本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
SAP HANA 系统复制
SAP HANA 系统复制是 SAP 为 SAP HANA 提供的高可用性解决方案。SAP HANA 系统复制用于解决因计划内维护、故障和灾难而减少的 SAP HANA 停机问题。在系统复制中,辅助 SAP HANA 系统是活动主系统的精确副本,每个系统中的活动主机数量相同。主系统中的每项服务都与辅助系统中的对应服务进行通信,并在实时复制模式下运行,以复制和保留数据和日志,通常还会将数据加载到内存中。完全支持 SAP HANA 系统复制 AWS。
架构模式
AWS 在地理位置、区域和可用区中隔离设施。多可用区域架构在保持性能的同时降低了位置故障的风险。
使用单区域多可用区域模式,辅助系统可以安装在与主系统相同 AWS 区域的不同可用区中。这为计划内停机、管理存储损坏或任何其他本地故障提供了快速故障转移解决方案。
对于灾难恢复,您可以使用多区域架构模式,将辅助系统安装在不同的 AWS 区域。您可以根据业务要求选择区域,例如为合规性而设定的数据驻留限制。
有关更多信息,请参阅上的 SAP HANA 架构模式 AWS。
复制和操作模式
SAP HANA 系统复制提供以下完全支持的复制和操作模式 AWS。
复制模式
根据您的恢复时间和恢复点目标,可以使用不同的复制模式选项来复制重做日志,包括磁盘同步、内存中同步和异步。建议在多可用区域部署中使用同步 SAP HANA 系统复制,以确保恢复点目标接近零。 AWS 在一个区域内的不同可用区之间提供低延迟和高带宽连接。
对于跨 AWS 区域的系统复制,建议使用异步复制。如果您的业务需求不受潜在网络延迟的影响,则可以选择多区域架构模式。您还必须考虑不同地区的 AWS 服务成本和跨区域数据传输。
操作模式
注册辅助 SAP HANA 系统时可以使用不同的操作模式,例如delta_datashipping、logreplay或logreplay_readaccess。因此,数据库将不同类型的数据包发送到辅助系统。
配置方案
SAP HANA 系统复制支持以下完全支持的配置方案 AWS。
主动/被动辅助系统
在这种情况下,在通过接管将活动系统从当前的主系统切换到辅助系统之前,系统复制不允许对辅助系统进行读取访问或 SQL 查询。辅助系统在logreplay操作模式下充当热备用系统。
