本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
監控 Amazon Aurora 全域資料庫
當您建立組成 Aurora 全域資料庫的 Aurora 資料庫叢集時,您可以選擇許多選項,讓您監控資料庫叢集的效能。這些選項包括下列項目:
Amazon RDS Performance Insights – 在基礎 Aurora 資料庫引擎中啟用效能結構描述。若要深入了解績效詳情與 Aurora 全域資料庫,請參閱使用 Amazon RDS Performance Insights 監控 Amazon Aurora 全域資料庫。
增強型監控 – 在 上產生程序或執行緒使用率的指標CPU。若要瞭解增強型監控,請參閱 使用增強型監控來監控作業系統指標。
Amazon CloudWatch Logs – 將指定的日誌類型發佈至 CloudWatch Logs。預設會發佈錯誤日誌,但您可以選擇 Aurora 資料庫引擎特定的其他日誌。
對於SQL以 Aurora My 為基礎的 Aurora 資料庫叢集,您可以匯出稽核日誌、一般日誌和慢查詢日誌。
對於SQL以 Aurora Postgre 為基礎的 Aurora 資料庫叢集,您可以匯出 PostgreSQL 日誌。
對於 Aurora My SQL型全域資料庫,您可以查詢特定
information_schema資料表,以檢查 Aurora 全域資料庫及其執行個體的狀態。如要瞭解如何作業,請參閱監控 Aurora My SQL型全域資料庫。對於SQL以 Aurora Postgre 為基礎的全域資料庫,您可以使用特定函數來檢查 Aurora 全域資料庫及其執行個體的狀態。若要瞭解如何操作,請參閱監控 Aurora Postgre SQL型全域資料庫。
下面的螢幕擷取畫面顯示了一些在 Aurora 全域資料庫中的主要 Aurora 資料庫叢集的 Monitoring (監控) 索引標籤上可用的選項。
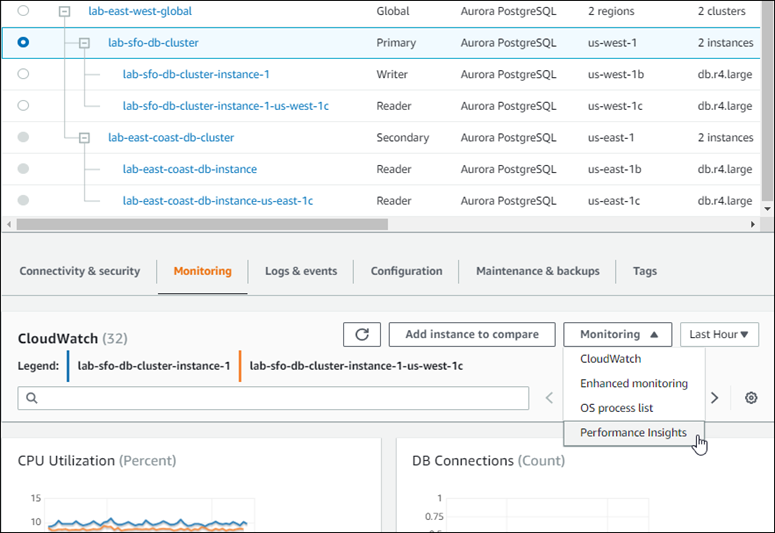
如需詳細資訊,請參閱在 Amazon Aurora 叢集中監控指標。
使用 Amazon RDS Performance Insights 監控 Amazon Aurora 全域資料庫
您可以將 Amazon RDS Performance Insights 用於 Aurora 全域資料庫。您可以為 Aurora 全域資料庫中的每個 Aurora 資料庫叢集個別啟用此功能。若要執行這項操作,您可以在 Create database (建立資料庫) 頁面的 Additional configuration (其他組態) 區段中選擇 Enable Performance Insights (啟用績效詳情)。或者,您可以修改您的 Aurora 資料庫叢集,以在其啟動並執行之後使用這項功能。對於每個屬於 Aurora 全域資料庫的叢集,您都可以啟用或關閉績效詳情。
績效詳情所建立的報告適用於全域資料庫中的每個叢集。當您將新的次要 AWS 區域 新增至已使用績效詳情的 Aurora 全域資料庫時,請務必在新增的叢集中啟用績效詳情。這並不會從現有的全球資料庫中繼承績效詳情的設定。
您可以在檢視連接到全域資料庫之資料庫執行個體的效能詳情頁面 AWS 區域 時切換。不過,在切換之後,您可能不會立即看到效能資訊 AWS 區域。雖然每個資料庫執行個體的名稱可能相同 AWS 區域,但每個資料庫執行個體相關聯的績效詳情URL都不同。切換後 AWS 區域,請在績效詳情導覽窗格中再次選擇資料庫執行個體的名稱。
針對資料庫執行個體連結與全域資料庫的關聯,在每個 AWS 區域影響效能的因素可能不同。例如,每個 中的資料庫執行個體 AWS 區域 可能具有不同的容量。
若要深入了解如何使用 Performance Insights (績效詳情),請參閱在 Amazon Aurora 上使用績效詳情監控資料庫負載。
使用資料庫活動串流來監控 Aurora 全域資料庫
透過使用資料庫活動串流功能,您可以在全域資料庫的資料庫叢集中監控和設定稽核活動的警示。您會在每個資料庫叢集上分別啟動資料庫活動串流。每個叢集在其自己的 AWS 區域中將稽核資料傳送至其自己的 Kinesis 串流。如需詳細資訊,請參閱使用資料庫活動串流來監控 Amazon Aurora。
監控 Aurora My SQL型全域資料庫
若要檢視 Aurora My SQL型全域資料庫的狀態,請查詢 information_schema.aurora_global_db_status和 information_schema.aurora_global_db_instance_status資料表。
注意
information_schema.aurora_global_db_status 和 information_schema.aurora_global_db_instance_status資料表僅適用於 Aurora MySQL 3.04.0 版及更新的全域資料庫。
監控 Aurora My SQL型全域資料庫
-
使用 MySQL 用戶端連線至全域資料庫主要叢集端點。如需如何連線的詳細資訊,請參閱 連線至 Amazon Aurora Global Database。
