Retrieving XPaths (XML Path
Language) for Web Crawler
If the website you are crawling with Amazon Q Business Web Crawler uses Form or
SAML authentication, you need to provide Amazon Q with the absolute XPaths
for the username and password fields on your web page. Optionally, you may also need to
provide the absolute XPaths to the username and password buttons.
XPaths are expressions used to uniquely identify and locate the content of any XML
like language document (including HTML). Amazon Q uses the XPaths you provide
to confirm access to the website you want to crawl. XPaths usually follow the following
format: //tagname[@Attribute='Value'].
The following tabs provide a procedure for retrieving XPaths required for your Amazon Q Web Crawler connector using different web browsers.
- Chrome
-
To retrieve XPaths for an Amazon Q Web
Crawler
-
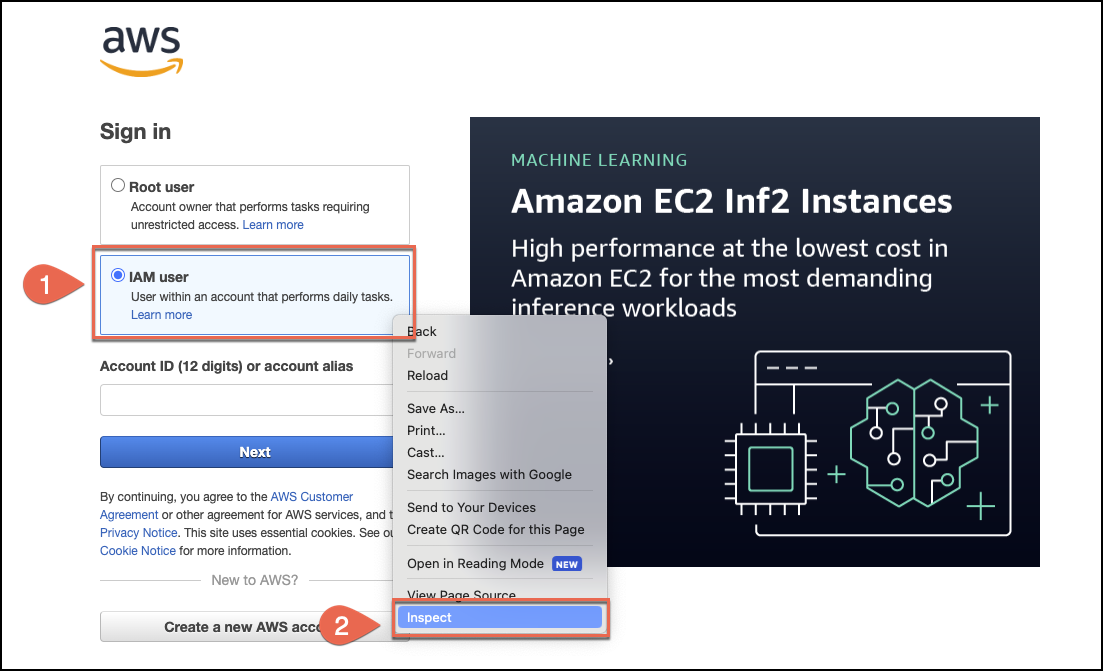
Make sure you're on the web page you want to crawl. Then, either
select or click on the web page element you want to retrieve the
XPath for. This could be the username or password fields, or the
username and password buttons.
-
Then, open the context (right-click) menu and then choose the
Inspect option.
In the Developer Tools window that opens, the
details for the element you've chosen will be highlighted.
