本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
通过数据面板控制的撤离
多种解决方案支持仅使用数据面板即可撤离可用区的操作。本部分将介绍其中三种解决方案以及使用案例,您可以根据需要进行选择。
使用任一这些解决方案时,您都需要确保剩余的可用区具备足够的容量来处理要撤离的可用区中的负载。要做到这一点,最有弹性的方法是为每个可用区预先配置所需的容量。如果您正在使用三个可用区,则除了所需容量外,每个可用区中额外部署 50% 的容量来处理峰值负载。这样,如果失去一个可用区,您所拥有的容量可以 100% 满足需求,而不必使用控制面板来配置更多容量。
此外,如果您正在使用 EC2 自动扩缩服务,请确保您的自动扩缩组 (ASG) 在转移期间不会横向缩减,这样当转移结束时,您的组中仍有足够的容量来处理您的客户流量。这一点,需要您确保自动扩缩组 (ASG) 的最低所需容量能够处理您当前的客户负载。您还可以通过在指标中使用平均值,而不是异常百分位数指标(如 P90 或 P99)来确保自动扩缩组 (ASG) 不会意外缩小。
在转移过程中,不再处理流量的资源的利用率应该非常低,而其他资源的利用率会因处理新流量而出现提升。此时要保持平均值处于稳定状态,这样可以防止出现横向缩减操作。最后,您还可以对 ALB 和 NLB 进行目标组运行状况设置,根据健康主机的百分比或数量来指定 DNS 故障转移。这样可以防止流量路由到没有足够正常运行主机的可用区。
Route 53 应用程序恢复控制器 (ARC) 中的可用区转移
第一个可用区撤离解决方案使用 Route 53 ARC 中的可用区转移。此解决方案适用于将 NLB 或 ALB 作为客户流量入口点的请求/响应工作负载。
