本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
目標情緒
針對性情緒可讓您精確了解輸入文件中與特定實體 (例如品牌或產品) 相關聯的情緒。
目標情緒和情緒之間的差異是輸出資料中的精細程度。情緒分析會決定每個輸入文件的主要情緒,但不會提供資料以供進一步分析。目標情緒分析會決定每個輸入文件中特定實體的實體層級情緒。您可以分析輸出資料,以判斷獲得正面或負面意見回饋的特定產品和服務。
例如,在一組餐廳評論中,客戶提供以下評論:「墨西哥捲餅很美味,而且員工很友善。」 此檢閱的分析會產生下列結果:
情緒分析會判斷每個餐廳評論的整體情緒是正面、負面、中性還是混合。在此範例中,整體情緒為正面。
目標情緒分析會判斷客戶在評論中提及之餐廳實體和屬性的情緒。在此範例中,客戶對 “tacos” 和 “staff” 做出正面評論。
針對性情緒為每個分析任務提供下列輸出:
文件中所提及實體的身分。
-
提及的每個實體的實體類型分類。
提及的每個實體的情緒和情緒分數。
對應至單一實體的提及群組 (共同參考群組)。
您可以使用 主控台或 API 來執行目標情緒分析。主控台和 API 支援目標情緒的即時分析和非同步分析。
Amazon Comprehend 支援英文文件的有針對性情緒。
如需目標情緒的詳細資訊,包括教學課程,請參閱 AWS 機器學習部落格中的使用 Amazon Comprehend 目標情緒擷取文字中的精細情緒
實體類型
目標情緒識別下列實體類型。如果實體不屬於任何其他類別,則會指派其他實體類型。輸出檔案中提及的每個實體都包含實體類型,例如 "Type": "PERSON"。
| 實體類型 | 定義 |
|---|---|
| 人物 | 範例包括個人、人物群組、綽號、虛構角色和動物名稱。 |
| LOCATION | 地理位置,例如國家、城市、州、地址、地質結構、水體、自然地標和天文位置。 |
| 組織 | 範例包括政府、公司、運動隊伍和宗教。 |
| 設施 | 建築物、機場、高速公路、橋樑和其他永久的人工結構和房地產改善。 |
| 品牌 | 特定商業項目或產品線的組織、群組或生產者。 |
| COMMERCIAL_ITEM | 任何非一般可購買或可購買的項目,包括 車輛,以及只產生一個項目的大型產品。 |
| MOVIE | 電影或電視節目。實體可以是全名、暱稱或字幕。 |
| 音樂 | 完整或部分歌曲。此外,還有個別音樂創作的集合,例如專輯或 Anthology。 |
| 預訂 | 以專業或自我方式發佈的書籍。 |
| 軟體 | 正式發行的軟體產品。 |
| GAME | 遊戲,例如電玩遊戲、棋盤遊戲、常見遊戲或運動。 |
| Personal_TITLE | 官方標題和評價,例如 會長、 PhD或 博士。 |
| EVENT | 範例包括節日、音樂會、選舉、戰爭、會議和促銷活動。 |
| DATE | 日期或時間的任何參考,無論是特定或一般,無論是絕對或相對。 |
| 數量 | 所有測量及其單位 (貨幣、百分比、數字、位元組等)。 |
| ATTRIBUTE | 實體的屬性、特性或特徵,例如產品的「品質」、手機的「價格」或 CPU 的「速度」。 |
| OTHER | 不屬於任何其他類別的實體。 |
共同參考群組
目標情緒會識別每個輸入文件中的共同參考群組。共同參考群組是對應至一個真實世界實體文件中的一組提及。
在下列客戶審核範例中,「spa」是實體,其實體類型為 FACILITY。該實體另外有兩個被提及為代名詞 ("it")。

輸出檔案組織
目標情緒分析任務會建立 JSON 文字輸出檔案。檔案包含每個輸入文件的一個 JSON 物件。每個 JSON 物件都包含下列欄位:
-
實體 – 文件中找到的實體陣列。
-
檔案 – 輸入文件的檔案名稱。
-
行 – 如果輸入檔案是每行一個文件,實體會包含檔案中文件的行號。
注意
如果目標情緒無法識別輸入文字中的任何實體,則會傳回空陣列做為實體結果。
下列範例顯示具有三行輸入之輸入檔案的實體。輸入格式為 ONE_DOC_PER_LINE,因此每行輸入都是文件。
{ "Entities":[
{entityA},
{entityB},
{entityC}
],
