本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
衡量可用性
如上文所述,针对分布式系统创建有前瞻性的可用性模型是一项难以实现的任务,而且可能无法提供所需的见解。更实用的方式是建立起一致的方法来衡量工作负载的可用性。
如果用正常运行时间和停机时间来衡量可用性,那么故障就是一种二元选择:工作负载要么正在运行,要么就没有运行。
但是,这种情况很少见。故障会产生特定程度的影响,通常发生在工作负载的某些子集中,并会影响一定比例的用户、请求、位置,或者对延迟产生一定影响。这些都属于部分故障模式。
尽管 MTTR 和 MTBF 可以帮助我们了解影响系统可用性的因素以及如何提高可用性,但它们并不是衡量可用性的实证指标。此外,工作负载由许多组件组成。例如,像支付处理系统这样的工作负载包含许多应用程序编程接口 (API) 和子系统。所以,整个工作负载的可用性实际上是一个复杂而微妙的概念。
在本节中,我们将探讨以实证方式衡量可用性的三种方法:服务器端请求成功率、客户端请求成功率和年度停机时间。
服务器端和客户端请求成功率
前两种方法非常相似,只是从测量的角度来看有所不同。服务器端指标可以从服务中的工具中收集。但这些指标并不完整。如果客户无法访问服务,您就无法收集客户端指标。为了了解客户体验,我们可以不依赖客户对失败请求的反馈,而是使用金丝雀这种定期探测您的服务并记录指标的软件来模拟客户流量,从而收集客户端指标。
利用这两种指标,我们可以用成功处理的有效工作单元除以服务收到的有效工作单元的总数(忽略无效的工作单元,例如导致 404 错误的 HTTP 请求),从而得出可用性。

公式 8
对于基于请求的服务,工作单元是请求,例如 HTTP 请求。对于基于事件或基于任务的服务,工作单元是事件或任务,例如处理队列中的消息。这种可用性衡量标准在短时间间隔内是有意义的,例如一分钟或五分钟内。它也最适合从精细的角度分析,例如基于请求的服务在 API 层面的可用性。下图显示了以这种方式计算出的可用性随着时间的变化。图表上的每个数据点都通过公式 (8) 计算得出,时间窗口为五分钟(您可以选择其他时间维度,例如一分钟或十分钟的间隔)。例如,数据点 10 显示可用性为 94.5%。这意味着在 t+45 到 t+50 分钟内,如果服务收到了 1000 个请求,则只有 945 个请求被成功处理。
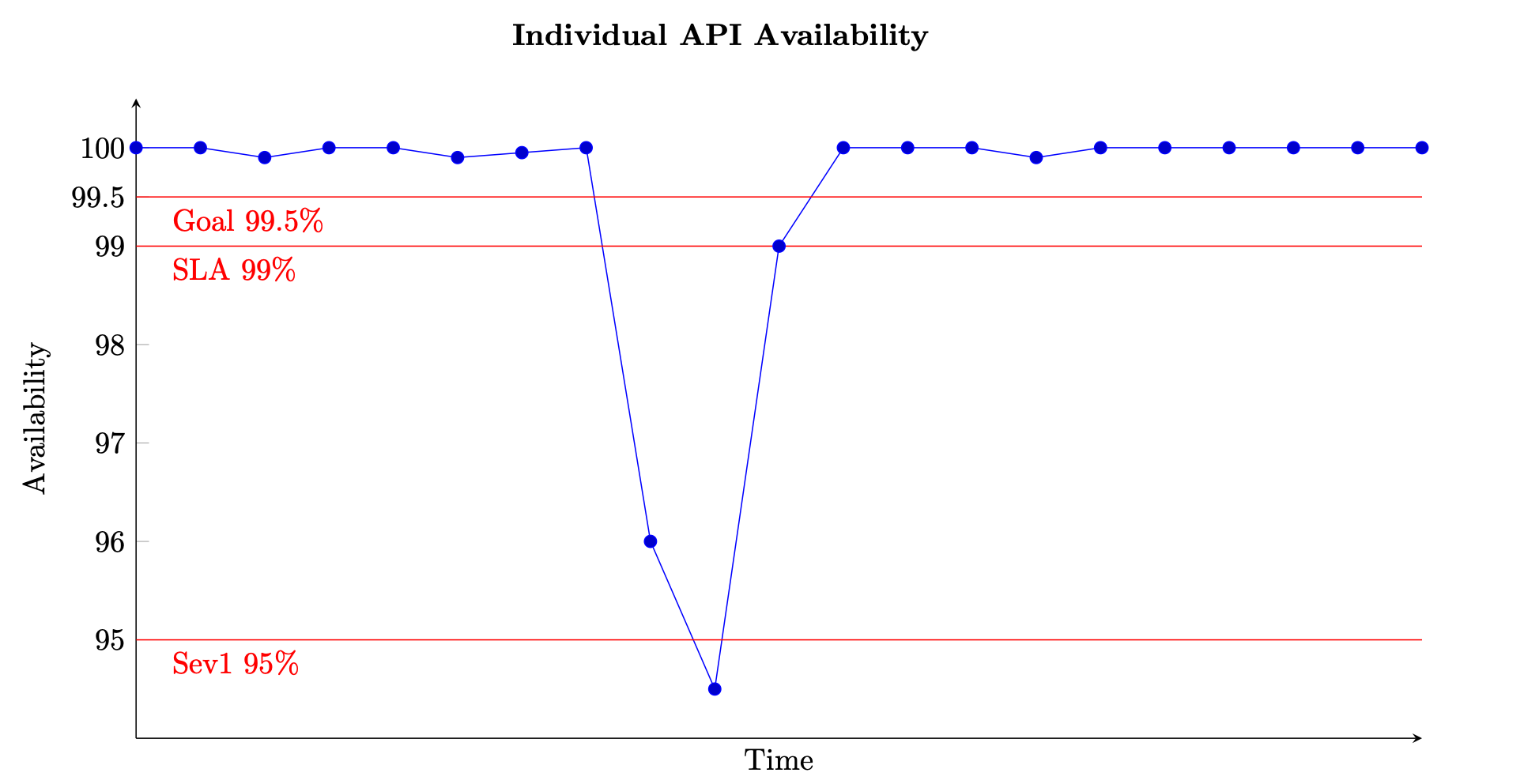
单个 API 的可用性随时间变化的示例
图中还显示了 API 的可用性目标为 99.5%,为客户提供的服务级别协议 (SLA) 规定的可用性为 99%,高严重性警报阈值为 95%。如果没有不同的阈值作为背景,可用性图表就可能无法提供有关服务运行情况的重要信息。
我们也希望能够跟踪和描述更大的子系统(例如控制平面或整个服务)的可用性。实现这一目标的一种方法是计算每个子系统的每个五分钟数据点的平均值。生成的图表与上图类似,但输入值更多。构成服务的所有子系统都具有相同的权重。另一种方法可以是汇总从服务中的所有 API 收到的和被成功处理的所有请求,用来计算五分钟时间间隔内的可用性。