当您检测到可用区受损时,可以使用 Route 53 ARC 启动可用区转移。此操作完成且现有缓存的 DNS 响应过期后,所有新请求将仅路由到剩余可用区中的资源。下图显示了可用区转移的工作原理。在下图中,我们有一条 www.example.com 的Route 53 别名记录,指向 my-example-nlb-4e2d1f8bb2751e6a.elb.us-east-1.amazonaws.com。可用区转移是对可用区 3 执行的。
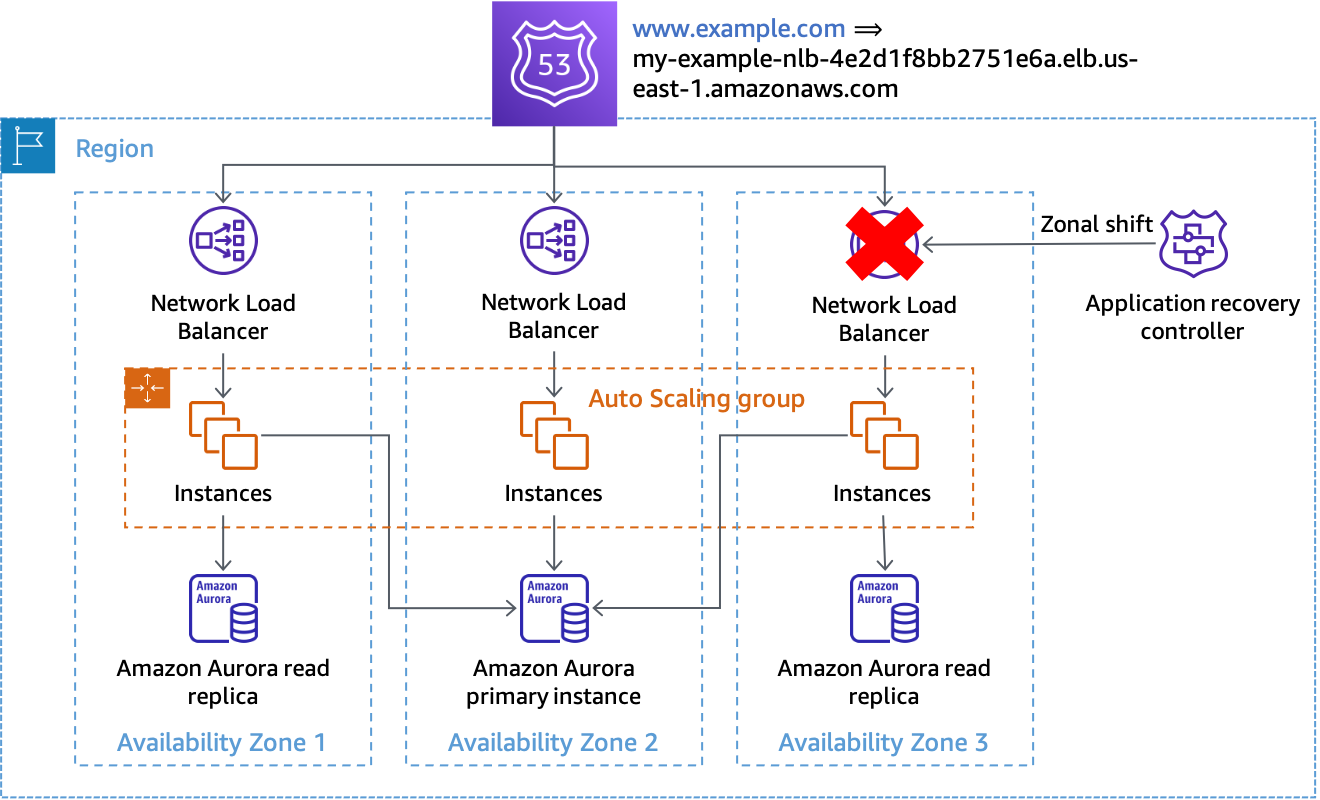
可用区转移
在示例中,如果主数据库实例不在可用区 3 中,则只需执行可用区转移即可实现撤离可用区的第一个效果,即阻止在受影响的可用区中处理工作。如果主节点位于可用区 3 中,且 Amazon RDS 未自动进行失效转移,那么您可以配合可用区转移手动启动失效转移(这需要使用 Amazon RDS 控制面板)。该操作适用于本部分介绍的所有通过数据面板控制的解决方案。
您应该使用 CLI 命令或 API 启动可用区转移,以最大限度地减少开始撤离所需的依赖项。撤离过程越简单,就越可靠。具体命令可以存储在本地运行手册中,以便待命工程师使用。可用区转移是撤离可用区时最推荐、最简单的解决方案。
Route 53 ARC
第二种解决方案使用 Route 53 ARC 的功能来手动指定特定 DNS 记录的运行状况。该解决方案的优点是使用了高度可用的 Route 53 ARC 集群数据面板,能够应对两个 AWS 区域 受损的状况。但是该解决方案会产生额外的成本,并且需要额外配置 DNS 记录。要实现此模式,您需要为负载均衡器(ALB 或 NLB)提供的可用区特定 DNS 名称创建别名记录。如下表所示:
表 3:为负载均衡器的区域 DNS 名称配置的 Route 53 别名记录
|
路由策略:加权 名称: 类型: 值: 权重: 评估目标运行状况:true |
路由策略:加权 名称: 类型: 值: 权重: 评估目标运行状况: |
路由策略:加权 名称: 类型: 值: 权重: 评估目标运行状况: |