"File": "TargetSentimentInputDocs.txt",
"Line": 0
}
{ "Entities": [
{entityD},
{entityE}
],
"File": "TargetSentimentInputDocs.txt",
"Line": 1
}
{ "Entities": [
{entityF},
{entityG}
],
"File": "TargetSentimentInputDocs.txt",
"Line": 2
}實體陣列中的實體包含文件中偵測到的實體提及的邏輯分組 (稱為共同參考群組)。每個實體的整體結構如下:
{"DescriptiveMentionIndex": [0],
"Mentions": [
{mentionD},
{mentionE}
]
} 實體包含下列欄位:
-
提及 – 文件中實體的提及陣列。陣列代表共同參考群組。如需範例,請參閱共同參考群組。提及陣列中提及的順序是文件中其位置 (偏移) 的順序。每個提及都包含該提及的情緒分數和群組分數。群組分數表示這些提及屬於相同實體的可信度層級。
-
DescriptiveMentionIndex – 一或多個索引加入提供實體群組最佳名稱的提及陣列。例如,實體可以有三個提及文字值 "ABC Hotel"、"ABC Hotel" 和 "it"。最佳名稱是「ABC 飯店」,其 DescriptiveMentionIndex 值為 【0,1】。
每個提及項目都包含下列欄位
-
BeginOffset – 偏移至提及開始的文件文字。
-
EndOffset – 被提及結束的文件文字偏移。
GroupScore – 群組中提及的所有實體都與相同實體相關聯的可信度。
文字 – 文件中識別實體的文字。
類型 – 實體的類型。Amazon Comprehend 支援各種實體類型。
分數 – 建立實體相關的模型可信度。值範圍為零到一,其中一個是最高的可信度。
MentionSentiment – 包含提及的情緒和情緒分數。
情緒 – 提及的情緒。值包括:POSITIVE、NEUTRAL、NEGATIVE 和 MIXED。
SentimentScore – 為每個可能的情緒提供模型可信度。值範圍為零到一,其中一個是最高的可信度。
情緒值具有下列意義:
-
正面 – 提及的實體表達正面情緒。
-
負面 – 提及的實體表達負面情緒。
-
混合 – 提及的實體同時表達正面和負面情緒。
-
中性 – 提及的實體不會表達正面或負面情緒。
在下列範例中,實體在輸入文件中只有一個提及,因此 DescriptiveMentionIndex 為零 (在提及陣列中的第一個提及)。已識別的實體是名為「I」的 PERSON。 情緒分數為中性。
{"Entities":[ { "DescriptiveMentionIndex": [0], "Mentions": [ { "BeginOffset": 0, "EndOffset": 1, "Score": 0.999997, "GroupScore": 1, "Text": "I", "Type": "PERSON", "MentionSentiment": { "Sentiment": "NEUTRAL", "SentimentScore": { "Mixed": 0, "Negative": 0, "Neutral": 1, "Positive": 0 } } } ] } ], "File": "Input.txt", "Line": 0 }
使用主控台進行即時分析
您可以使用 Amazon Comprehend 主控台目標情緒來即時執行。使用範例文字或將您自己的文字貼到輸入文字方塊中,然後選擇分析。
在洞見面板中,主控台會顯示目標情緒分析的三個檢視:
-
分析的文字 – 顯示分析的文字並強調每個實體。底線的顏色表示分析指派給實體的情緒值 (正面、中性、負面或混合)。主控台會在已警示文字方塊的右上角顯示顏色映射。如果您將游標暫留在實體上,主控台會顯示快顯面板,其中包含實體的分析值 (實體類型、情緒分數)。
-
結果 – 顯示包含文字中指出的每個實體資料列的資料表。對於每個實體,資料表會顯示實體和實體分數。資料列也包含主要情緒和每個情緒值的分數。如果有多個提及的相同實體,稱為 共同參考群組,則資料表會將這些提及顯示為與主要實體相關聯的可摺疊資料列集。