主动/主动(启用读取)辅助系统
在这种情况下,系统复制支持对辅助系统的读取权限。它需要logreplay_readaccess操作模式。
SAP HANA 二次时空旅行
在这种情况下,您可以访问在主系统中删除的数据,或者故意延迟辅助系统logreplay中的读取旧数据,同时继续在辅助系统上进行复制。您可以从逻辑错误中恢复并更快地恢复。只能在logreplay操作模式下使用辅助时空旅行配置。
您必须正确调整辅助时空旅行记忆实例的大小以进行复制。最低内存要求是使用行存储大小、列存储内存大小和预加载的 50 GB 内存,用于logreplay操作模式。有关更多信息,请参阅 {https---launchpad-support-sap-com---notes-1999880} [1999880-常见问题解答:SAP HANA System Replication] 以下参数是设置所必需的。
-
`global.ini/ [system_replication] /timetravel_max_retention_time `参数必须在辅助系统上配置。此参数定义了辅助系统可以恢复到过去的时间段。
-
`global.ini/ [system_replication] /timetravel_snapshot_creation_interval `是一个可选参数。您可以调整辅助系统的快照创建。辅助系统可以开始保留日志和快照。
下图显示了 SAP HANA 次要时空旅行配置场景。
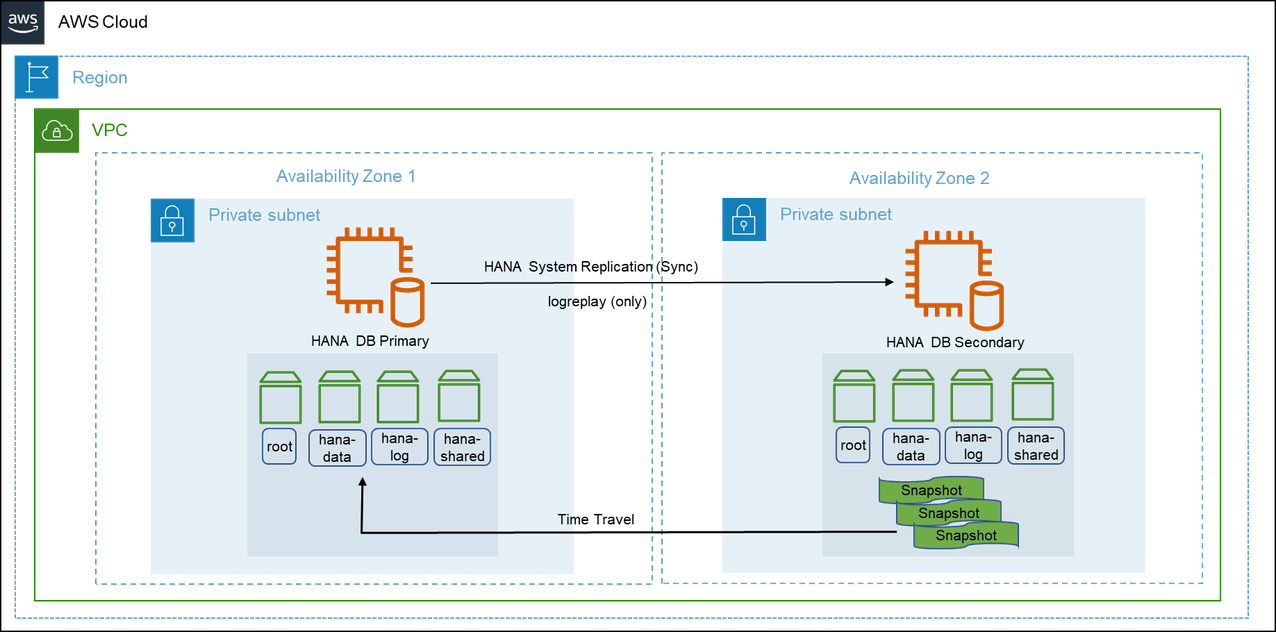
中的 SAP HANA 复制场景 AWS
在两层 SAP HANA 系统复制中,会根据性能或成本优化部署。 AWS 为了缩短接管时间,请使用与主实例大小相同的辅助实例。这是一项性能优化的部署。成本优化的部署可以在不影响恢复时间目标的情况下降低总体成本。成本优化的场景也称为指示灯灾难恢复。有关更多信息,请参阅在灾难中快速恢复关键任务系统
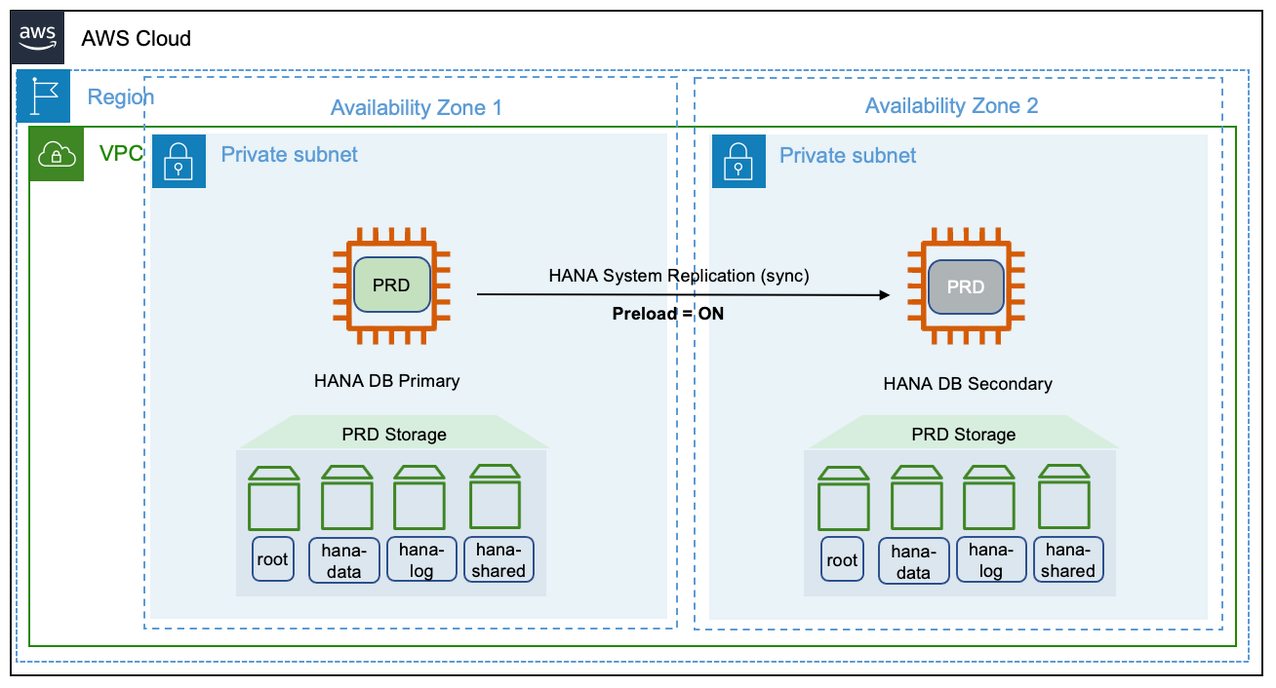
性能优化
对业务连续性至关重要的 SAP HANA 数据库系统在计划内和计划外停机期间需要接近零的恢复时间目标。您可以使用与主实例大小相同的辅助实例来优化性能。此配置可以容纳内存中预加载的列表和同步系统复制。我们不建议在此设置中跨 AWS 区域托管 SAP HANA 实例。这是为了避免在同步模式下复制时出现延迟。这种部署可以保护您的关键 SAP HANA 系统免受可用区故障的影响,这种情况很少发生。