对于每个 DNS 记录,您需要配置与 Route 53 ARC 路由控制关联的 Route 53 运行状况检查。如果您要启动可用区撤离,请将路由控制状态设置为 Off。AWS 建议您使用 CLI 或 API 执行此操作,以最大限度地减少开始可用区撤离所需的依赖项。执行此操作时的最佳实操是在本地保留 Route 53 ARC 集群端点的副本,这样当需要撤离时,就无需从 ARC 控制面板中检索这些端点。
为了最大限度地降低使用此方法时的成本,您可以在单个 AWS 账户 中创建单个 Route 53 ARC 集群和运行状况检查,并与组织中的其他 AWS 账户 共享运行状况检查use1-az1),而非可用区名称(例如,us-east-1a)来进行路由控制。这是因为 AWS 会将物理可用区随机映射到各个 AWS 账户 的可用区名称,而使用 AZ-ID 则可以始终如一地引用相同的物理位置。当您启动可用区撤离时,比如说 use1-az2,应确保每个 AWS 账户 中的 Route 53 记录集都使用 AZ-ID 映射为各个 NLB 记录配置正确的运行状况检查。
例如,假设某个 Route 53 运行状况检查与 use1-az2 的 Route 53 ARC 路由控制相关联,ID 为 0385ed2d-d65c-4f63-a19b-2412a31ef431。如果其他 AWS 账户 想要使用此运行状况检查,且将 us-east-1c 映射到 use1-az2,那么针对记录 us-east-1c.load-balancer-name.elb.us-east-1.amazonaws.com,您要使用 use1-az2 运行状况检查。在资源记录集中,您要使用运行状况检查 ID 0385ed2d-d65c-4f63-a19b-2412a31ef431。
使用自托管 HTTP 端点
