第 4 步:评估预测器
机器学习中的典型工作流程包括在训练集上训练一组模型或模型组合,并评测其在保留数据集上的精度。本部分讨论如何拆分历史数据,以及在时间序列预测中使用哪些指标来评估模型。对于预测,回溯测试技术是评测预测精度的主要工具。
回溯测试
正确的评估和回溯测试框架是使机器学习应用程序取得成功的最重要因素之一。您可以依靠对模型的成功回溯测试,获得对模型的未来预测能力的信心。此外,您可以通过超参数优化(HPO)调整模型,了解模型组合,并启用元学习和 AutoML。
就评估和回溯测试方法而言,时间序列预测特征时间使其与应用了机器学习的其他领域有所不同。在机器学习任务中,要评测回溯测试中的预测错误,通常需要按商品拆分数据集。例如,要在图像相关任务中进行交叉验证,您需要对一定比例的图片进行训练,然后使用其他一些图片进行测试和验证。在预测中,您需要主要按时间进行拆分(在较小程度上按商品进行拆分),以确保不会将训练集内的信息泄露到测试集或验证集,并且尽可能真实地模拟生产案例。
必须谨慎地按时间拆分,因为您不希望选择单个时间点,而是要选择多个时间点。否则,精度会过度依赖于拆分点所定义的预测开始日期。滚动预测评估,即针对多个时间点进行一系列拆分并输出平均结果,从而获得更稳健、更可靠的回溯测试结果。下图说明了四种不同的回溯测试拆分。

四种不同的回溯测试场景的示意图,这些场景的训练集大小不断增加,但测试大小恒定
在上图中,所有回溯测试场景都提供完整的数据,以便能够根据实际值评估预测值。
之所以需要多个回溯测试窗口,是因为现实世界中大多数时间序列内的变化通常并不平稳。案例研究中的电子商务业务位于北美,其大部分产品需求是由第 4 季度的峰值推动的,尤其是感恩节前后和圣诞节前的峰值。在第 4 季度的购物季中,时间序列的变异性高于今年其余时间。通过设置多个回溯测试窗口,您可以在更平衡的设置中评估预测模型。
对于每个回溯测试场景,下图显示了 Amazon Forecast 术语中的基本元素。Amazon Forecast 会自动将数据拆分成训练数据集和测试数据集。Amazon Forecast 可确定如何使用在 create_predictor API 中指定为参数的 BackTestWindowOffset 参数来拆分输入数据,或者使用该参数的默认值 ForecastHorizon。
在下图中,您可以看到更常见的前一种情况,即 BackTestWindowOffset 和 ForecastHorizon 参数不相等。BackTestWindowOffset 参数定义虚拟预测的开始日期,如下图中的垂直虚线所示。它可以用来回答以下假设问题:如果在这一天部署模型,预测会是什么? ForecastHorizon 定义从虚拟预测开始日期到实际预测的时间步数。
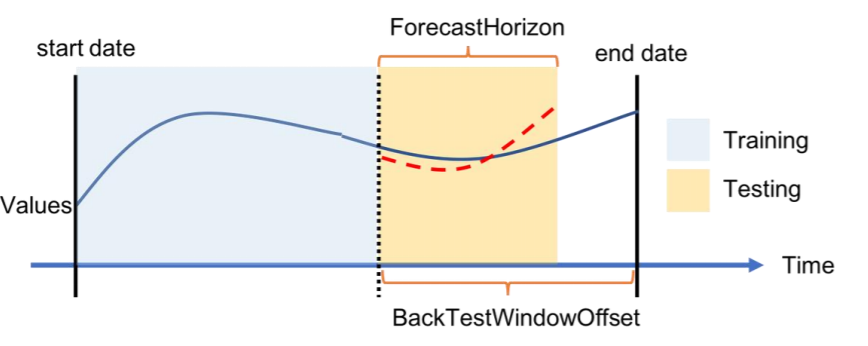
Amazon Forecast 中单个回溯测试场景及其配置的示意图
Amazon Forecast 可以导出回溯测试期间生成的预测值和精度指标。导出的数据可用于评估特定时间点和分位数下的特定商品。
预测分位数和精度指标
预测分位数可以为预测提供上限和下限。例如,使用预测类型 0.1(P10)、0.5(P50)和 0.9(P90),可以提供一系列值,即 P50 预测周围的 80% 置信区间。通过在 P10、P50 和 P90 处生成预测,您能够预期 80% 的真实值会介于这些上下限之间。
