本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
成本最佳化 - 網路
架構高可用性 (HA) 系統是實現彈性和容錯能力的最佳實務。實際上,這表示將您的工作負載和基礎基礎設施分散到指定 AWS 區域中的多個可用區域 (AZs)。確保您的 Amazon EKS 環境具備這些特性,可增強系統的整體可靠性。除此之外,EKS 環境也可能由各種建構模組 (即 VPCs)、元件 (即 ELBs) 和整合 (即 ECR 和其他容器登錄檔) 組成。
高可用性系統和其他使用案例特定元件的組合,在資料傳輸和處理方式上扮演重要角色。這將對資料傳輸和處理所產生的成本產生影響。
以下詳述的實務將協助您設計和最佳化 EKS 環境,以達成不同網域和使用案例的成本效益。
Pod 到 Pod 通訊
根據您的設定,Pod 之間的網路通訊和資料傳輸可能會對執行 Amazon EKS 工作負載的整體成本產生重大影響。本節將涵蓋不同的概念和方法,以緩解與 Pod 間通訊相關的成本,同時考慮高可用性 (HA) 架構、應用程式效能和彈性。
將流量限制為可用區域
在 的早期,Kubernetes 專案開始開發拓撲感知建構,包括指派給節點的標籤,例如 kubernetes.io/hostname、topology.kubernetes.io/region 和 topology.kubernetes.io/zone,以啟用功能,例如跨故障網域的工作負載分佈和拓撲感知磁碟區佈建器。在 Kubernetes 1.17 中畢業後,標籤也被利用來啟用 Pod 到 Pod 通訊的拓撲感知路由功能。
以下是一些策略,說明如何控制 EKS 叢集中 Pod 之間的跨可用區流量,以降低成本並盡可能減少延遲。
如果您想要精細了解叢集中 Pod 之間的跨可用區流量 (例如以位元組為單位傳輸的資料量),請參閱此文章
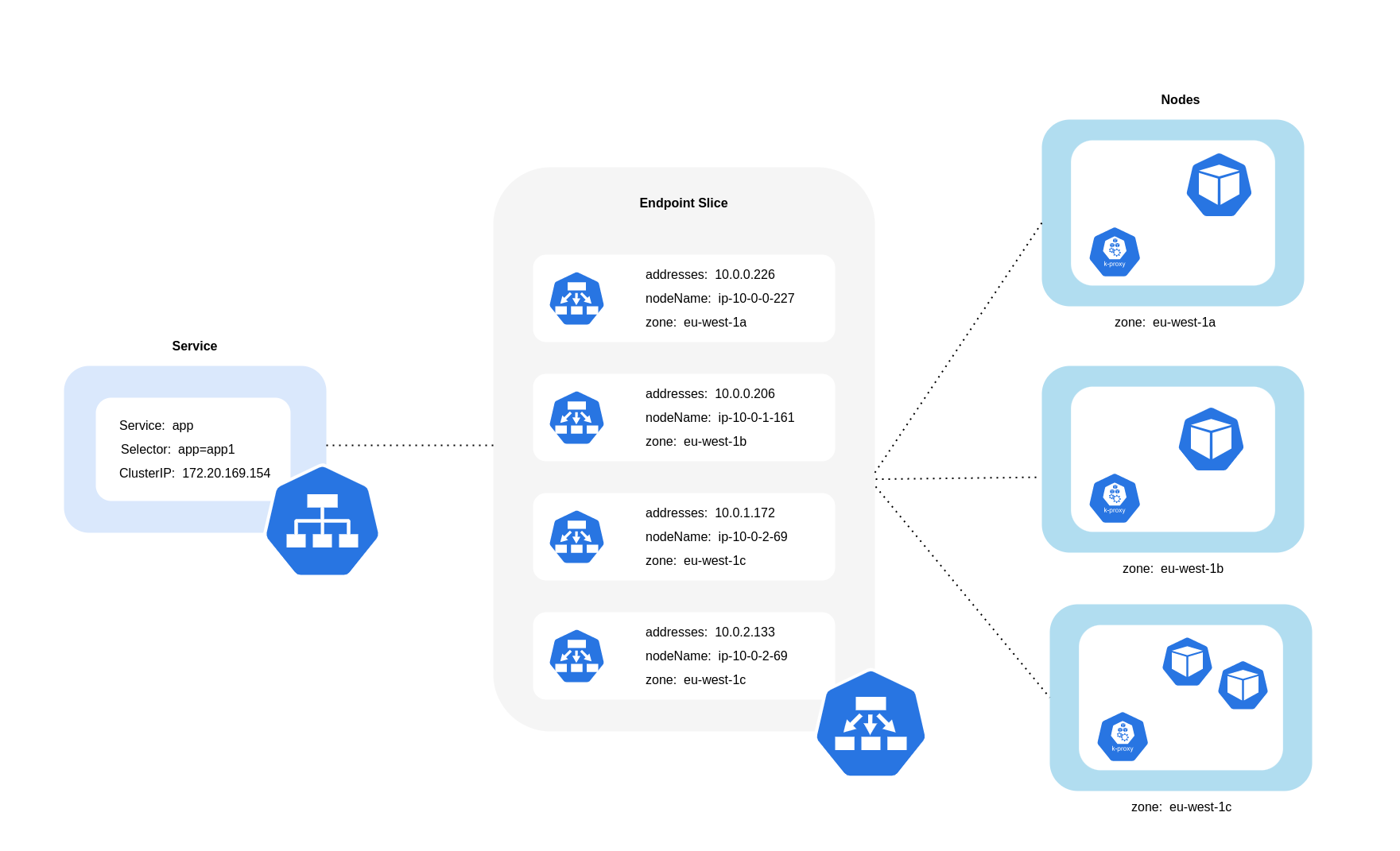
如上圖所示,服務是穩定的網路抽象層,可接收目的地為 Pod 的流量。建立服務時,會建立多個 EndpointSlices。每個 EndpointSlice 都有端點清單,其中包含 Pod 地址的子集,以及其執行所在的節點,以及任何其他拓撲資訊。使用 Amazon VPC CNI 時,每個節點上執行的協助程式集 kube-proxy 會維護網路規則,以啟用 Pod 通訊和服務探索 (替代的 eBPF 型 CNIs 可能不會使用 kube-proxy,但會提供同等行為)。它會履行內部路由的角色,但會根據其從建立的 EndpointSlices 消耗的內容來執行此操作。
在 EKS 上,kube-proxy 主要使用 iptables NAT 規則 (或 IPVS、NFTables
使用拓撲感知路由 (先前稱為拓撲感知提示)
在 Kubernetes 服務上啟用和實作拓撲感知路由kube-proxy會根據套用的提示,將流量從區域路由到端點。