您也可以通过管理自己的 HTTP 端点(用于指示特定可用区的状态)来实现此解决方案。它允许您根据来自 HTTP 端点的响应手动指定可用区何时运行状况不佳。该解决方案的成本低于使用 Route 53 ARC,但高于可用区转移,并且需要管理额外的基础设施。它的优势是可以更灵活地应对不同的场景。
该模式可以搭配使用 NLB 或 ALB 架构以及 Route 53 运行状况检查。它也可以用于非负载均衡的架构,例如服务发现或队列处理系统,在这些系统中,Worker 节点自行执行运行状况检查。在这些场景中,主机可以使用后台线程,使用其 AZ-ID(有关如何查找该 ID 的信息,请参阅 附录 A – 获取可用区 ID )定期向 HTTP 端点发出请求,然后接收有关可用区运行状况的响应。
如果可用区运行状况不佳,他们有多种响应方式可供选择。他们可以选择使来自 ELB、Route 53 等来源的外部运行状况检查或服务发现架构中的自定义运行状况检查失败,使其在这些服务中显示为状况不佳。他们也可以在收到请求后立即发出存在错误的响应,让客户端退避并重试。在事件驱动的架构中,节点可以故意无法处理工作,例如故意向队列返回 SQS 消息。在工作路由器架构(中央服务安排特定主机的工作)中,您也可以使用这种模式。路由器可以在选择工作线程、端点或单元之前检查可用区的状态。在使用 AWS Cloud Map 的服务发现架构中,您可以通过在请求中提供筛选条件(例如 AZ-ID)来发现端点
下图显示了如何将这种方法用于多种类型的工作负载。
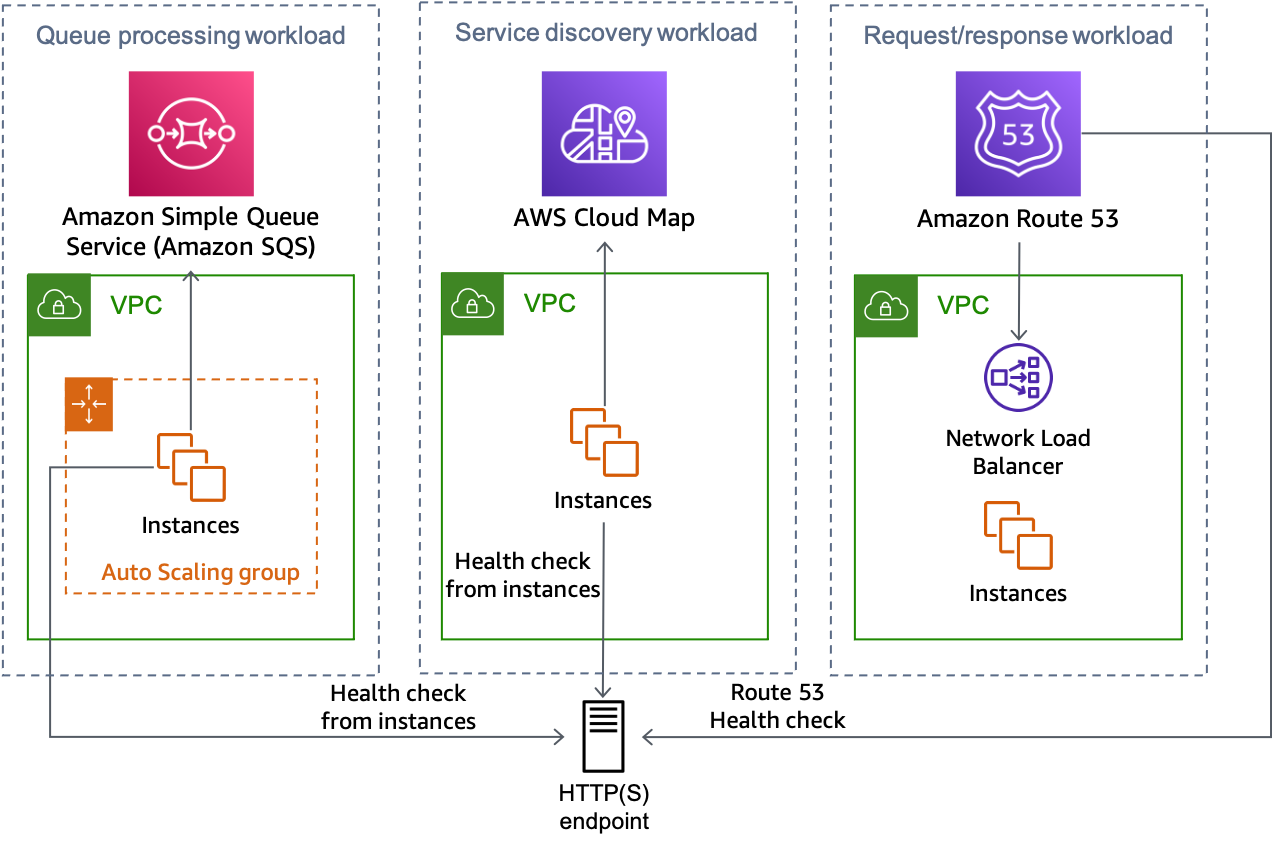
多种工作负载类型均可使用 HTTP 端点解决方案
您可以通过多种方法实现 HTTP 端点,接下来将简要介绍其中两种。
使用 Amazon S3
这种模式最初出现在该博客文章
