个有用指标,您可以通过该指标来了解工作组在给定时间如何处理大量并发连接以满足不断增长的工作负载需求。
步骤 5:优化

Amazon Redshift 通过提供各种配置和功能来支持各个使用案例,使成千上万的用户能够每天处理 EB 级数据,并为其分析工作负载提供支持。在这些选项之间进行选择时,客户希望寻找可帮助他们确定最优数据仓库配置以支持其 Amazon Redshift 工作负载的工具。
试用方案
您可以使用试用方案