下圖顯示具有提示的 EndpointSlices 如何組織起來,以便根據其區域來源,kube-proxy知道應該前往哪個目的地。如果沒有提示,則沒有此類配置或組織,無論流量來自何處,都會代理到不同的區域目的地。
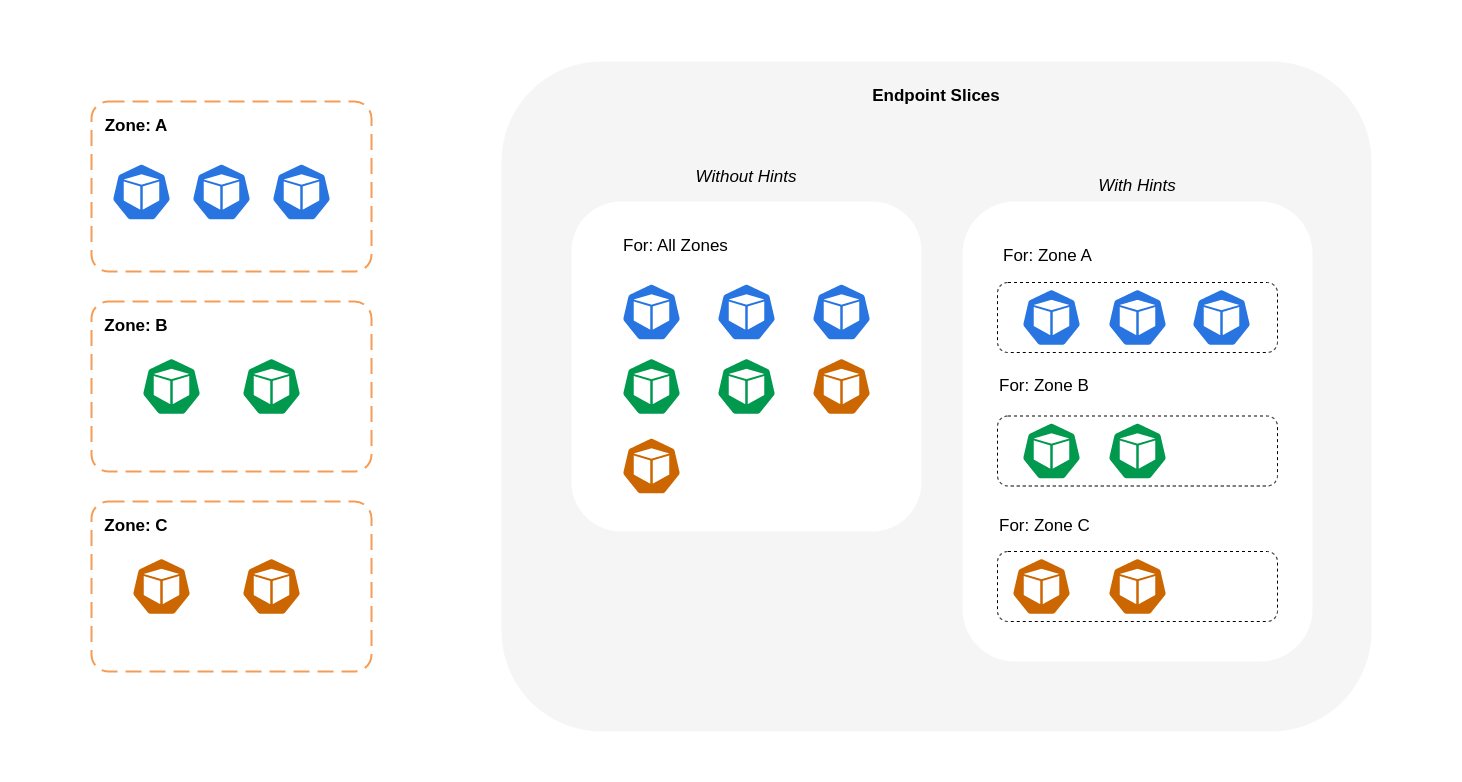
在某些情況下,EndpointSlice 控制器可能會套用不同區域的提示,這表示端點最終可能會為來自不同區域的流量提供服務。這樣做的原因是嘗試和維護不同區域中端點之間的流量均勻分佈。
以下是程式碼片段,說明如何啟用服務的拓撲感知路由。
apiVersion: v1 kind: Service metadata: name: orders-service namespace: ecommerce annotations: service.kubernetes.io/topology-mode: Auto spec: selector: app: orders type: ClusterIP ports: * protocol: TCP port: 3003 targetPort: 3003
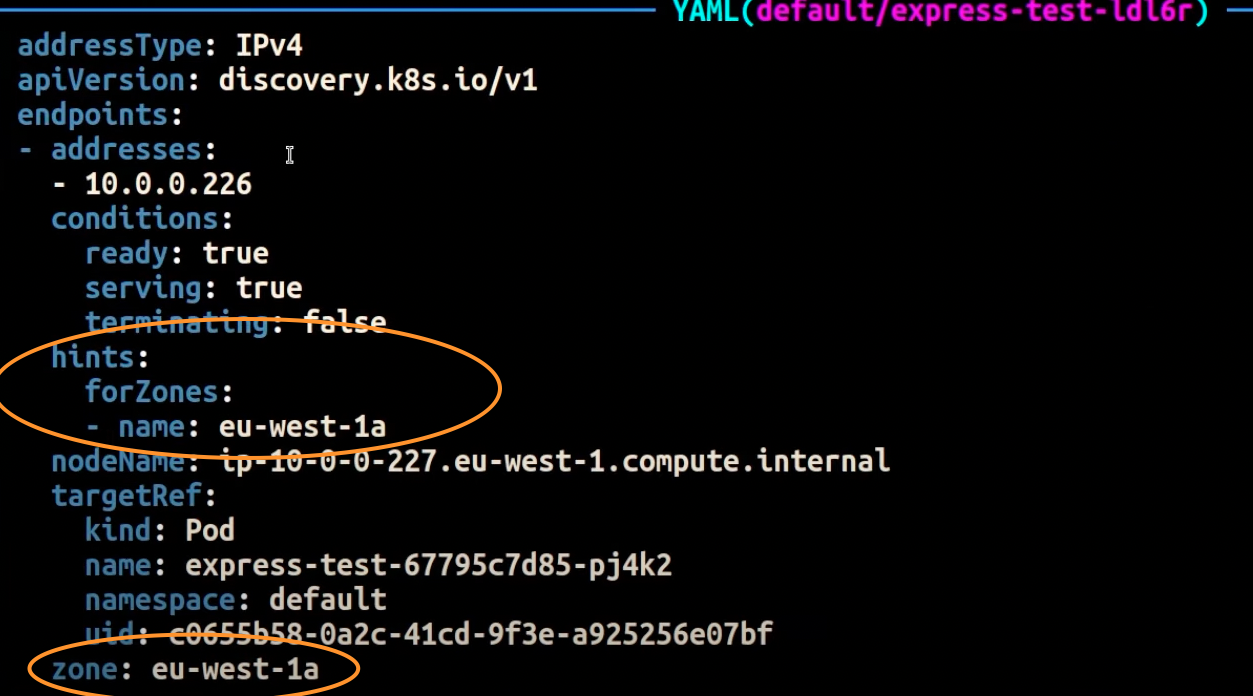
以下螢幕擷取畫面顯示 EndpointSlice 控制器已成功將提示套用至 AZ 中執行之 Pod 複本的端點的結果eu-west-1a。
注意
請務必注意,拓撲感知路由仍在 Beta 版中。此功能在叢集拓撲中平均分佈的工作負載中執行更可預測,因為控制器會按比例分配跨區域的端點,但當區域中的節點資源過於不平衡以避免過載時,可能會略過提示指派。因此,強烈建議將其與排程限制一起使用,以提高應用程式的可用性,例如 Pod 拓撲分散限制
使用流量分佈
流量分佈
以下是如何啟用服務流量分佈的程式碼片段。
apiVersion: v1 kind: Service metadata: name: orders-service namespace: ecommerce spec: trafficDistribution: PreferClose selector: app: orders type: ClusterIP ports: * protocol: TCP port: 3003 targetPort: 3003
啟用流量分佈時,會出現一個常見的挑戰:如果大多數流量來自相同區域,則單一可用區域內的端點可能會過載。此過載可能會造成重大問題:
-
管理多可用區域部署的單一 Horizontal Pod Autoscaler (HPA) 可以透過跨不同AZs擴展 Pod 來回應。不過,此動作無法有效地解決受影響區域中增加的負載。
-
在這種情況下,可能會導致資源效率低下。當類似 Karpenter 的叢集自動擴展器偵測到不同 AZs 的 Pod 橫向擴展時,可能會在不受影響的 AZs 中佈建其他節點,導致不必要的資源配置。