在这种场景中,您将为每个区域 DNS 记录创建 Route 53 DNS 资源记录集(与上面的 Route 53 ARC 场景相似)和相关的运行状况检查。但是,在此实施中,您无需将运行状况检查与 Route 53 ARC 路由控制相关联,而是将其配置为使用 HTTP 端点,并进行反转以防止 Amazon S3 中的损坏意外触发撤离。当对象不存在时,运行状况检查结果为正常;当对象存在时,结果为不正常。设置如下表所示。
表 4:根据可用区使用 Route 53 运行状况检查时 DNS 记录的配置
|
运行状况检查类型: 监控端点 协议: ID: URL: |
运行状况检查类型: 监控端点 协议: ID: URL: |
运行状况检查类型: 监控端点 协议: ID: URL: |
← | 运行状况检查 |
| ↑ | ↑ | ↑ | ||
|
路由策略:加权 名称: 类型: 值: 权重: 评估目标运行状况: |
路由策略:加权 名称: 类型: 值: 权重: 评估目标运行状况: |
路由策略:加权 名称: 类型: 值: 权重: 评估目标运行状况: |
← | 权重均匀的顶层别名 A 记录指向 NLB AZ 特定端点 |
假设可用区 us-east-1a 映射到我们有工作负载且要执行可用区撤离的账户 use1-az3。为 us-east-1a.load-balancer-name.elb.us-east-1.amazonaws.com 创建的资源记录集会关联运行状况检查,来测试 URL https://。要为 bucket-name.s3.us-east-1.amazonaws.com/use1-az3.txtuse1-az3 启动可用区撤离时,请使用 CLI 或 API 将名为 use1-az3.txt 的文件上传到存储桶。该文件不需要包含任何内容,但必须是公开的,以便 Route 53 运行状况检查进行访问。下图演示了如何使用该实现撤离 use1-az3。
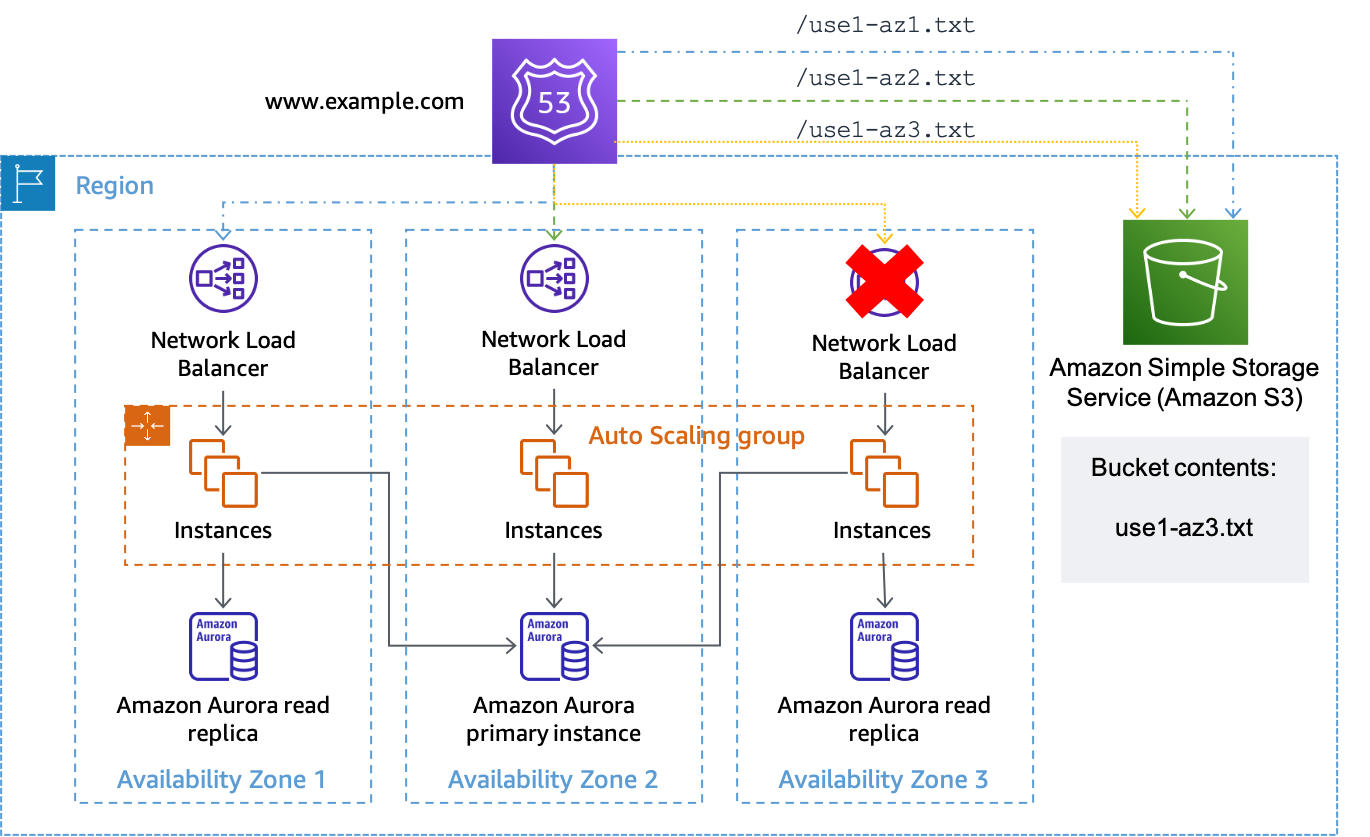
将 Amazon S3 作为 Route 53 运行状况检查的目标