如果您將滑鼠暫留在結果表中的實體列上,主控台會反白分析文字面板中提到的實體。
-
應用程式整合 – 顯示 API 請求的參數值,以及在 API 回應中傳回的 JSON 物件結構。如需 JSON 物件中欄位的說明,請參閱輸出檔案組織。
主控台即時分析範例
此範例使用下列文字做為輸入,這是主控台提供的預設輸入文字。
Hello Zhang Wei, I am John. Your AnyCompany Financial Services, LLC credit card account 1111-0000-1111-0008 has a minimum payment of $24.53 that is due by July 31st. Based on your autopay settings, we will withdraw your payment on the due date from your bank account number XXXXXX1111 with the routing number XXXXX0000. Customer feedback for Sunshine Spa, 123 Main St, Anywhere. Send comments to Alice at sunspa@mail.com. I enjoyed visiting the spa. It was very comfortable but it was also very expensive. The amenities were ok but the service made the spa a great experience.
分析的文字面板會顯示此範例的下列輸出。將滑鼠暫留在文字上Zhang Wei,以檢視此實體的快顯面板。
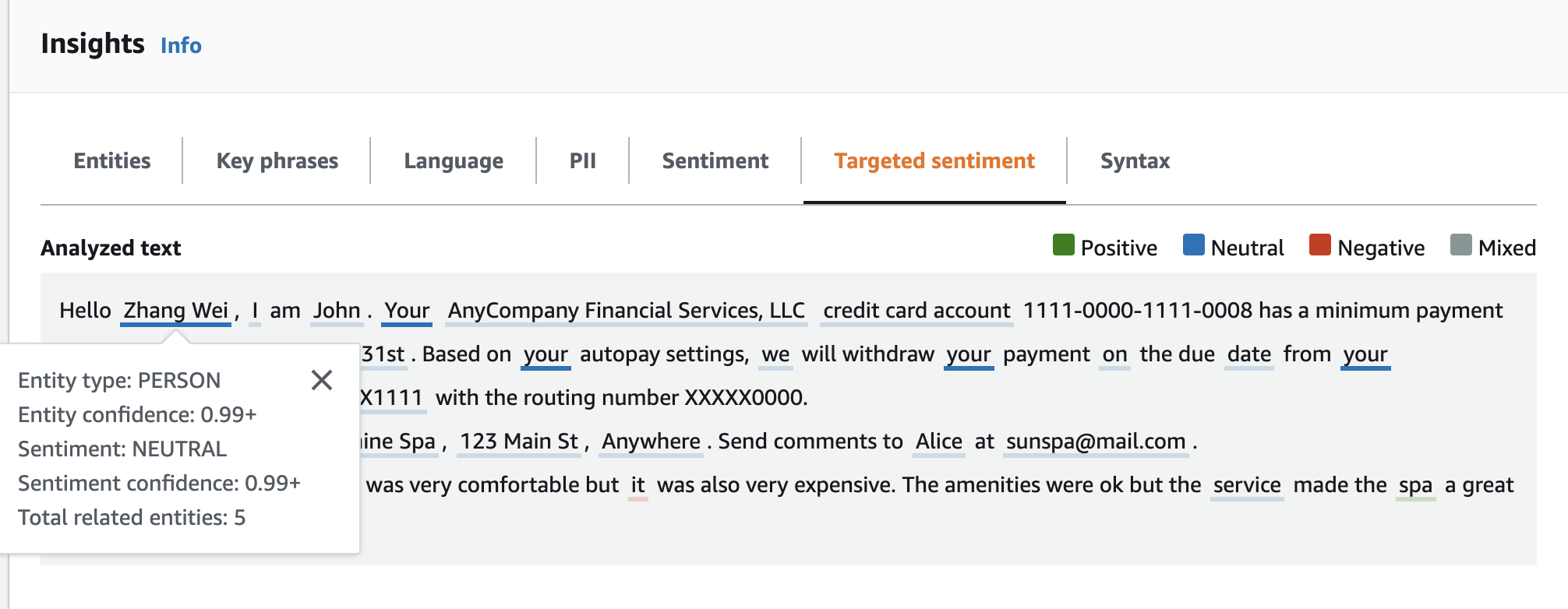
結果資料表提供每個實體的其他詳細資訊,包括實體分數、主要情緒和每個情緒的分數。

在我們的範例中,目標情緒分析會辨識輸入文字中每個提及您的 ,都是個人實體 Zhang Wei 的參考。主控台會將這些提及項目顯示為一組與主要實體相關聯的可摺疊資料列。

應用程式整合面板會顯示 DetectTargetedSentiment API 產生的 JSON 物件。如需完整範例,請參閱下一節。
目標情緒輸出範例
下列範例顯示目標情緒分析任務的輸出檔案。輸入檔案包含三個簡單的文件:
The burger was very flavorful and the burger bun was excellent. However, customer service was slow. My burger was good, and it was warm. The burger had plenty of toppings. The burger was cooked perfectly but it was cold. The service was OK.
此輸入檔案的目標情緒分析會產生下列輸出。
{"Entities":[
{
"DescriptiveMentionIndex": [
0
],
"Mentions": [
{
"BeginOffset": 4,
"EndOffset": 10,
"Score": 0.999991,
"GroupScore": 1,
"Text": "burger",
"Type": "OTHER",
"MentionSentiment": {
"Sentiment": "POSITIVE",
"SentimentScore": {
"Mixed": 0,
"Negative": 0,
"Neutral": 0,
"Positive": 1
}
}
}
]
},
{
"DescriptiveMentionIndex": [
0
],
"Mentions": [
{
"BeginOffset": 38,
"EndOffset": 44,
"Score": 1,
"GroupScore": 1,
"Text": "burger",