您可以设置第三方集群解决方案以及 SAP HANA 系统复制,以检测故障并自动进行故障转移。有关更多信息,请参阅 {https---docs-aws-amazon-com--sap-latest-sap-hana hana-ops-ha-dr-html-pacemaker-hana-hadr} [Pacemaker 集群]。下图显示了性能优化的部署。
成本优化
您可以使用较小的或共享的辅助 SAP HANA 系统来降低成本。在较小的次要选项中,基础架构最初的大小要小于主基础架构,并在执行接管之前调整大小。在共享辅助选项中,辅助系统上未使用的内存由非生产或牺牲型实例使用。
对于较小的辅助选项和共享的辅助选项,该preload_column_tables参数均设置为 false。可以在位于global.ini的文件中找到此参数(/hana/shared/<SID>/global/hdb/custom/config。将该参数设置为 false 可使辅助系统在减少内存的情况下运行。但是,的默认值preload_column_tables为 t rue。
注意
在成本优化的部署中执行接管之前,必须将preload_column_tables参数设置为其默认值 true,然后重新启动 SAP HANA 系统。
SAP HANA 数据库的大小会影响将列表加载到主内存所花费的时间。这会影响您的总体恢复时间目标。您可以使用 SQL 脚本来粗略估计这些表所需的最小内存。有关更多信息,请参阅 {https---launchpad-support-sap-com---notes-1969700} [S AP ColumnStore Note 1969700 — SAP HANA 的 SQL 语句收集] 中的 HANA_Tables_ _Columns_ LastTouchTime 部分。
较小的中学
下图显示了在同一 AWS 区域内的不同可用区中部署较小的辅助 SAP HANA 系统的情况。
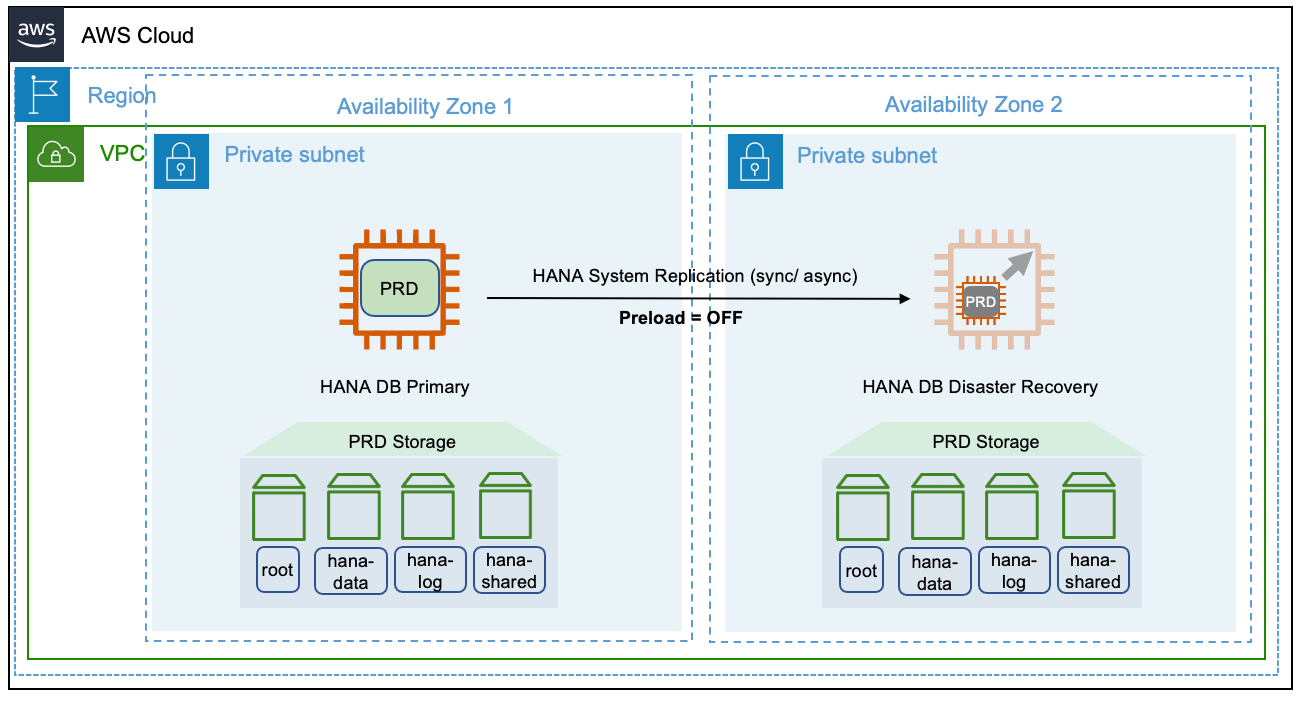
也可以跨多个 AWS 区域进行这种部署。我们建议在跨区域复制时使用异步模式。请注意,在接管之前调整辅助系统大小时,没有预留容量。生产规模的实例的要求取决于可用区域的当前可用性。
共享辅助节目