本文进一步讨论了第 5 步中的分位数。
Amazon Forecast 在回溯测试期间使用加权分位数损失(wQL)、均方根误差(RMSE)和加权绝对百分比误差(WAPE)精度指标来评估预测器。
加权分位数损失(wQL)
加权分位数损失(wQL)误差指标可衡量模型在指定分位数下的预测精度。当预测不足和过度预测的代价不同时,它特别有用。设置 wQL 函数的权重(τ)会自动纳入对预测不足和过度预测的不同惩罚措施。
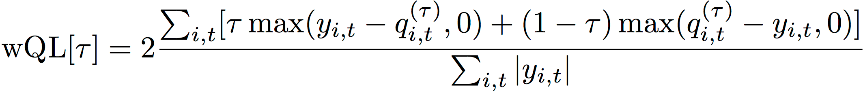
wQL 函数
其中:
-
τ – 数据集内的分位数 {0.01,0.02,...,0.99}
-
qi,t(τ) – 模型预测的 τ 分位数。
-
yi,t – 点 (i,t) 处的观测值
加权绝对百分比误差(WAPE)
加权绝对百分比误差(WAPE)是衡量模型精度的常用指标。它测量预测值与观测值的总体偏差。
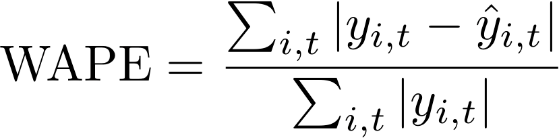
WAPE
其中:
-
yi,t – 点 (i,t) 处的观测值
-
ŷi,t – 点 (i, t) 处的预测值
预测使用预测均值作为预测值 ŷi,t。
均方根误差(RMSE)
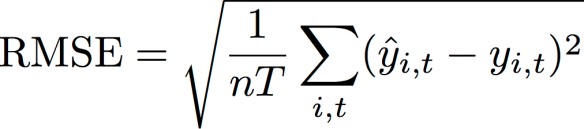
均方根误差(RMSE)是衡量模型精度的常用指标。与 WAPE 一样,它衡量估计值与观测值的总体偏差。
其中:
-
yi,t – 点 (i,t) 处的观测值
-
ŷi,t – 点 (i, t) 处的预测值
-
nT – 测试集内的数据点数量
预测使用预测均值作为预测值 ŷi,t。计算预测器指标时,nT 是回溯测试窗口中的数据点数。
WAPE 和 RMSE 存在问题
在大多数情况下,可以在内部生成的点预测或通过其他预测工具生成的点预测应与 p50 分位数或预测均值相匹配。对于 WAPE 和 RMSE,Amazon Forecast 使用预测均值来表示预测值(yhat)。
对于 wQL[tau] 方程中的 tau = 0.5,两个权重相等,并且 wQL[0.5] 简化为用于点预测的常用加权绝对百分比误差(WAPE):
![wQL[0.5] 方程的图片。](images/wql.png)
其中 yhat = q(0.5) 表示计算预测。在 wQL 公式中使用比例因子 2 来抵消 0.5 因子,以获得精确的 WAPE[median] 表达式。
请注意,WAPE 的上述定义不同于平均绝对百分比误差(MAPE
与 tau 的加权分位数损失指标不等于 0.5 不同,每个分位数的固有偏差无法通过像 WAPE 这样权重相等的计算来捕获。WAPE 还有其他缺点,包括它不对称,对于小数字,误差百分比过高,并且只是一个按点的指标。
RMSE 是 WAPE 中误差项的平方,也是其他机器学习应用程序中常见的误差指标。RMSE 指标会促成一个模型,其中各个误差具有一致的幅度,因为大的误差变化将按比例过大地增大 RMSE。由于平方误差的存在,因此在一个本来良好的预测中,一些未正确预测的值可能会增加 RMSE。此外,由于使用平方项,较小的误差项在 RMSE 中的权重小于在 WAPE 中的权重。
精度指标允许对预测进行定量评测。特别是对于大规模比较(总体而言,方法 A 比方法 B 好),这些至关重要。但是,用单个 SKU 的视觉效果来补充这一点通常很重要。