"Type": "OTHER",
"MentionSentiment": {
"Sentiment": "NEUTRAL",
"SentimentScore": {
"Mixed": 0.000005,
"Negative": 0.000005,
"Neutral": 0.999591,
"Positive": 0.000398
}
}
}
]
},
{
"DescriptiveMentionIndex": [
0
],
"Mentions": [
{
"BeginOffset": 45,
"EndOffset": 48,
"Score": 0.961575,
"GroupScore": 1,
"Text": "bun",
"Type": "OTHER",
"MentionSentiment": {
"Sentiment": "POSITIVE",
"SentimentScore": {
"Mixed": 0.000327,
"Negative": 0.000286,
"Neutral": 0.050269,
"Positive": 0.949118
}
}
}
]
},
{
"DescriptiveMentionIndex": [
0
],
"Mentions": [
{
"BeginOffset": 73,
"EndOffset": 89,
"Score": 0.999988,
"GroupScore": 1,
"Text": "customer service",
"Type": "ATTRIBUTE",
"MentionSentiment": {
"Sentiment": "NEGATIVE",
"SentimentScore": {
"Mixed": 0.000001,
"Negative": 0.999976,
"Neutral": 0.000017,
"Positive": 0.000006
}
}
}
]
}
],
"File": "TargetSentimentInputDocs.txt",
"Line": 0
}
{
"Entities": [
{
"DescriptiveMentionIndex": [
0
],
"Mentions": [
{
"BeginOffset": 0,
"EndOffset": 2,
"Score": 0.99995,
"GroupScore": 1,
"Text": "My",
"Type": "PERSON",
"MentionSentiment": {
"Sentiment": "NEUTRAL",
"SentimentScore": {
"Mixed": 0,
"Negative": 0,
"Neutral": 1,
"Positive": 0
}
}
}
]
},
{
"DescriptiveMentionIndex": [
0,
2
],
"Mentions": [
{
"BeginOffset": 3,
"EndOffset": 9,
"Score": 0.999999,
"GroupScore": 1,
"Text": "burger",
"Type": "OTHER",
"MentionSentiment": {
"Sentiment": "POSITIVE",
"SentimentScore": {
"Mixed": 0.000002,
"Negative": 0.000001,
"Neutral": 0.000003,
"Positive": 0.999994
}
}
},
{
"BeginOffset": 24,
"EndOffset": 26,
"Score": 0.999756,
"GroupScore": 0.999314,
"Text": "it",
"Type": "OTHER",
"MentionSentiment": {
"Sentiment": "POSITIVE",
"SentimentScore": {
"Mixed": 0,
"Negative": 0.000003,
"Neutral": 0.000006,
"Positive": 0.999991
}
}
},
{
"BeginOffset": 41,
"EndOffset": 47,
"Score": 1,