多组件一个系统 (MCOS) 模型是共享辅助部署选项的常见用例。您可以在同一台主机上操作活动质量实例和辅助实例。此设置需要额外的存储空间来操作其他实例。在接管期间,可以关闭优先级较低的实例,使底层主机资源可用于生产工作负载。
您必须global_allocation_limit为站点上运行的所有实例设置。这样可以确保任何一个global_allocation_limit设置为的实例都不会0占用主机上的全部可用内存。有关更多信息,请参阅 {https---launchpad-support-sap-com---notes-1681092} [SAP 注意:1681092 — 同一台底层服务器上有多个 SAP HANA 系统 (SIDs)]。
下图显示了上的共享辅助部署 AWS。

成本优化部署的规模注意事项
尽管禁用了列表的预加载,但辅助主机上的实际内存使用量也取决于系统复制的操作模式。欲了解更多信息,请参阅 {https---launchpad-support-sap-com---notes-1999880} [SAP 注意:SAP 注意:1999880 — 常见问题:SAP HANA 系统复制]。
尽管该preload_column_tables参数设置为 false,但logreplay操作模式也是影响内存大小的因素。您应该考虑列存储表的大小,其中包含自当前评估之日起的过去 30 天内修改过的数据。
logreplay操作模式可能无法提供真正的成本优化。delta_datashipping操作模式可以是另一种选择。但是,delta_datashipping有局限性。这可能包括更长的恢复时间和对复制站点之间网络带宽的需求增加。如果您的业务需求能够承受更高的网络带宽和宽松的恢复时间,那么delta_datashipping模式可能是一个可行的选择。
数据库实例越大,潜在的成本节省就越高。即使对于较小的数据库实例,辅助系统上的内存占用也要求最低的行存储内存和缓冲区。计算内存需求并相应地设置global_allocation_limit是一个迭代过程。随着生产数据库规模的扩大,列存储对 delta 合并的需求也在增长。因此,应定期监控站点上所有主机的内存分配,并在海量数据加载、上线和 SAP 系统特定的生命周期事件之后。
SAP HANA 多层复制