若要克服此挑戰:
-
為每個區域建立單獨的部署,這些部署會有自己的 HPAs 來獨立擴展。
-
利用拓撲分散限制來確保跨叢集的工作負載分佈,這有助於防止高流量區域中的端點過載。
使用自動擴展器:將節點佈建至特定 AZ
我們強烈建議您在跨多個 AZs 的高可用性環境中執行工作負載。這可改善應用程式的可靠性,尤其是在 AZ 發生問題時。如果您願意為了降低網路相關成本而犧牲可靠性,您可以將節點限制為單一可用區域。
若要在相同 AZ 中執行所有 Pod,請在相同 AZ 中佈建工作者節點,或在相同 AZ 上執行的工作者節點上排程 Pod。若要在單一 AZ 中佈建節點,請使用 Cluster Autoscaler (CA)topology.kubernetes.io/zone並指定您要建立工作者節點的 AZ。例如,以下 Karpenter 佈建器程式碼片段會佈建 us-west-2a AZ 中的節點。
Karpenter
apiVersion: karpenter.sh/v1 kind: Provisioner metadata: name: single-az spec: requirements: * key: "topology.kubernetes.io/zone"` operator: In values: ["us-west-2a"]
Cluster Autoscaler (CA)
apiVersion: eksctl.io/v1alpha5 kind: ClusterConfig metadata: name: my-ca-cluster region: us-east-1 version: "1.21" availabilityZones: * us-east-1a managedNodeGroups: * name: managed-nodes labels: role: managed-nodes instanceType: t3.medium minSize: 1 maxSize: 10 desiredCapacity: 1 ...
使用 Pod 指派和節點親和性
或者,如果您的工作者節點在多個 AZs 中執行,則每個節點都會有標籤 topology.kubernetes.io/zonenodeSelector或 nodeAffinity 將 Pod 排程到單一 AZ 中的節點。例如,下列資訊清單檔案會在 AZ us-west-2a 中執行的節點內排程 Pod。
apiVersion: v1 kind: Pod metadata: name: nginx labels: env: test spec: nodeSelector: topology.kubernetes.io/zone: us-west-2a containers: * name: nginx image: nginx imagePullPolicy: IfNotPresent