使用 API Gateway 和 DynamoDB
此模式的第二种实现使用 Amazon API Gateway
如果您将此解决方案与 NLB 或 ALB 架构搭配使用,请按照上文 Amazon S3 示例中的相同方式设置 DNS 记录,不过要更改运行状况检查路径以使用 API Gateway 端点并在 URL 路径中提供 AZ-ID。例如,如果将 API Gateway 自定义域配置为 az-status.example.com,则 use1-az1 的完整请求为 https://az-status.example.com/status/use1-az1。如果您想要启动可用区撤离,可以使用 CLI 或 API 创建或更新 DynamoDB 项目。该项目使用 AZ-ID 作为其主键,然后会有一个名为 Healthy 的布尔属性,用于指示 API Gateway 的响应方式。以下是 API Gateway 配置中用于做出此决定的示例代码。
#set($inputRoot = $input.path('$')) #if ($inputRoot.Item.Healthy['BOOL'] == (false)) #set($context.responseOverride.status = 500) #end
如果该属性为 true(或不存在),API Gateway 会使用 HTTP 200 来响应运行状况检查;如果该属性为 false,则使用 HTTP 500 进行响应。此实现如下图所示。
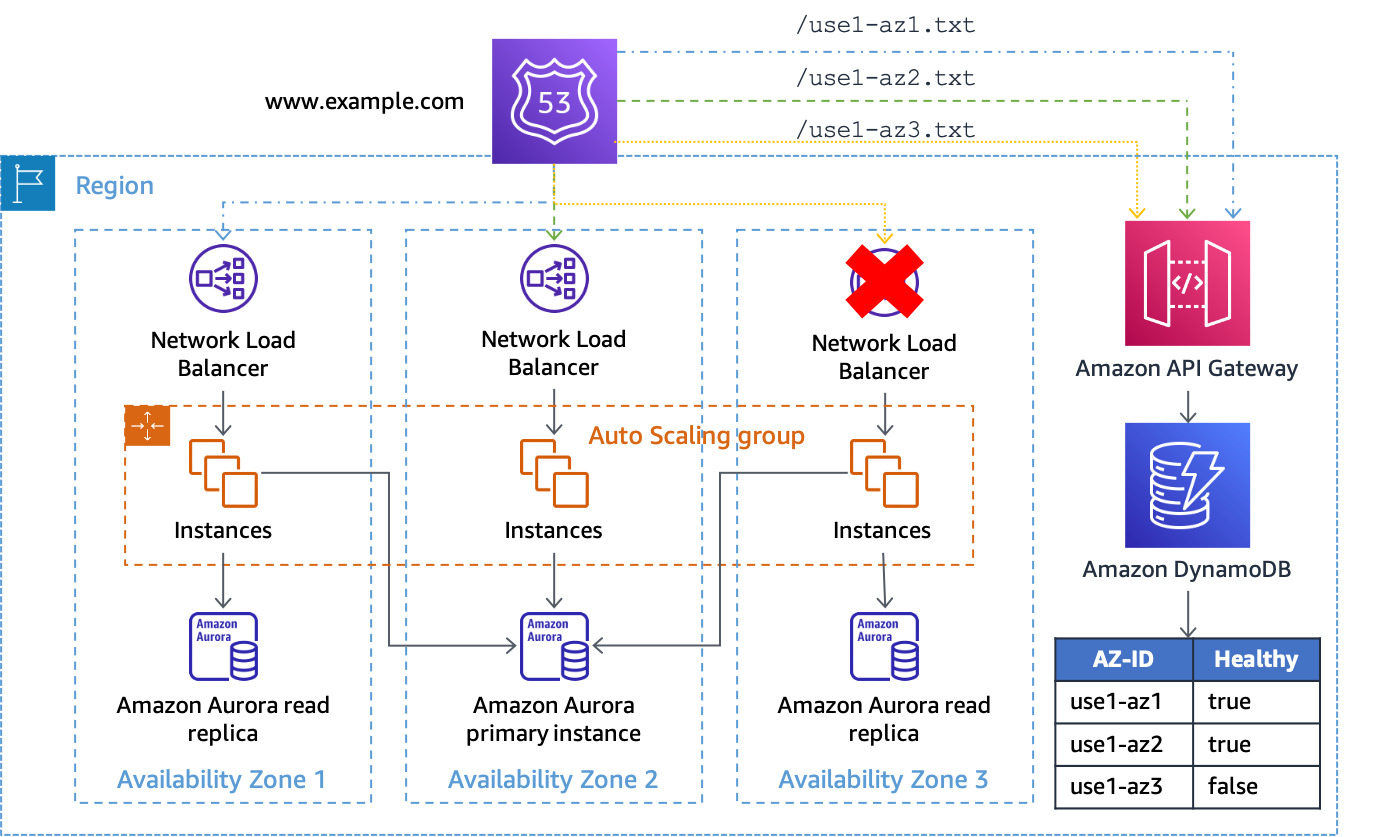
将 API Gateway 和 DynamoDB 作为 Route 53 运行状况检查的目标
