本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
可用性和依赖项
在上一节中,我们提到工作负载的组件包括硬件、软件,还可能包括其他分布式系统。我们将这些组件称为依赖项,即工作负载为了实现功能而需要依赖的事物。依赖项包括硬依赖项,即工作负载要发挥作用就离不开的事物,还包括软依赖项,其不可用性在一段时间内可能会被忽视或容许。硬依赖项会直接影响工作负载的可用性。
我们可能想要尝试计算工作负载的理论最大可用性。这个数值是包括软件本身在内的所有依赖项的可用性的乘积,(αn 是单个子系统的可用性),因为每个依赖项都必须正常运行。
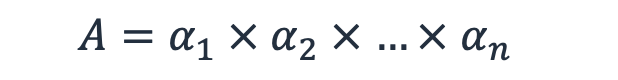
公式 4 - 理论最大可用性
这种计算中使用的可用性数字通常与 SLA 或服务级别目标 (SLO) 之类的内容相关联。SLA 定义了客户将获得的预期服务级别、用于衡量服务的指标,以及未能达到服务级别时采取的补救措施或惩罚(通常是金钱)。
使用上面的公式,我们可以得出结论:纯粹从数学上讲,工作负载的可用性不会高于其任何依赖项。但实际上,我们通常看到的情况并非如此。如果一个工作负载两个或三个具有 99.99% 可用性 SLA 的依赖项,那么工作负载本身仍然可以实现 99.99% 或更高的可用性。
这是因为像上一节所说那样,这些可用性数字是估计值。我们会估计或预测故障发生的频率以及修复故障的速度。估计的数字并不代表一定会停机。依赖项的表现经常会超出其可用性 SLA 或 SLO 的规定。
依赖项为发挥性能而设定的内部可用性目标也可能高于公开 SLA 中的数字。这样可以提高在发生未知或不可知情况时仍然符合 SLA 的可能性。
最后,工作负载的依赖项可能具有不为人知的 SLA,或者不提供 SLA 或 SLO。例如,全球互联网路由是许多工作负载的常见依赖项,但我们很难知道自己全球流量正在使用哪家互联网服务提供商、他们是否具有 SLA,以及 SLA 在不同提供商之间的一致性如何。
这一切都告诉我们,计算最大理论可用性只可能得出粗略的数量级计算结果,但其本身可能并不准确,或者无法提供有意义的见解。从数学公式中可以看出,工作负载依赖的东西越少,发生故障的总体可能性就越低。小于一的数字越少,乘积就越大。
规则 3
减少依赖项可以对可用性产生积极影响。
数学计算还可以对依赖项选择过程起到辅助作用。选择过程会影响您如何设计工作负载、如何利用依赖项中的冗余来提高其可用性,以及您将其视为软依赖项还是硬依赖项。我们应该谨慎选择可能影响工作负载的依赖项。下一条规则提供了这方面的指导。
规则 4
通常应该选择可用性目标等于或高于工作负载目标的依赖项。