限制節點的流量
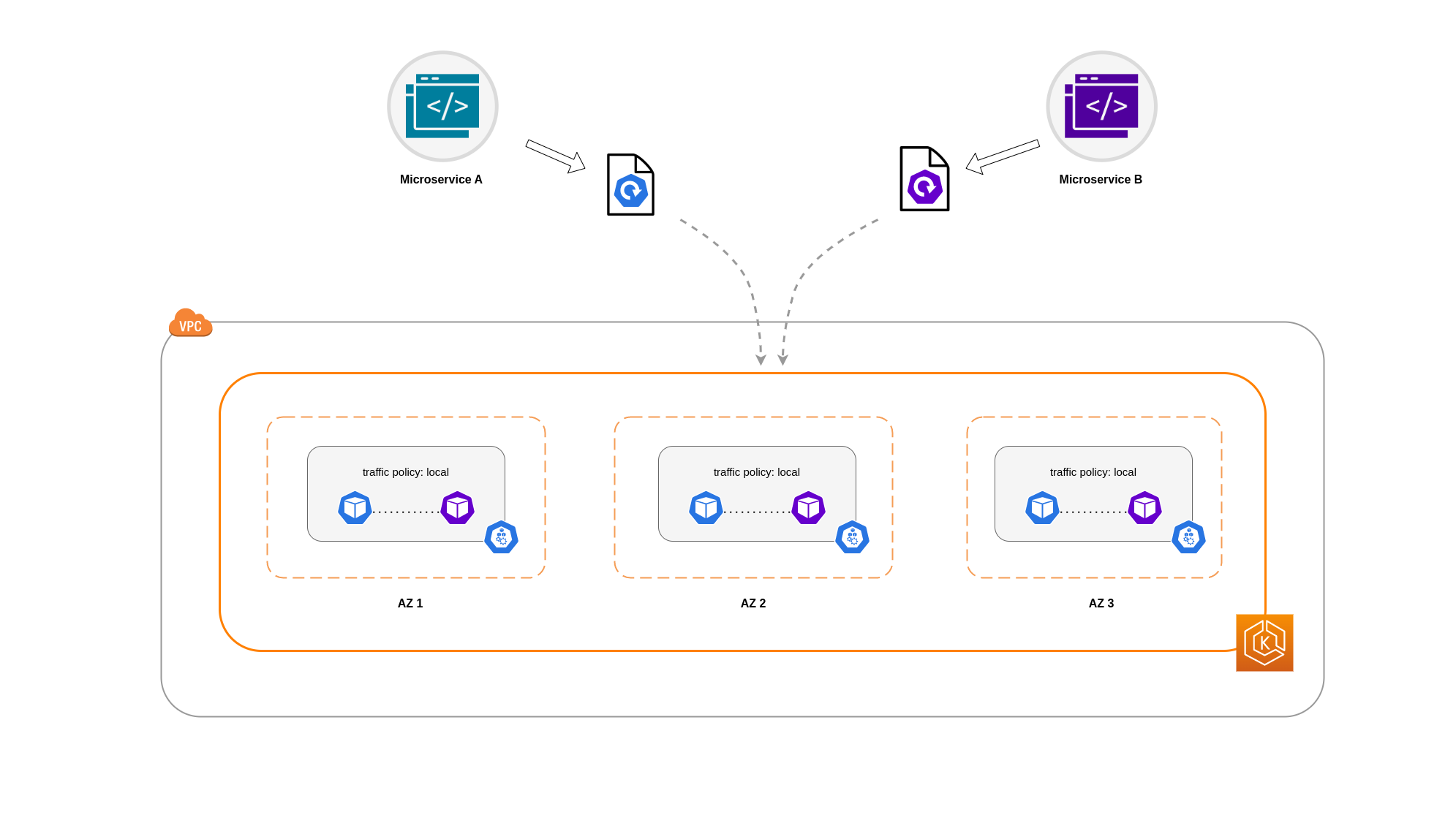
在某些情況下,限制區域層級的流量是不夠的。除了降低成本之外,您可能還需要減少某些經常相互通訊之應用程式之間的網路延遲。為了獲得最佳網路效能並降低成本,您需要一種方法來限制特定節點的流量。例如,微服務 A 應一律與節點 1 上的微服務 B 交談,即使在高可用性 (HA) 設定中也是如此。讓節點 1 上的微服務 A 與節點 2 上的微服務 B 交談,可能會對此類應用程式所需的效能產生負面影響,特別是當節點 2 完全位於單獨的可用區域時。
使用服務內部流量政策
若要將 Pod 網路流量限制為節點,您可以使用服務內部流量政策Local,流量將限制為流量來源節點上的端點。此政策會指定節點本機端點的專屬使用。透過隱含,該工作負載的網路流量相關成本將低於分佈的叢集範圍。此外,延遲會較低,讓您的應用程式效能更高。
注意
請務必注意,此功能無法與 Kubernetes 中的拓撲感知路由結合使用。
以下是有關如何設定服務內部流量政策的程式碼片段。
apiVersion: v1 kind: Service metadata: name: orders-service namespace: ecommerce spec: selector: app: orders type: ClusterIP ports: * protocol: TCP port: 3003 targetPort: 3003 internalTrafficPolicy: Local
為了避免因流量下降而導致應用程式的意外行為,您應該考慮以下方法:
-
為每個通訊 Pod 執行足夠的複本
-
使用拓撲分散限制條件,讓 Pod 的分散
相對均勻 -
將 Pod 親和性規則
用於通訊 Pod 的共同位置
在此範例中,您有 2 個 Microservice A 複本和 3 個 Microservice B 複本。如果 Microservice A 的複本分散在節點 1 和 2 之間,且 Microservice B 在節點 3 上有全部 3 個複本,則由於Local內部流量政策,他們將無法通訊。如果沒有可用的節點本機端點,則會捨棄流量。

如果 Microservice B 在節點 1 和 2 上有其 3 個複本中的 2 個,則對等應用程式之間會進行通訊。但是,您仍然會有 Microservice B 的隔離複本,而沒有任何對等複本可供通訊。
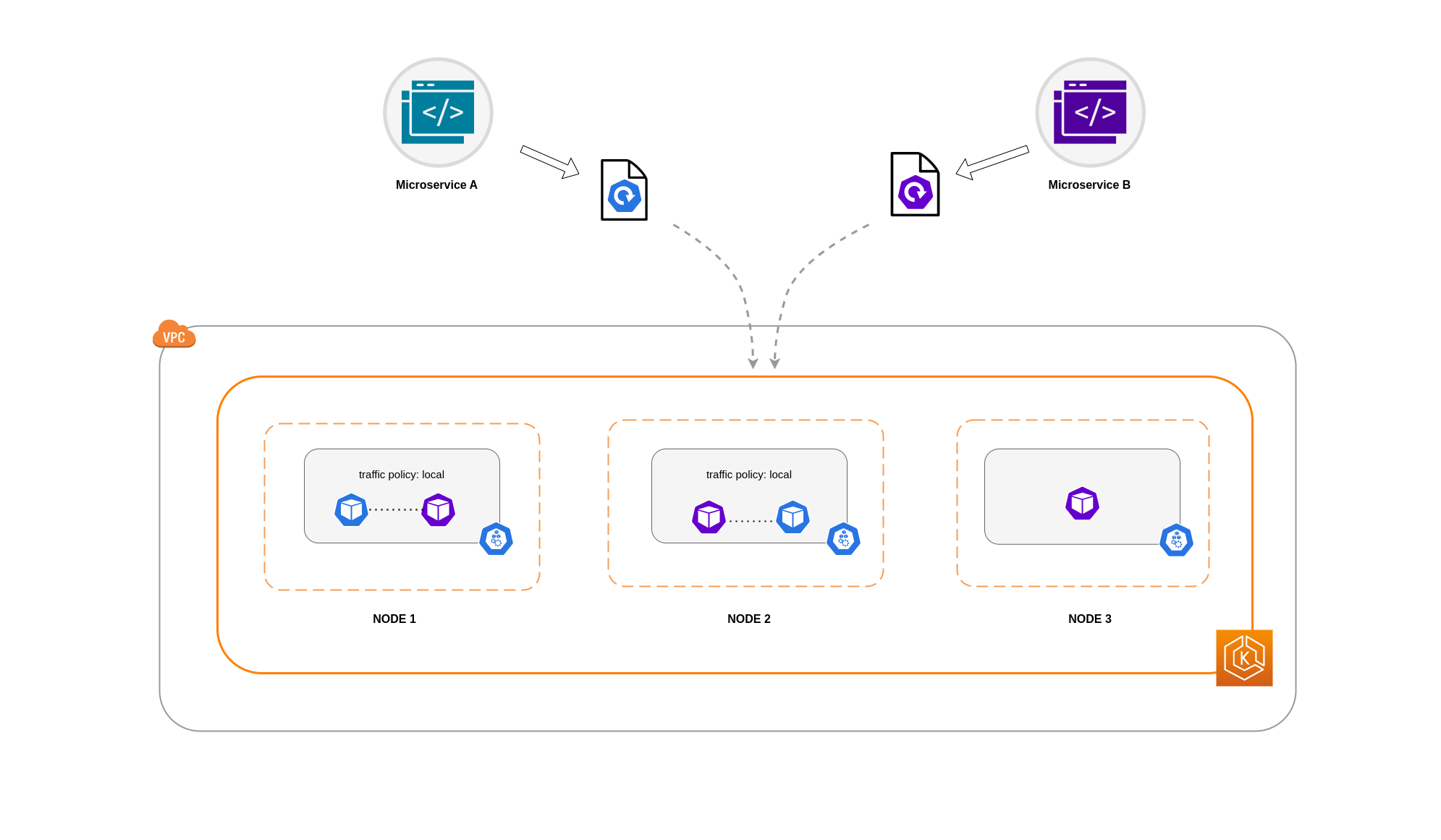
注意
在某些情況下,如上圖中描述的隔離複本,如果仍有用途 (例如提供來自外部傳入流量的請求),則可能不會引起疑慮。
使用服務內部流量政策與拓撲分散限制條件
搭配使用內部流量政策與拓撲分散限制,有助於確保您擁有適當數量的複本,以在不同節點上通訊微服務。