如果您同时寻求高可用性和灾难恢复,则此配置场景非常适合。此设置提供了一种链式复制模型,在这种模型中,主系统在任何给定时间点只能复制到一个辅助系统。欲了解更多信息,请参阅 {https---help-sap-com-docs-sap-hana-platform-6b944445c94ae495c83a19646e7c3fd56-f730f308fede40bcb5ccea6751e74 2-0-02} [设置 SAP HANA d-html-version 多层系统复制]。
在这种情况下,可以混合使用性能和成本部署选项。可以使用 pacemaker 群集在高可用性设置中部署主系统和辅助系统。第三级或灾难恢复系统可以是成本优化的部署。活动的非生产实例可以在同一个节点上运行,就像一个安装模型的多个组件一样。此设置如下图所示。
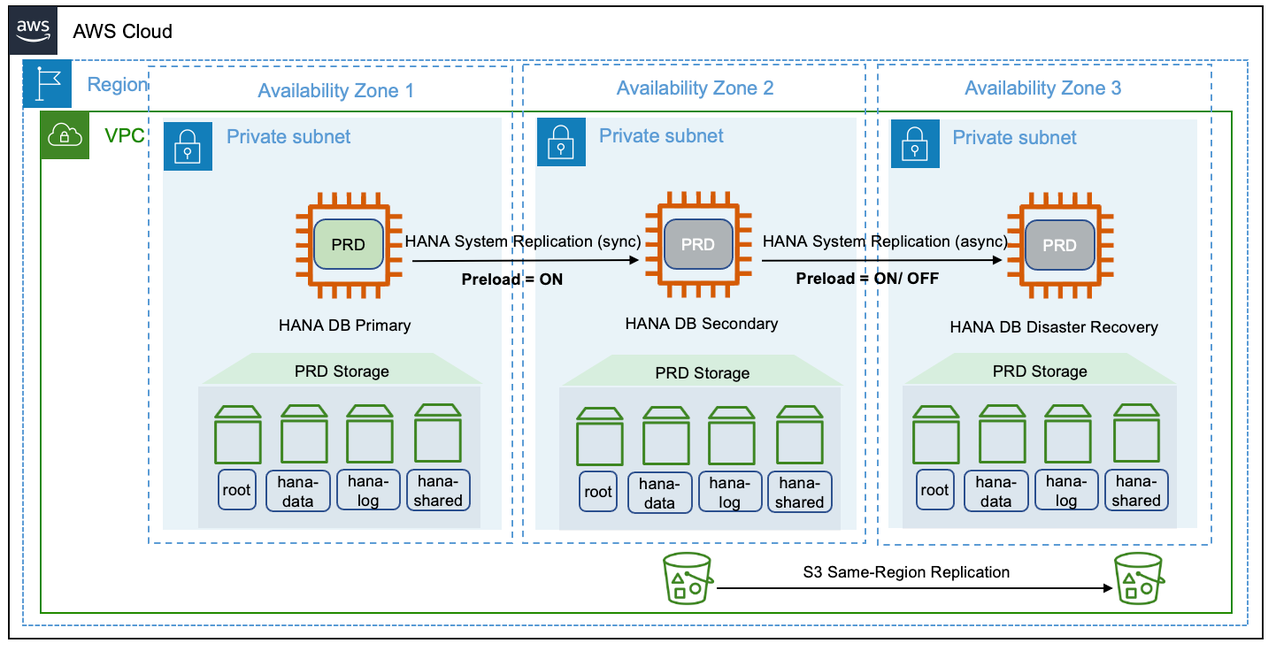
SAP HANA 多目标复制
在 SAP HANA 多层场景中,复制按顺序进行,从主系统到辅助系统,然后从辅助系统复制到第三系统。从 SPA HANA 2.0 SPS 03 开始,SAP HANA 为单个主系统提供了多目标系统复制配置,以复制到多个辅助系统。欲了解更多信息,请参阅 {https---help-sap-com-docs-sap-hana-platform-6b944445c94ae495c83a19646e7c3fd56-ba45751091889a459e606bbcf3d3-html-version-2-0-04} [SAP HANA 多目标系统复制]。
下图显示了上的多层目标复制配置。 AWS
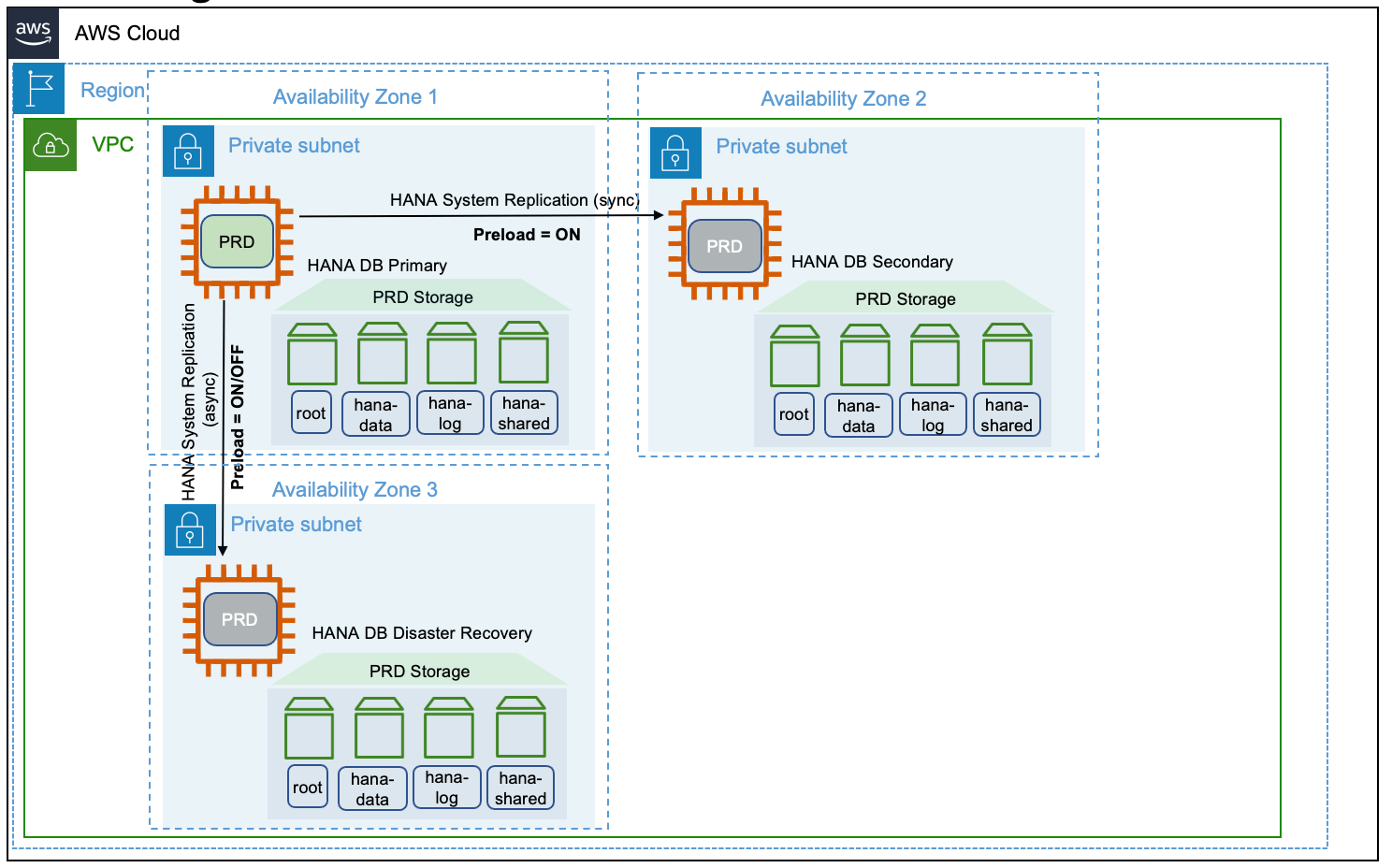
复制模式
主系统、辅助系统和第三系统可以放置在相同区域内或跨 AWS 区域的不同可用区上。除了 SAP 支持的复制模式外,由于延迟要求,跨不同 AWS 区域部署的 SAP HANA 系统必须选择异步复制模式。要查看 SAP 支持的复制模式,请参阅 {https---help-sap-com-docs-sap-hana-platform-6b944445c94ae495c83a19646e7c3fed56-c3fe0a3c263c49dc404143306455e16-html-version-2-0-02} [站点间支持的复制模式]。
操作模式
在多层或多目标系统复制中,不可能合并logreplay和delta_datashipping操作模式。例如,如果主系统和辅助系统logreplay用于系统复制,则delta_datashipping不能在二级和三级系统之间使用,反之亦然。
