本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
分布式系统可用性
分布式系统由软件组件和硬件组件组成。有些软件组件本身可能是另一个分布式系统。底层硬件和软件组件的可用性会影响工作负载的可用性。
使用 MTBF 和 MTTR 来计算可用性的方法起源于硬件系统。但是,分布式系统发生故障的原因与硬件故障原因截然不同。制造商始终可以计算出硬件组件失效前的平均时间,但分布式系统的软件组件却无法进行这种测试。硬件通常遵循“浴缸式”故障率曲线,而软件因为每次发布新版本时都会引入额外的缺陷,所以会形成交错式曲线(参见软件可靠性
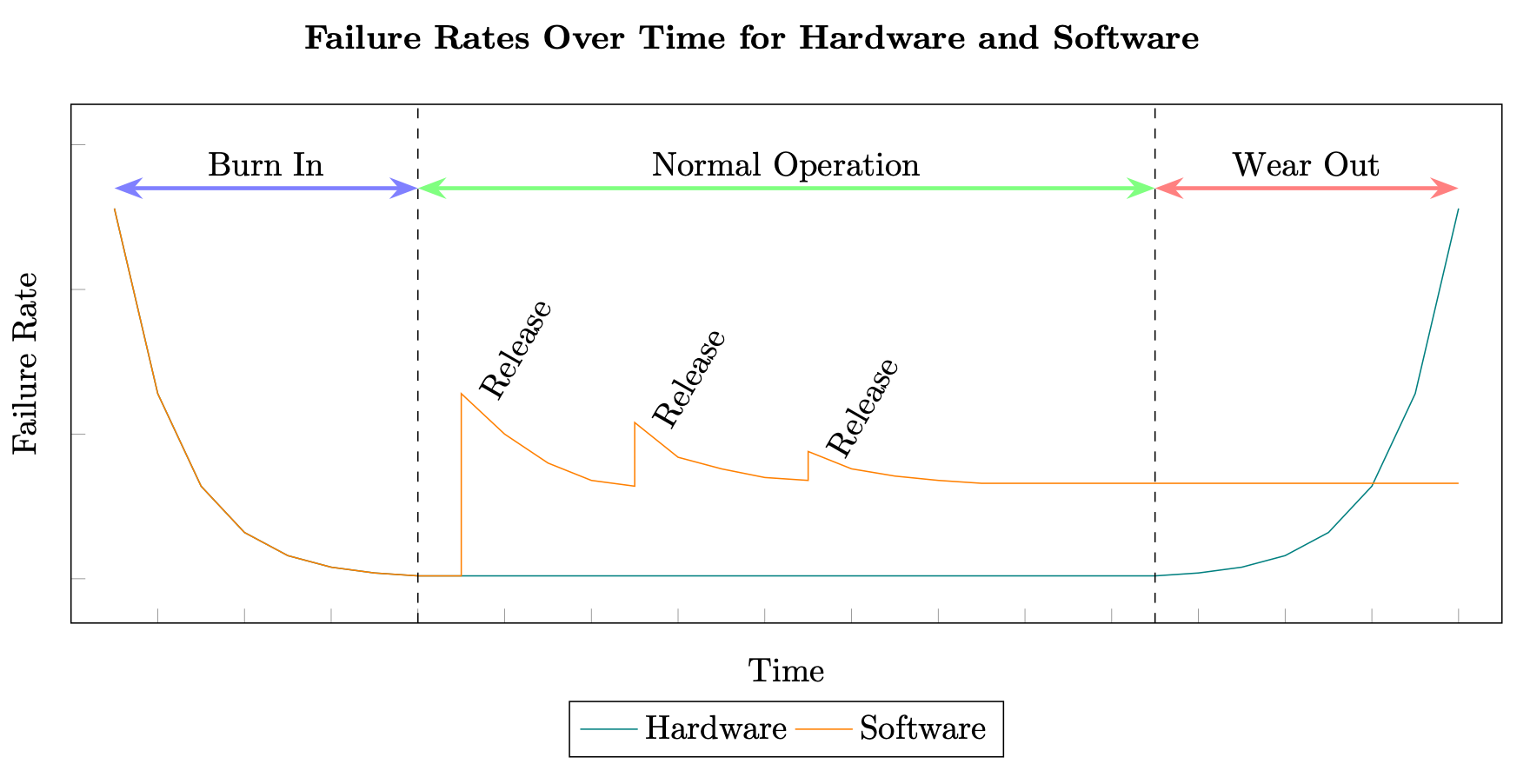
硬件和软件故障率
此外,分布式系统中软件的变化速度往往比硬件高很多。例如,标准磁性硬盘的平均年化故障率 (AFR) 可能为 0.93%,对于硬盘驱动器来说,这实际上意味着在达到失效期之前其至少有 3-5 年的使用寿命,甚至可能更长(参见 Backblaze
硬件还存在计划性报废的概念,即具有设定的使用寿命,需要在一定时间后更换。(参见灯泡大阴谋
所有这些都意味着用于确定硬件 MTBF 和 MTTR 的各种测试和预测模型并不适用于软件。自 20 世纪 70 年代以来,人们数百次尝试通过建立模型来解决这个问题,但一般都没有脱离预测建模和估计建模的范畴。(参见软件可靠性模型列表
因此,要计算分布式系统未来的 MTBF 和 MTTR,从而确定未来的可用性,我们始终需要依赖某种类型的预测。我们可以通过预测建模、随机仿真、历史分析或严格测试来生成计算结果,但这些计算结果并不能成为正常运行时间或停机时间的保证。
过去导致分布式系统出现故障的原因可能永远不会再次出现。未来造成故障的原因可能截然不同,甚至完全不可知。对于未来的故障,所需的恢复机制也可能与过去的机制不同,所花费的时间也大不相同。