apiVersion: apps/v1 kind: Deployment metadata: name: express-test spec: replicas: 6 selector: matchLabels: app: express-test template: metadata: labels: app: express-test tier: backend spec: topologySpreadConstraints: - maxSkew: 1 topologyKey: "topology.kubernetes.io/zone" whenUnsatisfiable: ScheduleAnyway labelSelector: matchLabels: app: express-test
搭配 Pod 親和性規則使用服務內部流量政策
另一種方法是在使用服務內部流量政策時,使用 Pod 親和性規則。使用 Pod 親和性,您可以影響排程器來聯合定位某些 Pod,因為它們經常通訊。透過在特定 Pod 上套用嚴格的排程限制 (requiredDuringSchedulingIgnoredDuringExecution),當排程器將 Pod 放置在節點上時,這將為您提供更好的 Pod 共置結果。
apiVersion: apps/v1 kind: Deployment metadata: name: graphql namespace: ecommerce labels: app.kubernetes.io/version: "0.1.6" ... spec: serviceAccountName: graphql-service-account affinity: podAffinity: requiredDuringSchedulingIgnoredDuringExecution: - labelSelector: matchExpressions: - key: app operator: In values: - orders topologyKey: "kubernetes.io/hostname"
Load Balancer與 Pod 通訊
EKS 工作負載通常由負載平衡器前置,將流量分配到 EKS 叢集中的相關 Pod。您的架構可能包含內部和/或外部面向的負載平衡器。根據您的架構和網路流量組態,負載平衡器和 Pod 之間的通訊可能會產生大量的資料傳輸費用。
您可以使用 AWS Load Balancer 控制器
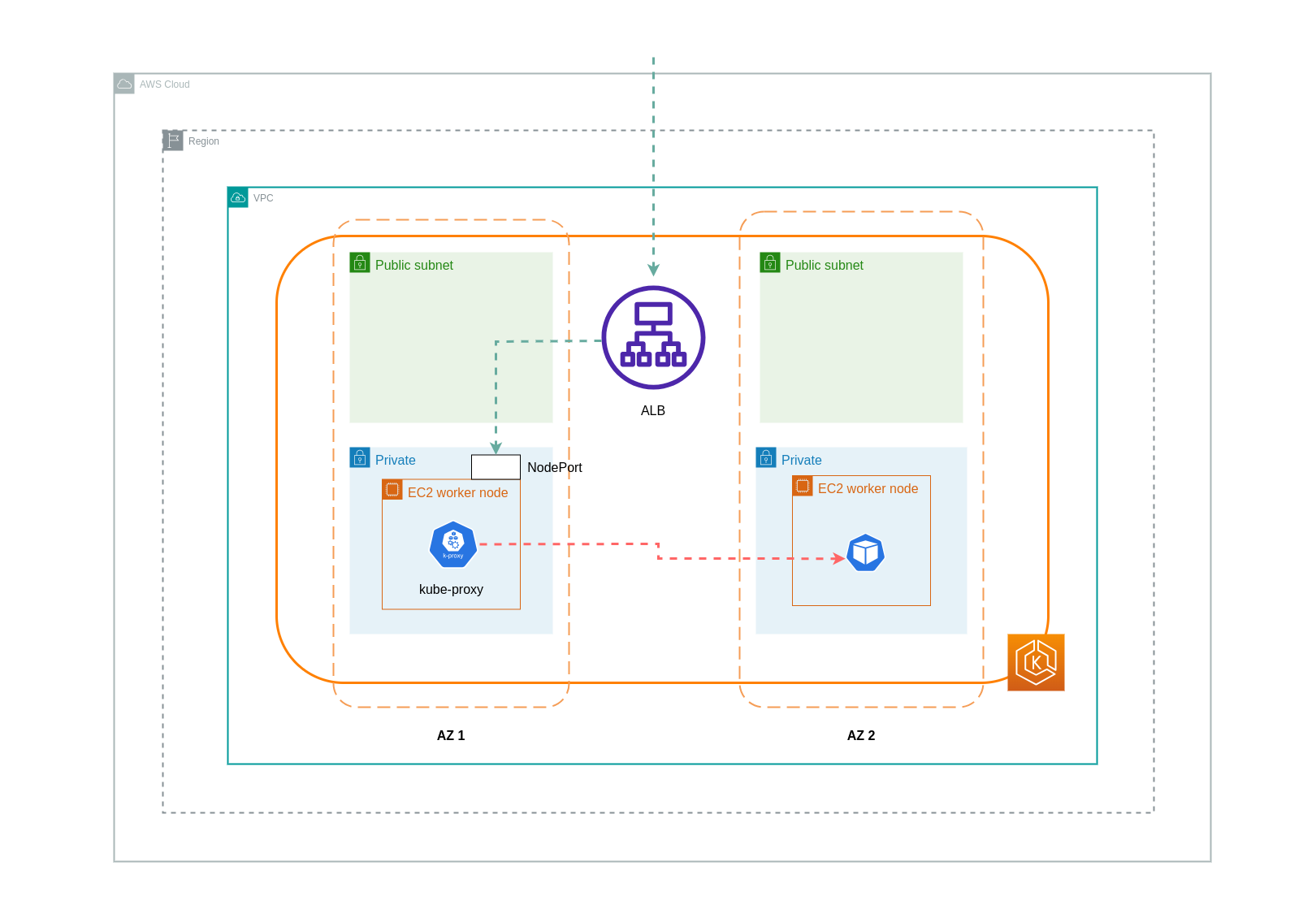
使用執行個體模式時,會在 EKS 叢集中的每個節點上開啟 NodePort。然後,負載平衡器會跨節點平均代理流量。如果節點上執行目的地 Pod,則不會產生資料傳輸費用。不過,如果目的地 Pod 位於另一個節點,且位於與接收流量的 NodePort 不同的 AZ 中,則會有從 kube-proxy 到目的地 Pod 的額外網路跳轉。在這種情況下,會產生跨可用區域資料傳輸費用。由於跨節點的流量均勻分佈,從 kube-proxies 到相關目的地 Pod 的跨區域網路流量跳轉可能會產生額外的資料傳輸費用。