只有在多目标系统复制方案中才支持该logreplay操作模式。要实现高可用性 pacemaker 集群解决方案以及多目标复制,请查看 SUSE 和 RHEL 的相关资源。
使用多目标系统复制的主动/主动(启用读取)配置支持logreplay_readaccess操作模式。但是,在多层复制中,只有辅助系统可以用于只读功能,并且不能扩展到第三级系统。
灾难恢复
多目标系统复制功能允许在主系统出现故障时自动将辅助系统重新注册到新的主源。您可以使用register_secondaries_on_takeover参数设置此自动化。欲了解更多信息,请参阅 {https---help-sap-com-docs-sap-hana-platform-4e9b18c116aa42fc84c84c7dbfd02111aba-8428f79ca32d4869848a1aefe437151 2-0-04c-html-version} [多目标系统复制的灾难恢复场景]。
收购注意事项
当需要接管 SAP HANA 系统复制时,您必须按照标准的 SAP HANA 接管流程在辅助系统中触发该接管。如果您启用了自动恢复,则必须决定是否要在主可用区等待系统恢复后再进行接管。欲了解更多信息,请参阅 SAP OSS Note 2063657
客户端重定向选项
在几乎所有情况下,仅靠SAP HANA系统的故障转移并不能保证业务连续性。您必须确保您的客户端应用程序(例如 NetWeaver 应用程序服务器、JDBC、ODBC 等)能够在故障转移后连接到 SAP HANA 系统。可以通过重定向基于网络的 IP 或 DNS 来重新建立连接。与通过全球网络同步 DNS 条目的更改相比,在脚本中处理 IP 重定向的速度更快。有关更多信息,请参阅 {https---help-sap-com-viewer-product-sap-hana-Platform-2-0-05-en-US-} [SAP HANA 管理指南] 中的 “客户端连接恢复” 部分。task-operate-task
DNS 重定向
您必须在基于网络的 DNS 重定向的主机名中设置辅助系统的 IP 地址。DNS 记录必须指向同一可用区中的活动 SAP HANA 实例。在接管过程中,您可以使用脚本来修改 DNS 记录。您也可以手动更改 DNS 记录。