在此解决方案中,您需要在 DynamoDB 前面使用 API Gateway,这样您就可以公开端点,并将请求 URL 附加到 DynamoDB 的 GetItem 请求中。该解决方案非常灵活,允许您在请求中包含其他数据。例如,如果您想创建更精细的状态,例如根据应用程序,则可以将运行状况检查 URL 配置为在路径中提供应用程序 ID 或与 DynamoDB 项目匹配的查询字符串。
可用区状态端点可以集中部署,这样不同 AWS 账户 的多个运行状况检查资源都可以使用相同且一致的可用区运行状况视图(确保您的 API Gateway REST API 和 DynamoDB 表经过扩展来处理负载),且无需共享 Route 53 运行状况检查。
您也可以使用 Amazon DynamoDB 全局表
如果您为单个主机构建解决方案,并利用该解决方案确定可用区运行状况,那么作为替代方案,您可以使用推送通知,而不用为运行状况检查提供拉取机制。实现此操作的一种方法是通过您的使用者订阅的 SNS 话题。当您想要触发断路器时,请向 SNS 主题发布一条消息,指明哪个可用区受损。这种方法与前一种方法各有利弊。它无需创建和运行 API Gateway 基础设施,也无需执行容量管理。它还可能更快地汇总可用区状态。但是,它无法执行临时查询功能,且依赖 SNS 传输重试策略来确保每个端点都能收到通知。它还要求每个工作负载或服务都构建一种接收 SNS 通知并对其采取操作的方法。
例如,启动的每个新 EC2 实例或容器都需要在引导期间使用 HTTP 端点订阅主题。然后,每个实例都需要实现软件,以监听发送通知的端点。此外,如果实例受到该事件的影响,则可能不会收到推送通知并继续工作。然而,借助拉取通知,实例将知道其拉取请求是否失败,并可以选择采取什么应对措施。
发送推送通知的第二种方法是使用长期 WebSocket 连接。Amazon API Gateway 可用于提供 WebSocket API,以供使用者连接和接收后端服务发送的消息。借助 WebSocket,实例既可以定期执行拉取操作以确保其连接正常,又可以接收低延迟推送通知。