下圖說明從負載平衡器流向 NodePort,然後從 kube-proxy流向不同 AZ 中不同節點上目的地 Pod 之流量的網路路徑。這是執行個體模式設定的範例。
使用 ip 模式時,網路流量會從負載平衡器直接代理至目的地 Pod。因此,此方法不會涉及任何資料傳輸費用。
注意
建議您將負載平衡器設定為 IP 流量模式,以減少資料傳輸費用。對於此設定,確保您的負載平衡器部署在 VPC 中的所有子網路中也很重要。
下圖說明網路 IP 模式下從負載平衡器流向 Pod 之流量的網路路徑。

從容器登錄檔傳輸資料
Amazon ECR
將資料傳輸到 Amazon ECR 私有登錄檔是免費的。區域內資料傳輸不會產生任何費用,但傳輸至網際網路和跨區域的資料將按傳輸兩端的網際網路資料傳輸費率收費。
您應該使用 ECRs內建映像複寫功能,將相關容器映像複寫到與工作負載相同的區域。如此一來,複寫就會收取一次費用,而且所有相同的區域 (區域內) 映像提取都是免費的。
您可以使用介面 VPC 端點連線至區域內 ECR 儲存庫,進一步降低從 ECR 提取映像 (資料傳輸輸出) 的相關資料傳輸成本。連線到 ECR 公有 AWS 端點 (透過 NAT Gateway 和網際網路閘道) 的替代方法會產生更高的資料處理和傳輸成本。下一節將詳細說明降低工作負載與 AWS Services 之間的資料傳輸成本。
如果您使用特別是大型映像執行工作負載,您可以使用預先快取的容器映像建置自己的自訂 Amazon Machine Image (AMIs)。這可以減少從容器登錄檔到 EKS 工作者節點的初始映像提取時間和潛在的資料傳輸成本。
資料傳輸至網際網路和 AWS 服務
這是透過網際網路將 Kubernetes 工作負載與其他 AWS 服務或第三方工具和平台整合的常見做法。用於往返相關目的地流量的基礎網路基礎設施可能會影響資料傳輸過程中產生的成本。
使用 NAT 閘道
NAT Gateways 是執行網路位址轉譯 (NAT) 的網路元件。下圖說明 EKS 叢集中與其他 AWS 服務 (Amazon ECR、DynamoDB 和 S3) 和第三方平台通訊的 Pod。在此範例中,Pod 會在個別 AZs 的私有子網路中執行。若要從網際網路傳送和接收流量,NAT Gateway 會部署到一個可用區域的公有子網路,允許具有私有 IP 地址的任何資源共用單一公有 IP 地址以存取網際網路。此 NAT Gateway 會接著與網際網路閘道元件通訊,允許封包傳送到其最終目的地。
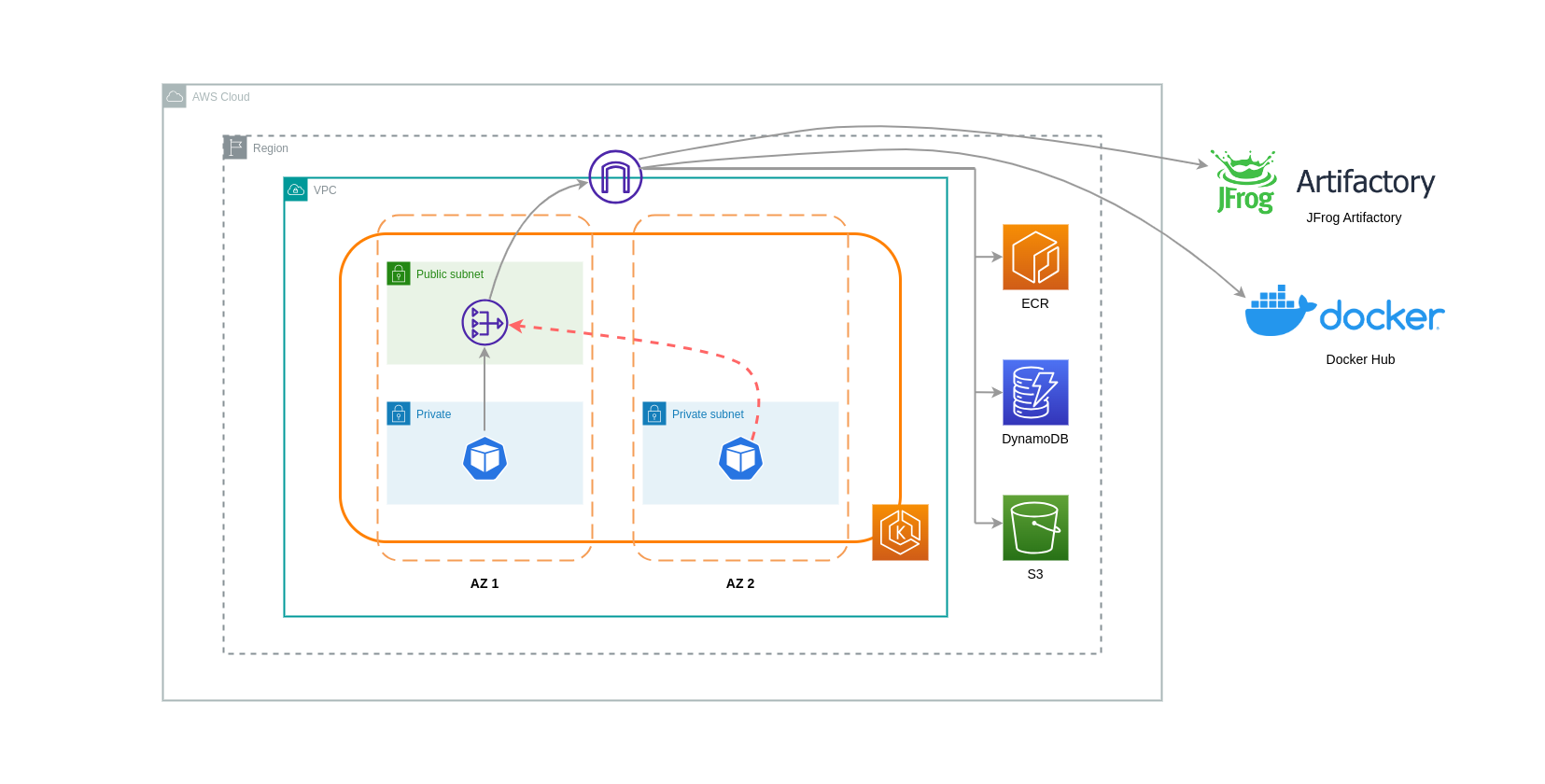
