本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
自訂分類器指標
Amazon Comprehend 提供指標,協助您預估自訂分類器的效能。Amazon Comprehend 會使用分類器訓練任務的測試資料來計算指標。這些指標準確地代表模型在訓練期間的效能,因此它們近似模型效能,以便分類類似的資料。
使用 DescribeDocumentClassifier 等 API 操作來擷取自訂分類器的指標。
注意
請參閱指標:精確度、召回和 FScore
指標
Amazon Comprehend 支援下列指標:
若要檢視分類器的指標,請在 主控台中開啟分類器詳細資訊頁面。
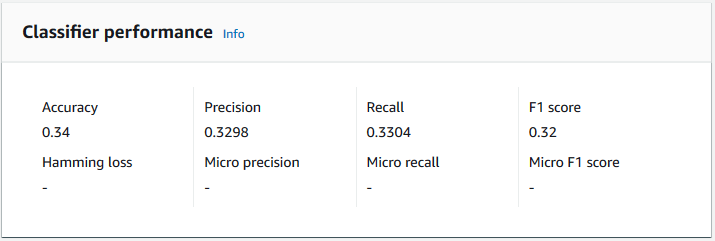
準確性
準確度表示模型準確預測之測試資料中的標籤百分比。若要計算準確性,請將測試文件中準確預測的標籤數量除以測試文件中的標籤總數。
例如
| 實際標籤 | 預測標籤 | 準確/不正確 |
|---|---|---|
|
1 |
1 |
準確 |
|
0 |
1 |
不正確 |
|
2 |
3 |
不正確 |
|
3 |
3 |
準確 |
|
2 |
2 |
準確 |
|
1 |
1 |
準確 |
|
3 |
3 |
準確 |
準確度包含準確預測的數量除以整體測試樣本的數量 = 5/7 = 0.714 或 71.4%
精確度 (巨集精確度)
精確度是衡量分類器結果在測試資料中的實用性。其定義為準確分類的文件數量,除以類別的分類總數。高精確度表示分類器傳回比不相關結果更相關的結果。
Precision 指標也稱為巨集精確度。
下列範例顯示測試集的精確度結果。
| 標籤 | 範例大小 | 標籤精確度 |
|---|---|---|
|
Label_1 |
400 |
0.75 |
|
Label_2 |
300 |
0.80 |
|
Label_3 |
30000 |
0.90 版 |
|
Label_4 |
20 |
0.50 |
|
Label_5 |
10 |
0.40 |
因此,模型的精確度 (巨集精確度) 指標為:
Macro Precision = (0.75 + 0.80 + 0.90 + 0.50 + 0.40)/5 = 0.67召回 (巨集召回)
這表示模型可以預測的文字中正確類別的百分比。此指標來自平均所有可用標籤的取回分數。Recall 是測試資料分類器結果完成度的指標。
高度召回表示分類器傳回大部分的相關結果。
Recall 指標也稱為巨集召回。
下列範例顯示測試集的召回結果。
| 標籤 | 範例大小 | 標籤回收 |
|---|---|---|
|
Label_1 |
400 |
0.70 |
|
Label_2 |
300 |
0.70 |
|
Label_3 |
30000 |
0.98 |
|
Label_4 |
20 |
0.80 |
|
Label_5 |
10 |
0.10 |
因此,模型的召回 (巨集召回) 指標為:
Macro Recall = (0.70 + 0.70 + 0.98 + 0.80 + 0.10)/5 = 0.656F1 分數 (巨集 F1 分數)
F1 分數衍生自 Precision和 Recall值。它測量分類器的整體準確性。最高分數為 1,最低分數為 0。
Amazon Comprehend 會計算巨集 F1 分數。這是標籤 F1 分數的未加權平均值。使用下列測試集做為範例:
| 標籤 | 範例大小 | 標籤 F1 分數 |
|---|---|---|
|
Label_1 |
400 |
0.724 |
|
Label_2 |
300 |
0.824 |
|
Label_3 |
30000 |
0.94 |
|
Label_4 |
20 |
0.62 |
|
Label_5 |
10 |
0.16 |
模型的 F1 分數 (巨集 F1 分數) 計算方式如下:
Macro F1 Score = (0.724 + 0.824 + 0.94 + 0.62 + 0.16)/5 = 0.6536壅塞損失
不正確預測的標籤部分。與標籤總數相比,也被視為不正確標籤的一小部分。接近零的分數更好。
微型精確度
原始:
與精確度指標類似,但微精確度是根據加在一起的所有精確度分數的整體分數。
微型召回
與回收指標類似,但微回收是根據加在一起的所有回收分數的整體分數。
Micro F1 分數
Micro F1 分數是 Micro Precision 和 Micro Recall 指標的組合。
改善自訂分類器的效能
這些指標可讓您深入了解自訂分類器在分類任務期間如何執行。如果指標很低,分類模型可能不適用於您的使用案例。您有多種選項可以改善分類器效能:
-
在您的訓練資料中,提供明確區隔類別的具體範例。例如,提供使用唯一單字/句子來代表類別的文件。
-
在訓練資料中為代表性不足的標籤新增更多資料。
-
嘗試減少類別中的扭曲。如果資料中最大的標籤超過最小標籤中文件的 10 倍,請嘗試增加最小標籤的文件數量。請務必將高度表示和最小表示類別之間的偏斜比率降低到最多 10:1。您也可以嘗試從高度表示的類別中移除輸入文件。