-
在 mysql 命令中查詢
information_schema.aurora_global_db_status資料表,以列出主要和次要磁碟區。此查詢會傳回全球資料庫次要資料庫叢集的延遲時間,如下列範例所示。mysql> select * from information_schema.aurora_global_db_status;AWS_REGION | HIGHEST_LSN_WRITTEN | DURABILITY_LAG_IN_MILLISECONDS | RPO_LAG_IN_MILLISECONDS | LAST_LAG_CALCULATION_TIMESTAMP | OLDEST_READ_VIEW_TRX_ID -----------+---------------------+--------------------------------+------------------------+---------------------------------+------------------------ us-east-1 | 183537946 | 0 | 0 | 1970-01-01 00:00:00.000000 | 0 us-west-2 | 183537944 | 428 | 0 | 2023-02-18 01:26:41.925000 | 20806982 (2 rows)輸出包含全球資料庫中每個資料庫叢集的資料列,其中包括以下欄位:
-
AWS_REGION – AWS 區域 此資料庫叢集所在的 。如需 AWS 區域 依引擎列出的資料表,請參閱 區域可用性。
-
HIGHEST_LSN_WRITTEN – 目前寫入此資料庫叢集的最高日誌序號 (LSN)。
日誌序號 (LSN) 是唯一序號,可識別資料庫交易日誌中的記錄。 LSNs 會依順序排列,讓較大的 LSN代表較晚的交易。
-
DURABILITY_LAG_IN_MILLISECONDS – 次要資料庫叢集
HIGHEST_LSN_WRITTEN上的 與主要資料庫叢集HIGHEST_LSN_WRITTEN上的 之間的時間戳記值差異。在 Aurora 全球資料庫的主要資料庫叢集上,此值始終為 0。 -
RPO_LAG_IN_MILLISECONDS – 復原點目標 (RPO) 延遲。RPO 延遲是最近使用者交易COMMIT在存放在 Aurora 全域資料庫的主要資料庫叢集之後,存放在次要資料庫叢集上所需的時間。在 Aurora 全球資料庫的主要資料庫叢集上,此值始終為 0。
簡而言之,此指標會計算 Aurora 全域資料庫中每個 Aurora MySQL 資料庫叢集的復原點目標,也就是說,如果發生中斷,可能會遺失多少資料。與延遲一樣, RPO是以時間為單位進行測量。
-
LAST_LAG_CALCULATION_TIMESTAMP – 指定上次計算
DURABILITY_LAG_IN_MILLISECONDS和 值的時間戳RPO_LAG_IN_MILLISECONDS。例如1970-01-01 00:00:00+00之類的時間值表示此為主要資料庫叢集。 -
OLDEST_READ_VIEW_TRX_ID – 寫入器資料庫執行個體可以清除的最舊交易 ID。
-
-
查詢
information_schema.aurora_global_db_instance_status資料表列出主要資料庫叢集與次要資料庫叢集的所有次要資料庫執行個體。mysql> select * from information_schema.aurora_global_db_instance_status;SERVER_ID | SESSION_ID | AWS_REGION | DURABLE_LSN | HIGHEST_LSN_RECEIVED | OLDEST_READ_VIEW_TRX_ID | OLDEST_READ_VIEW_LSN | VISIBILITY_LAG_IN_MSEC ---------------------+--------------------------------------+------------+-------------+----------------------+-------------------------+----------------------+------------------------ ams-gdb-primary-i2 | MASTER_SESSION_ID | us-east-1 | 183537698 | 0 | 0 | 0 | 0 ams-gdb-secondary-i1 | cc43165b-bdc6-4651-abbf-4f74f08bf931 | us-west-2 | 183537689 | 183537692 | 20806928 | 183537682 | 0 ams-gdb-secondary-i2 | 53303ff0-70b5-411f-bc86-28d7a53f8c19 | us-west-2 | 183537689 | 183537692 | 20806928 | 183537682 | 677 ams-gdb-primary-i1 | 5af1e20f-43db-421f-9f0d-2b92774c7d02 | us-east-1 | 183537697 | 183537698 | 20806930 | 183537691 | 21 (4 rows)輸出包含全球資料庫中每個資料庫執行個體的資料列,其中包括以下欄位:
-
SERVER_ID – 資料庫執行個體的伺服器識別符。
-
SESSION_ID – 目前工作階段的唯一識別符。
MASTER_SESSION_ID值可識別寫入器 (主) 資料庫執行個體。 -
AWS_REGION – AWS 區域 此資料庫執行個體所在的 。如需 AWS 區域 依引擎列出的資料表,請參閱 區域可用性。
-
DURABLE_LSN – 在儲存中LSN變得耐用。
-
HIGHEST_LSN_RECEIVED – 資料庫執行個體從寫入器資料庫執行個體LSN接收到的最高值。
-
OLDEST_READ_VIEW_TRX_ID – 寫入器資料庫執行個體可以清除的最舊交易 ID。
-
OLDEST_READ_VIEW_LSN – 資料庫執行個體LSN用來從儲存體讀取的最舊版本。
-
VISIBILITY_LAG_IN_MSEC – 對於主要資料庫叢集中的讀取器,此資料庫執行個體在幾毫秒內落後於寫入器資料庫執行個體。對於次要資料庫叢集中的讀取器,此資料庫執行個體延遲於次要磁碟區的時間 (以毫秒為單位)。
-
若要查看這些值如何隨時間改變,則可考慮使用以下需要一小時才能插入資料表的交易區塊:
mysql> BEGIN;
mysql> INSERT INTO table1 SELECT Large_Data_That_Takes_1_Hr_To_Insert;
mysql> COMMIT;
在某些情況下,BEGIN 陳述式後,主要資料庫叢集和次要資料庫叢集之間網路可能會斷線。如果是,次要資料庫叢集的 DURABILITY_LAG_IN_MILLISECONDS 值會開始增加。在INSERT陳述式結尾,DURABILITY_LAG_IN_MILLISECONDS 值為 1 小時。不過,RPO_LAG_IN_MILLISECONDS 值為 0,因為在主要資料庫叢集與次要資料庫叢集之間遞交的所有使用者資料仍然相同。一旦COMMIT陳述式完成,RPO_LAG_IN_MILLISECONDS 值就會增加。
監控 Aurora Postgre SQL型全域資料庫
若要檢視 Aurora Postgre SQL型全域資料庫的狀態,請使用 aurora_global_db_status和 aurora_global_db_instance_status函數。
注意
只有 Aurora PostgreSQL 支援 aurora_global_db_status和 aurora_global_db_instance_status函數。
監控以 Aurora Postgre SQL為基礎的全域資料庫
-
使用 PostgreSQL 公用程式連線至全域資料庫主要叢集端點,例如 psql。如需如何連線的詳細資訊,請參閱 連線至 Amazon Aurora Global Database。
-
在 psql 命令中使用
aurora_global_db_status函數,以列出主要和次要磁碟區。如此即會顯示全球資料庫次要資料庫叢集的延遲時間。postgres=> select * from aurora_global_db_status();aws_region | highest_lsn_written | durability_lag_in_msec | rpo_lag_in_msec | last_lag_calculation_time | feedback_epoch | feedback_xmin ------------+---------------------+------------------------+-----------------+----------------------------+----------------+--------------- us-east-1 | 93763984222 | -1 | -1 | 1970-01-01 00:00:00+00 | 0 | 0 us-west-2 | 93763984222 | 900 | 1090 | 2020-05-12 22:49:14.328+00 | 2 | 3315479243 (2 rows)輸出包含全球資料庫中每個資料庫叢集的資料列,其中包括以下欄位:
-
aws_region – AWS 區域 此資料庫叢集所在的 。如需 AWS 區域 依引擎列出的資料表,請參閱 區域可用性。
-
highest_lsn_written – 目前寫入此資料庫叢集的最高日誌序號 (LSN)。
日誌序號 (LSN) 是唯一序號,可識別資料庫交易日誌中的記錄。 LSNs 會依順序排列,讓較大的 LSN代表較晚的交易。
-
durability_lag_in_msec – 寫入次要資料庫叢集之最大記錄序號 (