在此類使用案例中使用 NAT Gateway 時,您可以透過在每個 AZ 中部署 NAT Gateway,將資料傳輸成本降至最低。如此一來,路由至網際網路的流量將通過相同 AZ 中的 NAT Gateway,避免跨 AZ 資料傳輸。不過,即使您將節省跨可用區資料傳輸的成本,但此設定的含意在於您在架構中會產生額外的 NAT Gateway 成本。
此建議的方法如下圖所示。

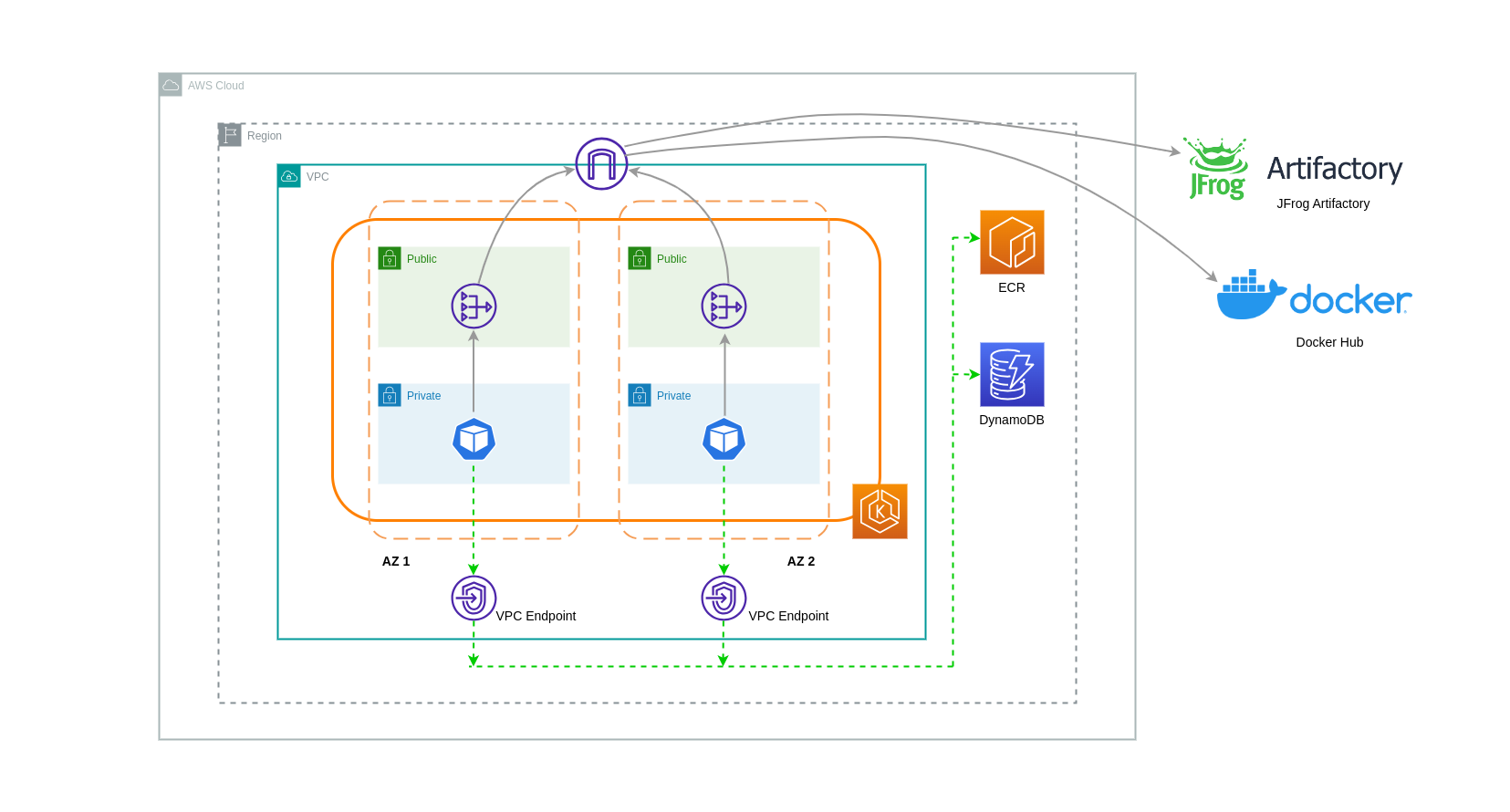
使用 VPC 端點
若要進一步降低此類架構的成本,您應該使用 VPC 端點在工作負載和 AWS 服務之間建立連線。VPC 端點可讓您從 VPC 內存取 AWS 服務,無需資料/網路封包周遊網際網路。所有流量都是內部的,並保留在 AWS 網路中。VPC 端點有兩種類型:界面 VPC 端點 (受許多 AWS 服務支援) 和閘道 VPC 端點 (僅受 S3 和 DynamoDB 支援)。
閘道 VPC 端點
閘道 VPC 端點沒有相關的每小時或資料傳輸成本。使用閘道 VPC 端點時,請務必注意它們無法跨 VPC 邊界延伸。它們無法用於 VPC 對等互連、VPN 聯網或透過 Direct Connect 使用。
介面 VPC 端點
VPC 端點會按小時計費
下圖顯示透過 VPC 端點與 AWS 服務通訊的 Pod。
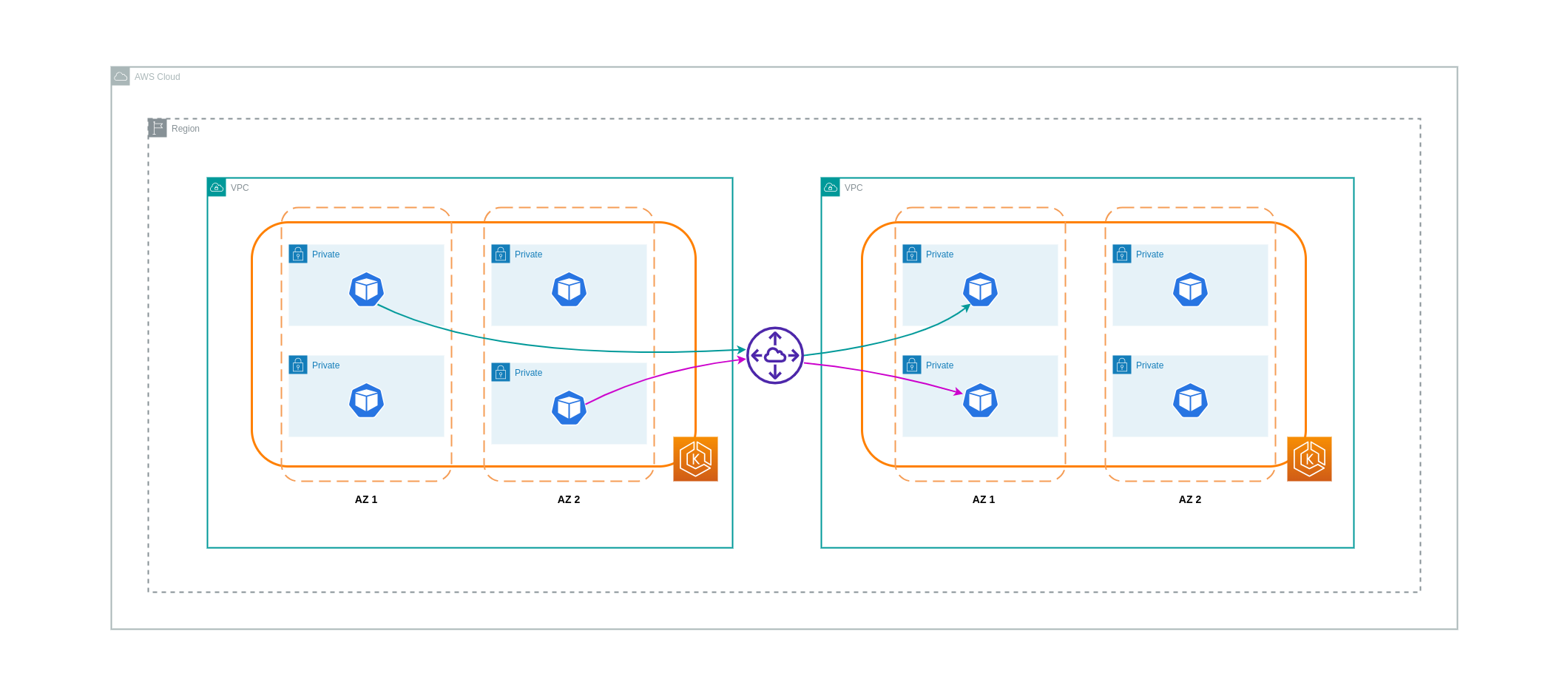
VPCs之間的資料傳輸
在某些情況下,您可能會在不同的 VPCs中 (在同一 AWS 區域內) 有工作負載,需要彼此通訊。這可以透過連接到個別 VPCs 的網際網路閘道,允許流量周遊公有網際網路來完成。這類通訊可以透過在公有子網路中部署基礎設施元件,例如 EC2 執行個體、NAT 閘道或 NAT 執行個體來啟用。不過,包含這些元件的設定將產生處理/傳輸資料進出 VPCs的費用。如果往返個別 VPCs流量在 AZs 之間移動,則資料傳輸會產生額外費用。下圖說明使用 NAT 閘道和網際網路閘道,在不同 VPCs 中的工作負載之間建立通訊的設定。

VPC 互連連線
若要降低此類使用案例的成本,您可以使用 VPC 對等互連。使用 VPC 對等互連時,保留在相同可用區域內的網路流量無需支付資料傳輸費用。如果流量超過 AZs,會產生費用。不過,建議採用 VPC 對等互連方法來在相同 AWS 區域內不同 VPCs 中的工作負載之間進行符合成本效益的通訊。不過,請務必注意,VPC 對等互連主要對 1:1 VPC 連線有效,因為它不允許傳輸式聯網。
下圖是透過 VPC 互連連線進行工作負載通訊的高階表示。
暫時性網路連線
如上一節所述,VPC 對等互連不允許傳輸網路連線。如果您想要連接 3 個以上的 VPCs 與傳輸性聯網需求,則應使用 Transit Gateway (TGW)。這可讓您克服 VPC 對等互連的限制或與在多個 VPC 之間具有多個 VPC 對等互連相關聯的任何操作額外負荷 VPCs 。對於傳送至 TGW 的資料,您需要按小時計費
下圖顯示在不同 VPCs但在相同 AWS 區域內流經 TGW 的可用區域間流量。