但是,后一种方法可能会隐藏吞吐量和可用性都比较低的 API。举一个简单的例子:假设某项服务有两个 API。
第一个 API 在五分钟内收到了 100 万个请求,并成功处理了 99.9 万个请求,可用性达到 99.9%。第二个 API 在五分钟内收到了 100 个请求,但仅成功处理了 50 个请求,可用性只有 50%。
如果我们将来自每个 API 的请求相加,则总共有 1000100 个有效请求,其中 999050 个请求被成功处理,因此该服务的总体可用性为 99.895%。但是,如果我们将前一种方法计算出的两个 API 的可用性取平均值,则得出的可用性为 74.95%,这也许更能反映实际体验。
这两种方法都没有错误,重点在于我们想通过可用性指标了解哪些信息。如果您的工作负载的每个子系统收到的请求量相似,则您可以优先考虑汇总计算所有子系统的请求。这种方法侧重于请求本身及其成功与否,以此作为可用性和客户体验的衡量标准。如果请求量存在差异,您也可以选择将子系统的可用性取平均值,均衡地体现每个子系统的重要性。这种方法侧重于子系统以及每个子系统反映客户体验的能力。
年度停机时间
第三种方法是计算年度停机时间。这种形式的可用性指标更适合长期目标的设定和回顾。它需要对工作负载的停机时间作出定义。然后,您可以计算工作负载未处于“中断”状态的时间占给定的总时间的比例,从而衡量可用性。
对于某些工作负载,停机时间可以定义为单个 API 或工作负载的单项功能在一分钟或五分钟时间间隔内的可用性降至 95% 以下的时间(如之前的可用性图表所示)。您也可以只考虑停机时间,因为它适用于关键数据平面操作的子集。例如,针对 SQS 可用性的 Amazon 消息收发 (SQS, SNS) 服务水平协议
更大、更复杂的工作负载可能需要定义系统范围的可用性指标。对于大型电子商务网站,系统范围指标可以是客户订单率等指标。在这种情况下,停机时间可以是在任何五分钟时间段内,与预测数量相比,订单数量下降 10% 或以上的时间。
无论采用哪种方法,您都可以将所有停机时间相加以计算年度可用性。例如,如果在一个日历年内,有 27 段五分钟停机时间(其定义为任何数据平面 API 的可用性降至 95% 以下),则总停机时间为 135 分钟(有些五分钟时段可能是连续的,有些是单独的),则年度可用性为 99.97%。
这种衡量可用性的方法可以提供客户端和服务器端指标中缺少的数据和见解。例如,假设某个工作负载受损,错误率明显升高。这种工作负载的客户可能会完全停止调用其服务。他们可能已经激活了断路器,或者按照灾难恢复计划
延迟
最后,测量工作负载中的工作单元的处理延迟也很重要。按照既定的 SLA 完成工作是可用性的一种体现。如果在返回响应前客户端已经超时,则客户端会认为请求失败,工作负载不可用。但是在服务器端,请求可能会被视为已成功处理。
测量延迟为可用性的评估提供了另一个视角。百分位数和切尾均值都适合用来测量延迟。测量对象通常是第 50 个百分位数(P50 和 TM50)和第 99 个百分位数(P99 和 TM99)。我们应该使用金丝雀来测量延迟以便反映客户体验,同时也使用服务器端指标进行测量。当某些延迟百分位数(例如 P99 或 TM99.9)的平均值超过目标 SLA 时,您可以认为出现停机,并将其纳入年度停机时间的计算范围。