修改 DNS 记录需要供应商专有解决方案。借助 AWS,您可以使用 Amazon Route 53 通过 AWS CLI 或 AWS API 自动修改 DNS 记录。有关更多信息,请参阅将 Amazon Route 53 配置为 DNS 服务。
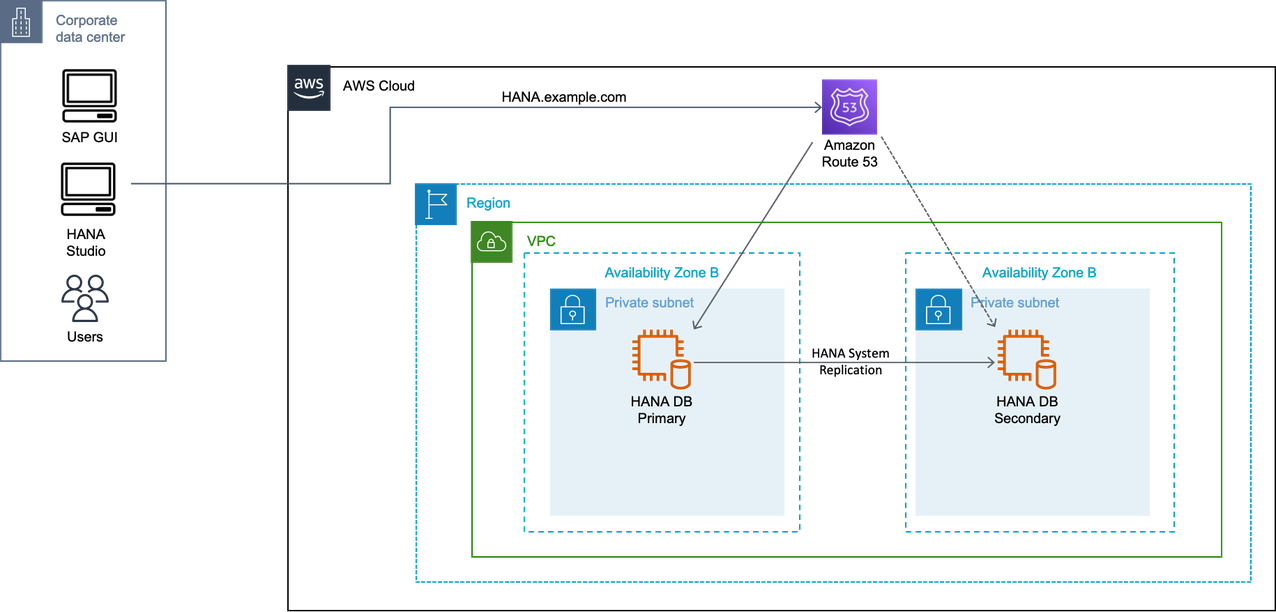
IP 重定向
使用基于网络的 IP 重定向,会为虚拟主机名分配虚拟 IP 地址。在接管的情况下,虚拟 IP 将解除与主系统的网络适配器的绑定,并绑定到辅助系统上的网络适配器。
Amazon VPC 设置包括为 SAP HANA 数据库的主节点和辅助节点分配子网。这些配置的子网中的每一个都有一个来自 Amazon VPC 的无类域间路由 (CIDR) IP 分配,该分配完全位于一个可用区内。在故障转移期间,此 CIDR IP 分配不能跨越多个区域,也不能重新分配给不同可用区域中的辅助实例。有关更多信息,请参阅 Amazon VPC 的工作原理。
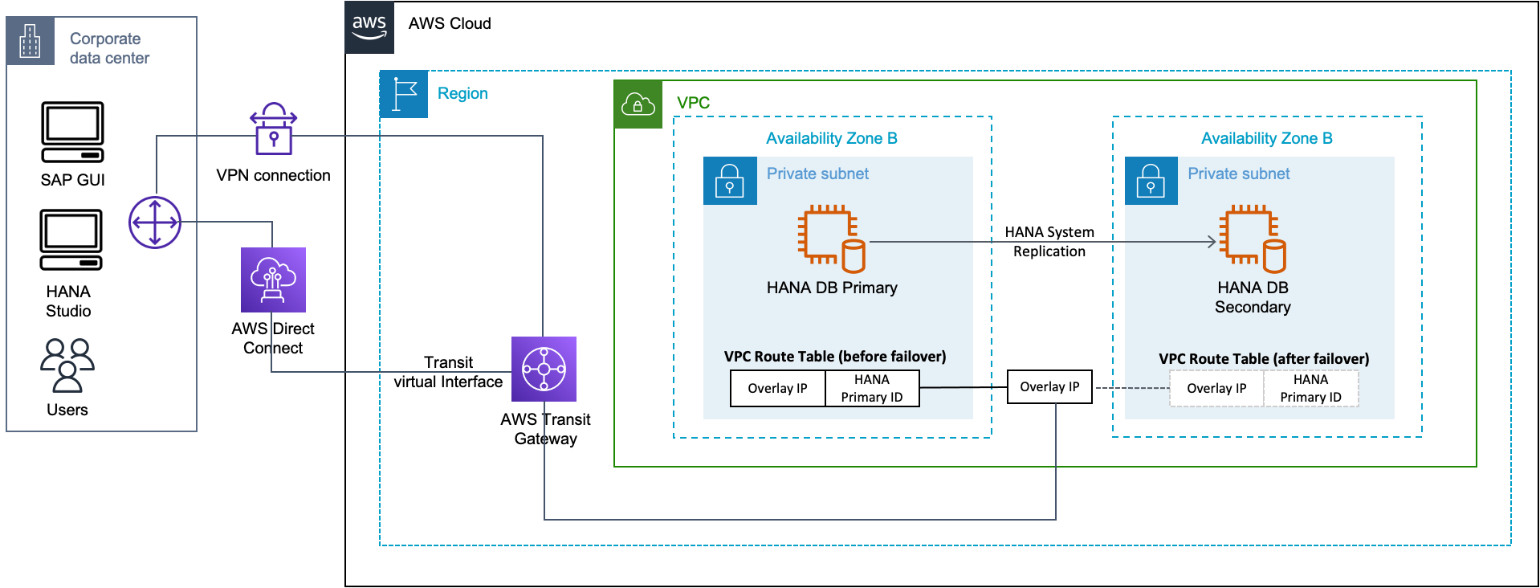
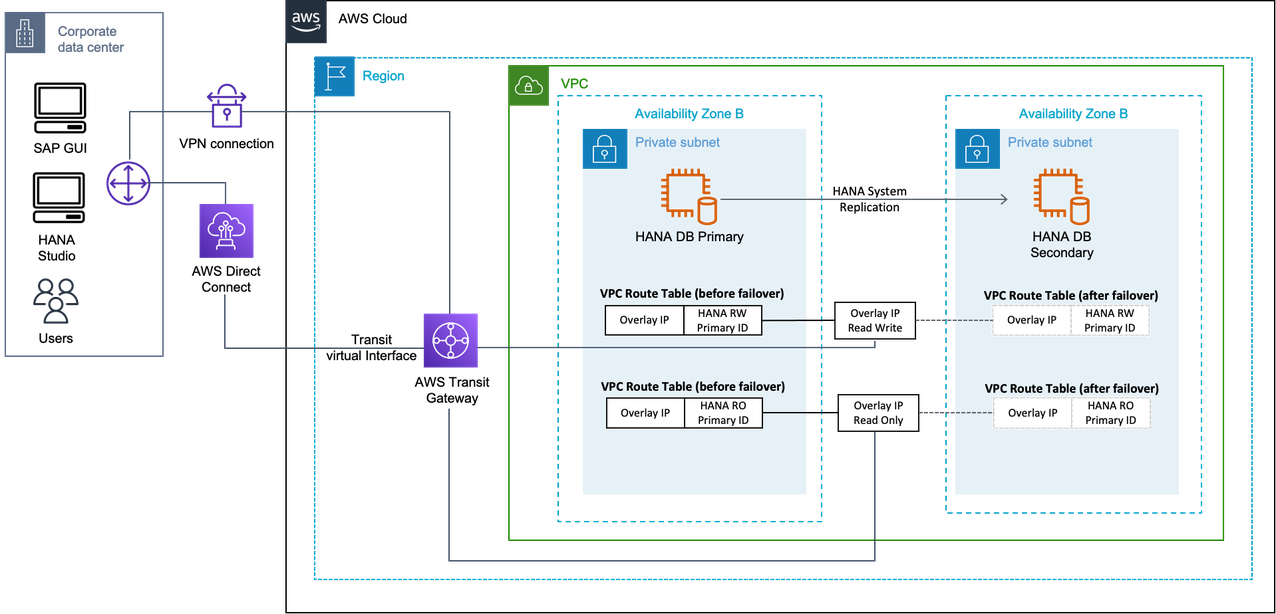
AWS Transit Gate
使用 Transit Gateway,您可以使用路由表规则,允许叠加 IP 地址与 SAP 实例通信,而无需配置任何其他组件,例如网络负载均衡器或 Route 53。您可以从另一个 VPC、另一个子网(不共享同一路由表,其中维护重叠的 IP 地址)、VPN 连接或通过公司网络的 Di AWS rect Connect 连接连接到重叠的 IP。有关更多信息,请参阅什么是 Transit Gateway?
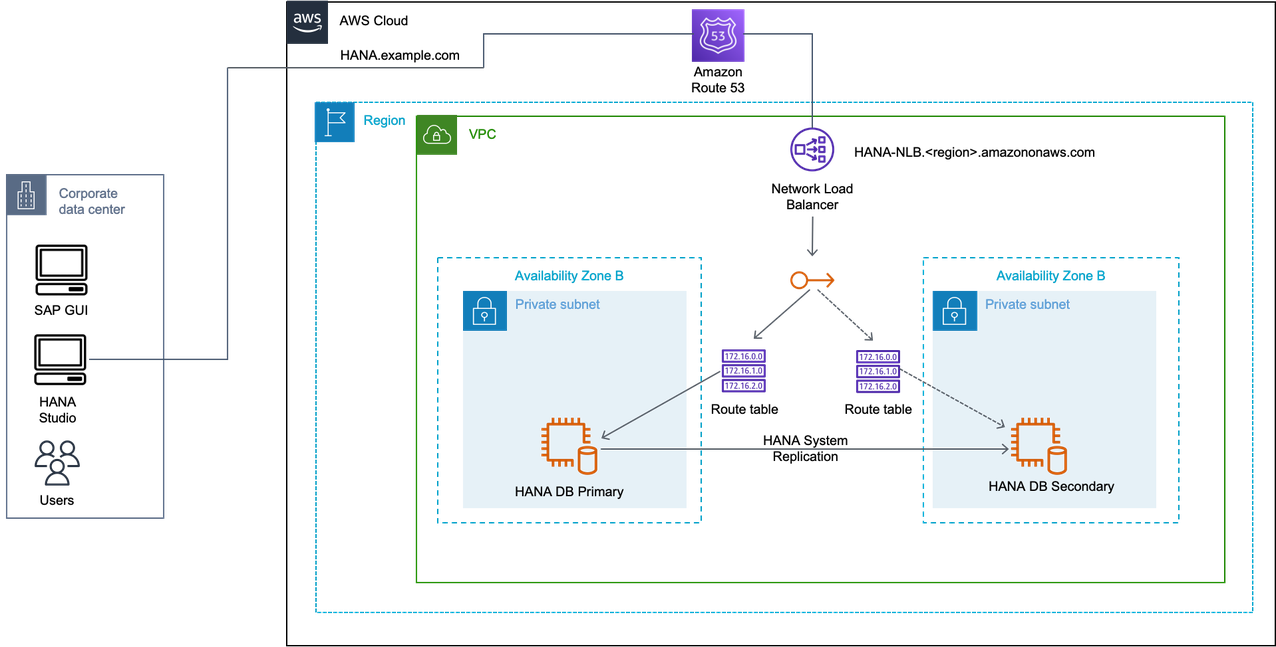
网络负载均衡器
如果您不使用 Amazon Route 53 或 T AWS ransit Gateway,则可以使用网络负载均衡器从外部访问叠加 IP 地址。Network Load Balancer 在开放系统互连 (OSI) 模型的第四层运行。它每秒可以处理数百万个请求。负载均衡器收到连接请求后,它会从 Network Load Balancer 目标组中选择一个目标,将网络连接请求路由到目标地址,可以是 Overlay 网络 IP 地址。有关更多信息,请参阅什么是 Network Load Balancer?