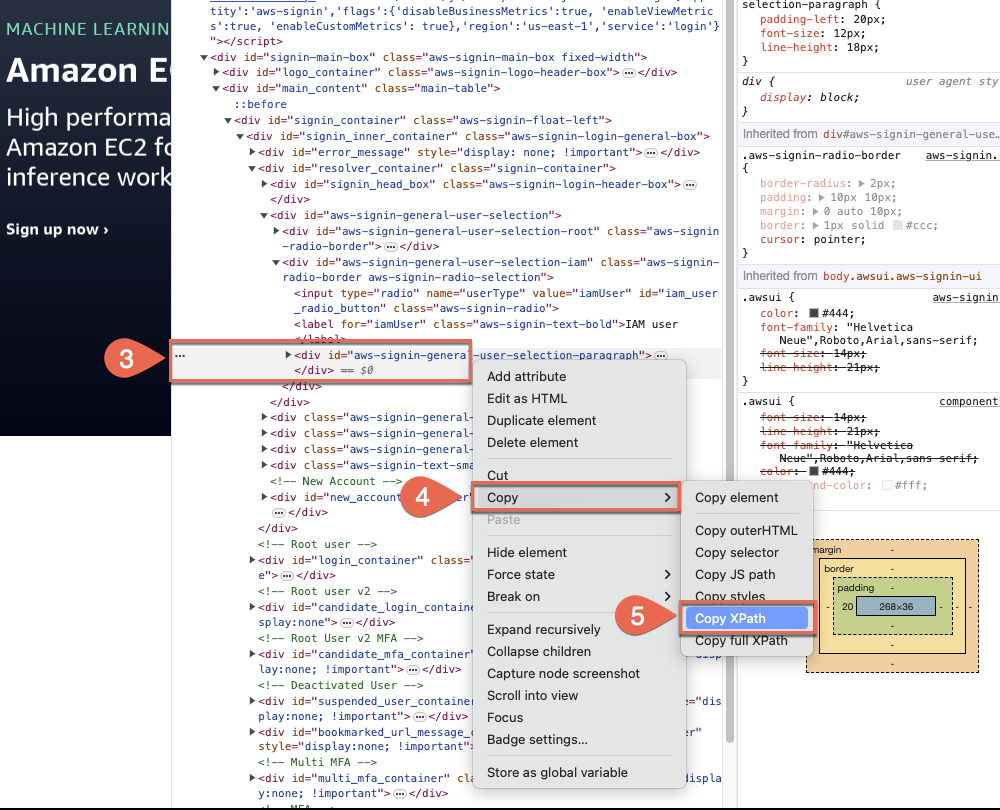
-
Right click on the highlighted element to open the context
(right-click) menu.
-
Choose Copy.
-
Then, choose Copy XPath.
-
Then, open a text editor of your choice and paste the XPath you
copied. The format of the XPath will look like this:
//tagname[@Attribute='Value'].
Input the relevant XPaths you've copied in the
Authentication section when you configure
Amazon Q Web Crawler connector.
- Firefox
-
To retrieve XPaths for an Amazon Q Web
Crawler
-
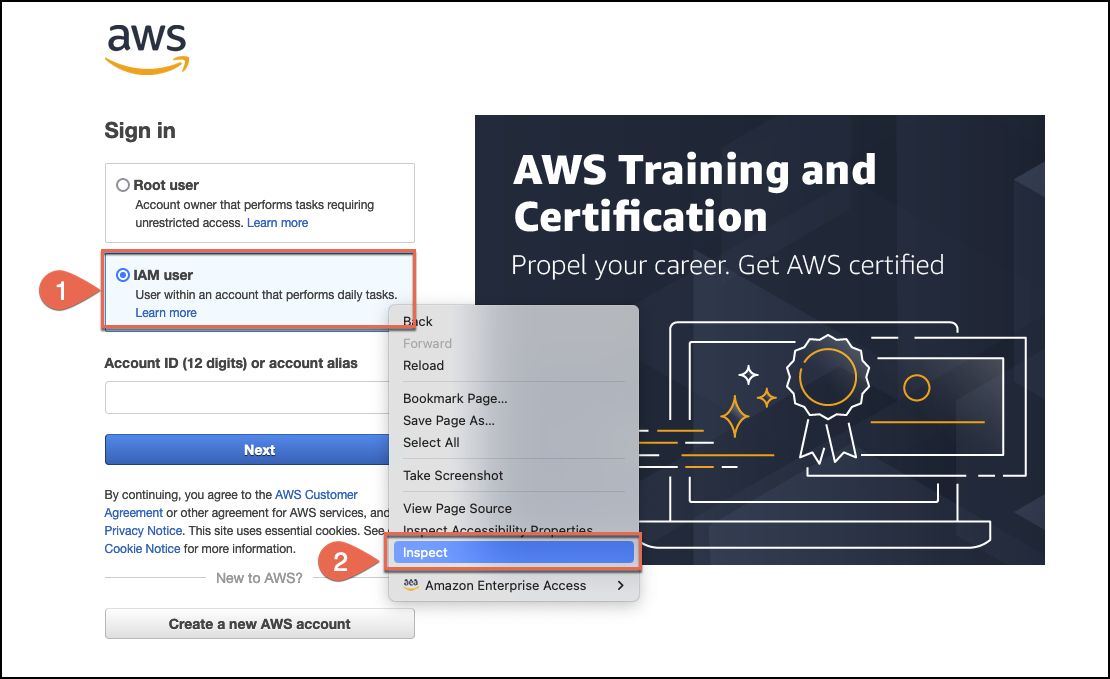
Make sure you're on the web page you want to crawl. Then, either
select or click on the web page element you want to retrieve the
XPath for. This could be the username or password fields, or the
username and password buttons.
