可用性
可用性(又称为服务可用性)既是定量衡量韧性的常用指标,也是具有针对性的韧性目标。
-
可用性是指工作负载可供使用的时间百分比。
可供使用指的是在需要时能够履行约定的功能。
这里计算的是一段时间内的百分比,例如一个月、一年或之后的三年。最严格地来说,当应用程序不能正常运行(包括计划内和计划外的中断)时,可用性就会降低。我们按以下方式计算可用性:
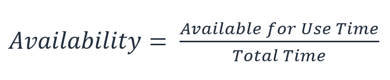
-
可用性是一段时间(通常是一个月或一年)内正常运行时间的百分比(例如 99.9%)
-
常见的简单表达方式仅指“9 的数量”;例如,“5 个 9”表示 99.999% 可用
-
在公式中,有些客户选择在总时间中排除计划内的维护停机时间(例如计划内维护)。但不建议采用这种方法,因为用户可能希望在这些时间内使用您的服务。
下表列出了常见的应用程序可用性设计目标,以及在仍然达到目标的同时,一年内可能会出现的最长中断时间。该表包含我们常常会在每个可用性层看到的应用类型示例。在本文档中,我们会引用这些值。
| 可用性 | 最大不可用性(每年) | 应用程序类别 |
|---|---|---|
| 99% | 3 天 15 小时 | 批处理、数据提取、传输和加载作业 |
| 99.9% | 8 小时 45 分钟 | 知识管理、项目跟踪等内部工具 |
| 99.95% | 4 小时 22 分钟 | 电子商务、销售点 |
| 99.99% | 52 分钟 | 视频传输、广播工作负载 |
| 99.999% | 5 分钟 | ATM 交易、电信工作负载 |
根据请求测量可用性:对服务而言,计算成功和失败的请求数可能比计算“可用时间”更容易。在这种情况下,可以采用如下计算公式:
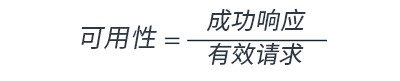
这通常以一分钟或五分钟为周期进行测量。然后,可以根据这些时间段的平均值计算每月正常运行时间百分比(基于时间的可用性测量)。如果在给定时间段内未收到任何请求,则该时间段内的可用性为 100%。
针对硬依赖关系计算可用性:许多系统对其他系统具有硬依赖关系,依赖的系统中的中断会直接转换为调用系统的中断。这与软依赖关系相反,其中依赖的系统的故障会在应用程序中得到弥补。在出现此类硬依赖关系的情况下,调用系统的可用性是依赖的系统可用性的结果。例如,如果您有一个旨在实现 99.99% 可用性的系统,它对两个其他独立系统具有硬依赖关系,这两个系统都旨在实现 99.99% 的可用性,则工作负载在理论上可以实现 99.97% 的可用性:
Availinvok × Availdep1 × Availdep2 = Availworkload
99.99% × 99.99% × 99.99% = 99.97%
因此,在计算可用性时,您一定要了解依赖项及其可用性设计目标。
针对冗余组件计算可用性:当系统涉及到使用独立的冗余组件(例如,不同可用区中的冗余资源)时,从理论上讲,可用性的计算方法是:100% 减去组件故障率的乘积。例如,如果系统使用了两个独立的组件,每个组件都具有 99.9% 的可用性,此依赖项的有效可用性为 99.9999%:

Availeffective = AvailMAX − ((100%−Availdependency)×(100%−Availdependency))
99.9999% = 100% − (0.1%×0.1%)
快捷方式计算:如果计算中所有组件的可用性仅包含数字九,则可以将九的数量相加得出答案。在上面的示例中,两个具有 3 个 9 可用性的冗余独立组件得到 6 个 9 可用性。
计算依赖项的可用性。有些依赖项会提供有关其可用性的指导,包括许多 AWS 服务的可用性设计目标。但在没有相关指导的情况下(例如,制造商未发布可用性信息的组件),一个估算方式是确定平均故障间隔时间(MTBF)和平均恢复时间(MTTR)。可以通过以下公式来确定可用性估算值:
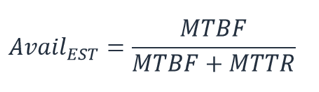
例如,如果 MTBF 为 150 天,且 MTTR 为 1 小时,则可用性估算值是 99.97%。
有关更多详细信息,请参阅 Availability and Beyond: Understanding and improving the resilience of distributed systems on AWS,了解如何计算可用性。
可用性的成本:设计应用程序来实现更高级别的可用性通常会导致成本增加,因此在开始设计应用程序之前,应该确定真正的可用性需求。高级别的可用性对彻底失败场景下的测试和验证提出了更严格的要求。它们要求从各种故障中自动恢复,并要求系统运营的所有方面都按照相同的标准进行类似的构建和测试。例如,容量的添加或删除、更新软件或配置更改的部署或回滚或者系统数据的迁移,都必须依照预期的可用性目标进行。可用性级别非常高时,软件部署的成本会增加,相应地,创新会受到影响,因为在部署系统时需要放慢行动速度。因此,这里的指导方针是,在系统运营的整个生命周期内,在应用标准和考虑适当的可用性目标时,要做得彻底。
在具有更高可用性设计目标的系统中,成本增加的另一种方式与依赖项的选择有关。在目标较高的情况下,可以选择作为依赖项的软件或服务集减少,具体取决于其中哪些服务已具备我们前面所说的深度投资。随着可用性设计目标的增加,通常要少找一些多用途服务(例如关系数据库),多找一些专用服务。这是因为后者更易于评估、测试和自动化,与包括在内但未使用的功能发生意外交互的可能性也较低。