"GroupScore": 0.531342,
"Text": "burger",
"Type": "OTHER",
"MentionSentiment": {
"Sentiment": "POSITIVE",
"SentimentScore": {
"Mixed": 0.000215,
"Negative": 0.000094,
"Neutral": 0.00008,
"Positive": 0.999611
}
}
}
]
},
{
"DescriptiveMentionIndex": [
0
],
"Mentions": [
{
"BeginOffset": 52,
"EndOffset": 58,
"Score": 0.965462,
"GroupScore": 1,
"Text": "plenty",
"Type": "QUANTITY",
"MentionSentiment": {
"Sentiment": "NEUTRAL",
"SentimentScore": {
"Mixed": 0,
"Negative": 0,
"Neutral": 1,
"Positive": 0
}
}
}
]
},
{
"DescriptiveMentionIndex": [
0
],
"Mentions": [
{
"BeginOffset": 62,
"EndOffset": 70,
"Score": 0.998353,
"GroupScore": 1,
"Text": "toppings",
"Type": "OTHER",
"MentionSentiment": {
"Sentiment": "NEUTRAL",
"SentimentScore": {
"Mixed": 0,
"Negative": 0,
"Neutral": 0.999964,
"Positive": 0.000036
}
}
}
]
}
],
"File": "TargetSentimentInputDocs.txt",
"Line": 1
}
{
"Entities": [
{
"DescriptiveMentionIndex": [
0
],
"Mentions": [
{
"BeginOffset": 4,
"EndOffset": 10,
"Score": 1,
"GroupScore": 1,
"Text": "burger",
"Type": "OTHER",
"MentionSentiment": {
"Sentiment": "POSITIVE",
"SentimentScore": {
"Mixed": 0.001515,
"Negative": 0.000822,
"Neutral": 0.000243,
"Positive": 0.99742
}
}
},
{
"BeginOffset": 36,
"EndOffset": 38,
"Score": 0.999843,
"GroupScore": 0.999661,
"Text": "it",
"Type": "OTHER",
"MentionSentiment": {
"Sentiment": "NEGATIVE",
"SentimentScore": {
"Mixed": 0,
"Negative": 0.999996,
"Neutral": 0.000004,
"Positive": 0
}
}
}
]
},
{
"DescriptiveMentionIndex": [
0
],
"Mentions": [
{
"BeginOffset": 53,
"EndOffset": 60,
"Score": 1,
"GroupScore": 1,
"Text": "service",
"Type": "ATTRIBUTE",
"MentionSentiment": {
"Sentiment": "NEUTRAL",
"SentimentScore": {
"Mixed": 0.000033,
"Negative": 0.000089,
"Neutral": 0.993325,
"Positive": 0.006553
}
}
}
]
}
],
"File": "TargetSentimentInputDocs.txt",
"Line": 2
}
}