highest_lsn_written) 與寫入主要資料庫叢集之highest_lsn_written的時間戳記差異。 -
rpo_lag_in_msec – 復原點目標 (RPO) 延遲。此延遲是指存放在次要資料庫叢集之最近使用者交易遞交,以及存放在主要資料庫叢集之最近使用者交易遞交間的時間差異。
-
last_lag_calculation_time – 上次計算
durability_lag_in_msec和rpo_lag_in_msec值時的時間戳記。 -
feedback_epoch – 次要資料庫叢集產生熱待命資訊時所使用的 epoch。
Hot standby (熱待命) 指的是在伺服器處於復原或待命模式時,資料庫叢集仍可執行連線與查詢操作。熱待命回饋則會提供資料庫叢集在熱待命期間的相關資訊。如需詳細資訊,請參閱 PostgreSQL 文件中的熱待命
。 -
feedback_xmin – 次要資料庫叢集所使用的最小 (最舊) 作用中交易 ID。
-
-
使用
aurora_global_db_instance_status函數列出主要資料庫叢集與次要資料庫叢集的所有次要資料庫執行個體。postgres=> select * from aurora_global_db_instance_status();server_id | session_id | aws_region | durable_lsn | highest_lsn_rcvd | feedback_epoch | feedback_xmin | oldest_read_view_lsn | visibility_lag_in_msec --------------------------------------------+--------------------------------------+------------+-------------+------------------+----------------+---------------+----------------------+------------------------ apg-global-db-rpo-mammothrw-elephantro-1-n1 | MASTER_SESSION_ID | us-east-1 | 93763985102 | | | | | apg-global-db-rpo-mammothrw-elephantro-1-n2 | f38430cf-6576-479a-b296-dc06b1b1964a | us-east-1 | 93763985099 | 93763985102 | 2 | 3315479243 | 93763985095 | 10 apg-global-db-rpo-elephantro-mammothrw-n1 | 0d9f1d98-04ad-4aa4-8fdd-e08674cbbbfe | us-west-2 | 93763985095 | 93763985099 | 2 | 3315479243 | 93763985089 | 1017 (3 rows)輸出包含全球資料庫中每個資料庫執行個體的資料列,其中包括以下欄位:
-
server_id – 此資料庫執行個體的伺服器識別符。
-
session_id – 目前工作階段的唯一識別符。
-
aws_region – AWS 區域 此資料庫執行個體所在的 。如需 AWS 區域 依引擎列出的資料表,請參閱 區域可用性。
-
durable_lsn - 儲存體中的耐用性LSN。
-
highest_lsn_rcvd – 資料庫執行個體從寫入器資料庫執行個體LSN接收的最高值。
-
feedback_epoch – 資料庫執行個體產生熱待命資訊時所使用的 epoch。
熱待命指的是在伺服器處於復原或待命模式時,資料庫執行個體仍可執行連線與查詢操作。熱待命回饋則會提供資料庫執行個體在熱待命期間的相關資訊。如需詳細資訊,請參閱熱待命
上的 PostgreSQL 文件。 -
feedback_xmin – 資料庫執行個體所使用的最小 (最舊) 作用中交易 ID。
-
oldest_read_view_lsn – 資料庫執行個體LSN用來從儲存體讀取的最舊版本。
-
visibility_lag_in_msec – 此資料庫執行個體落後寫入器資料庫執行個體的程度。
-
若要查看這些值如何隨時間改變,則可考慮使用以下需要一小時才能插入資料表的交易區塊:
psql> BEGIN;
psql> INSERT INTO table1 SELECT Large_Data_That_Takes_1_Hr_To_Insert;
psql> COMMIT;在某些情況下,BEGIN 陳述式後,主要資料庫叢集和次要資料庫叢集之間網路可能會斷線。如果是這樣,次要資料庫叢集的 durability_lag_in_msec 值會開始增加。在 INSERT 陳述式的結尾,durability_lag_in_msec 值為 1 小時。但 rpo_lag_in_msec 值會是 0,這是因為主要資料庫叢集與次要資料庫叢集之間遞交的所有使用者資料仍是一樣的。一旦 COMMIT 陳述式完成,rpo_lag_in_msec 值就會增加。
