韧性的责任共担模式
韧性是 AWS 和您的共同责任。您要了解作为韧性一部分的灾难恢复(DR)和可用性在这个共担模式下如何运行,这很重要。
AWS 责任 – 云的韧性
对于运行 AWS Cloud 中提供的所有服务的基础设施,AWS 负责维持其韧性。此基础设施包括运行 AWS Cloud 服务的硬件、软件、网络和设施。AWS 采取合理的商业措施来提供这些 AWS Cloud 服务,确保服务可用性达到或超过 AWS 服务水平协议(SLA)
AWS 全球云基础设施
客户责任 – 云中的韧性
您的责任由您选择的 AWS Cloud 服务决定。这决定了您承担韧性责任时必须执行的配置工作量。例如,Amazon Elastic Compute Cloud(Amazon EC2)等服务要求客户执行所有必要的韧性配置和管理任务。部署 Amazon EC2 实例的客户负责在多个位置部署 Amazon EC2 实例(例如 AWS可用区),使用自动扩缩等服务实施自我修复,以及对安装在实例上的应用程序使用韧性工作负载架构最佳实践。对于托管服务(例如 Amazon S3 和 Amazon DynamoDB),AWS 会运营基础设施层、操作系统和平台,而客户访问端点即可存储和检索数据。您负责管理数据的韧性,包括备份、版本控制和复制策略。
在 AWS 区域 的多个可用区中部署工作负载是高可用性策略的一部分,该策略将问题隔离在一个可用区,同时使用其他可用区的冗余继续处理请求,以此保护工作负载。多可用区架构也是灾难恢复策略的一部分,旨在更好地隔离工作负载,防止受到停电、雷击、龙卷风、地震等事故和灾害的影响。灾难恢复策略也可以使用多个 AWS 区域。例如,在主动/被动配置中,如果主动区域不再处理请求,则工作负载的服务会从其主动区域失效转移到其灾难恢复区域。
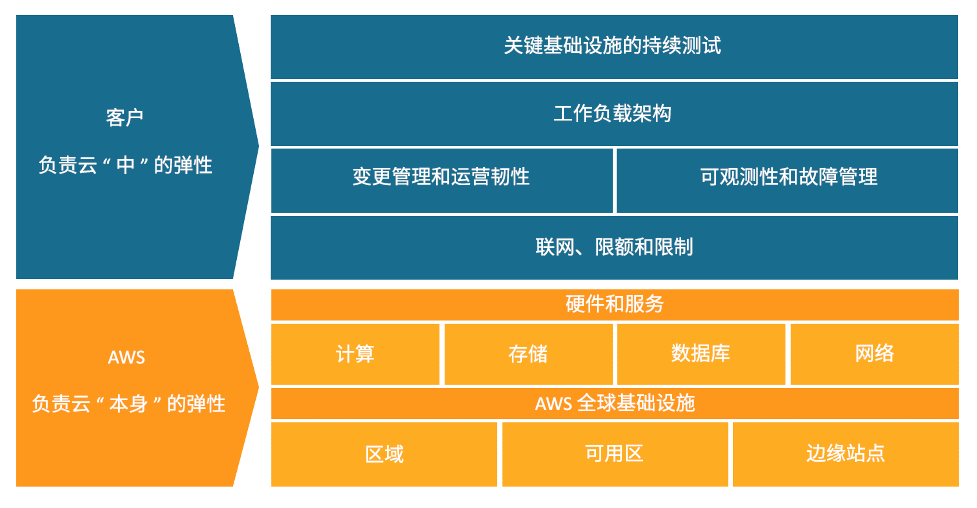
客户和 AWS 负责的云中的韧性与云的韧性
您可以使用 AWS 服务来实现韧性目标。作为客户,您负责管理系统的以下方面,以便实现云中的韧性。有关每项服务的更多详细信息,请参阅 AWS 文档。
联网、配额和限制
变更管理和运营韧性
可观测性和故障管理
工作负载架构
-
工作负载架构包括如何围绕业务领域设计服务、运用 SOA 和分布式系统设计来防止发生故障,以及如何内置节流、重试、队列管理、超时和应急措施等功能。
-
依靠经过验证的 AWS 解决方案
、Amazon Builders' Library 和 serverless patterns 来与最佳实践保持一致,从而快速启动实施。 -
通过持续改进将系统分解为分布式服务,以便更快地扩展和创新。使用 AWS 微服务
指导和托管服务选项来简化引入变更和实现创新的工作,提高完成这类工作的能力。
关键基础设施的持续测试
-
测试可靠性意味着在功能、性能和混乱层面进行测试,也意味着采用事件分析和演练日活动实践来积累专业知识,解决人们不太了解的问题。
-
对于全云部署和混合应用程序,如果知道在出现问题或组件故障时应用程序会有怎样的表现,您就可以快速和可靠地从故障中恢复。
-
创建并记录可重复的试验,了解事情未按预期发展时系统有何表现。这些测试会证明整体韧性的有效性,并在面对真正的故障场景之前为运营程序提供反馈环路。