此外,MTBF 和 MTTR 均为平均值。平均值与实际值之间会有一些差异(通过标准差 σ 来衡量这种差异)。因此,在实际生产使用中,工作负载在故障与恢复之间的时间可能会更短或更长。
但是,构成分布式系统的软件组件的可用性仍然非常重要。软件可能由于多种原因(下一节会详细介绍)而发生故障,并影响工作负载的可用性。因此,对于高可用性分布式系统来说,软件组件可用性的计算、衡量和提高应该得到与硬件和外部软件子系统同等的重视。
规则 2
工作负载中的软件可用性是决定工作负载总体可用性的一项重要因素,应与其他组件同等重视。
值得注意的是,尽管分布式系统的 MTBF 和 MTTR 很难预测,但它们仍然可以为提高可用性提供重要信息。降低故障频率(提高 MTBF)和缩短故障发生后的恢复时间(缩短 MTTR)都可以提高实证可用性。
分布式系统中的故障类型
分布式系统中通常存在两类影响可用性的错误,分别叫做波尔错误和海森堡错误(参见“Bruce Lindsay 访谈”,ACM Queue 第 2 卷,第 8 号 – 2004 年 11 月
波尔错误是可以重复出现的功能性软件问题。给定相同的输入,就能始终产生相同的错误输出(如同确定性玻尔原子模型一样,稳定并且容易检测)。工作负载进入生产环境后,这类错误非常少见。
海森堡错误是一种短暂的错误,只发生在特定和不常见条件下。这些条件通常与硬件(例如瞬时设备故障或寄存器大小等硬件实现细节)、编译器优化和语言实现、限制条件(例如存储空间暂时不足)或竞争条件(例如不使用信号量进行多线程操作)等内容相关。
生产环境中的大部分错误都是海森堡错误,这种错误难以捉摸,当我们尝试进行观察或调试时,它们似乎会改变行为或消失,因此很难被发现。但是,如果重新启动程序,那么失败的操作很可能会成功,因为操作环境略有不同,消除了引发海森堡错误的条件。
因此,生产环境中的大多数故障都是暂时性的,当重试操作时,故障不太可能再次出现。为了保持韧性,分布式系统必须能够承受海森堡错误。我们将在提高分布式系统 MTBF 一节探讨如何实现这一目标。