主动/主动高可用性场景的客户端重定向
在此配置中,您可以使用辅助只读系统的额外覆盖 IP 地址。作为群集故障转移的一部分,IP 地址绑定到主用辅助系统。辅助系统的 DNS 记录可以手动更新,也可以在接管期间使用脚本更新。
需要额外创建一个 Network Load Balancer 来平衡辅助系统的负载。
使用 Transit Gateway,您可以在辅助系统上使用叠加 IP 地址来连接运行辅助系统的亚马逊 VPC 和子网。
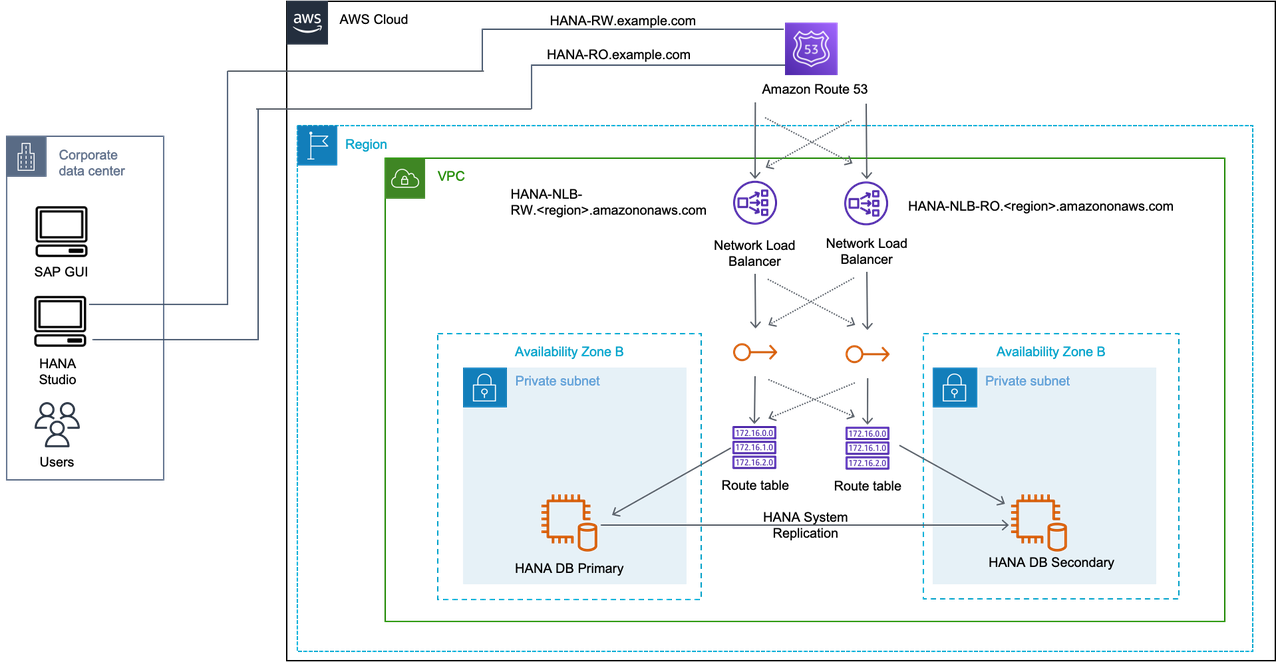
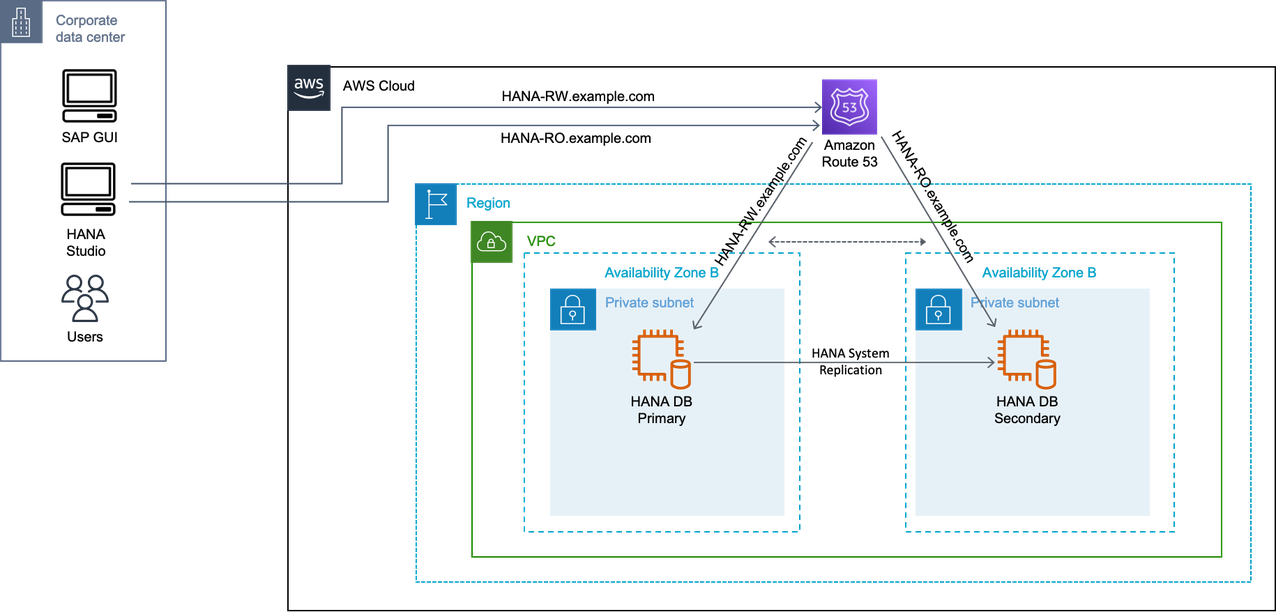
使用 DNS 的主动/主动场景
在这种情况下,您将两个 DNS 记录用于 SAP HANA 读/写主实例和 SAP HANA 只读辅助实例。在故障转移的情况下,可以自动或手动修改 DNS 记录。
使用 AWS Transit Gateway 的主动/主动场景
在这种情况下,SAP HANA 读/写主实例和 SAP HANA 只读辅助实例的两个叠加 IP 地址。在故障转移的情况下,将在其可用区域中调整路由表,然后 Transit Gateway 会将连接重新路由到这些 IP 地址。这适用于两个叠加 IP 地址。
使用 Network Load Balancer 的主动/主动场景
在这种情况下,SAP HANA read/write primary instance and SAP HANA read only secondary instance. In case of failover, the route table is adjusted in its Availability Zone, and Network Load Balancer for the read/write 或只读端点的两个叠加 IP 地址指向其可用区中的叠加 IP 地址。这适用于两个叠加 IP 地址。