-
Then, open the context (right-click) menu and then choose the
Inspect option.
In the Developer Tools window that opens, the
details for the element you've chosen will be highlighted.
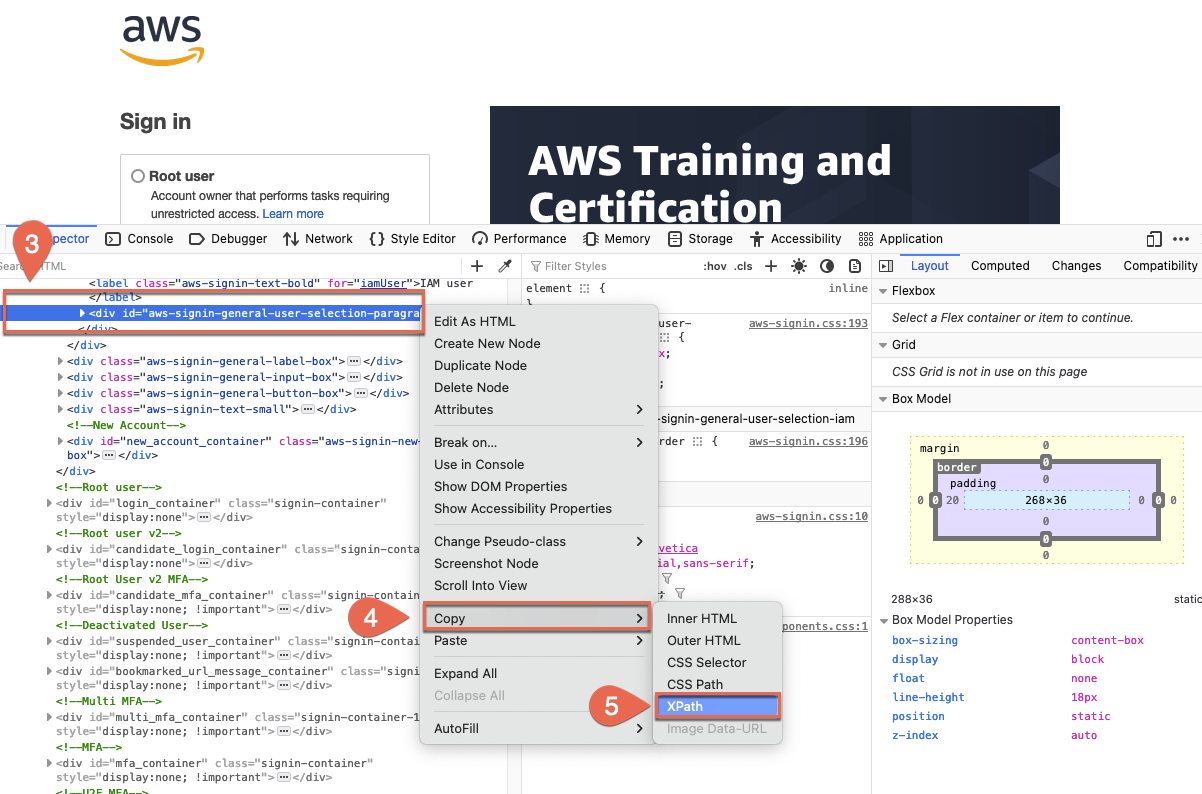
-
Right click on the highlighted element to open the context
(right-click) menu.
-
Choose Copy.
-
Then, choose Copy XPath.
-
Then, open a text editor of your choice and paste the XPath you
copied. The format of the XPath will look like this:
//tagname[@Attribute='Value'].
Input the relevant XPaths you've copied in the
Authentication section when you configure
Amazon Q Web Crawler connector.