使用服務網格
服務網格提供強大的聯網功能,可用於降低 EKS 叢集環境中的網路相關成本。不過,如果您採用服務網格,您應該仔細考慮其將對您的環境帶來的操作任務和複雜性。
將流量限制為可用區域
使用 Istio 的地區加權分佈
Istio 可讓您在路由發生後將網路政策套用至流量。這是使用目的地規則
上述 Istio 目的地規則也可以套用,以管理從負載平衡器到 EKS 叢集中 Pod 的流量。地區加權分佈規則可以套用至接收來自高可用性負載平衡器 (特別是輸入閘道) 流量的服務。這些規則可讓您根據區域原始伺服器 - 在這種情況下的負載平衡器,控制流向何處的流量。如果設定正確,相較於將流量平均或隨機分配到不同AZs Pod 複本的負載平衡器,產生的輸出跨區域流量較少。
以下是 Istio 中目的地規則資源的程式碼區塊範例。如下方所示,此資源會指定區域中 3 個不同AZs傳入流量的加權組態eu-west-1。這些組態宣告,來自指定 AZ 的大部分傳入流量 (在此案例中為 70%) 應代理至其來源相同 AZ 中的目的地。
apiVersion: networking.istio.io/v1beta1 kind: DestinationRule metadata: name: express-test-dr spec: host: express-test.default.svc.cluster.local trafficPolicy: loadBalancer: + localityLbSetting: distribute: - from: eu-west-1/eu-west-1a/ + to: "eu-west-1/eu-west-1a/_": 70 "eu-west-1/eu-west-1b/_": 20 "eu-west-1/eu-west-1c/_": 10 - from: eu-west-1/eu-west-1b/_ + to: "eu-west-1/eu-west-1a/_": 20 "eu-west-1/eu-west-1b/_": 70 "eu-west-1/eu-west-1c/_": 10 - from: eu-west-1/eu-west-1c/_ + to: "eu-west-1/eu-west-1a/_": 20 "eu-west-1/eu-west-1b/_": 10 "eu-west-1/eu-west-1c/*": 70** connectionPool: http: http2MaxRequests: 10 maxRequestsPerConnection: 10 outlierDetection: consecutiveGatewayErrors: 1 interval: 1m baseEjectionTime: 30s
注意
可分佈目的地的最小權重為 1%。這是因為在主要目的地中的端點運作狀態不佳或無法使用的情況下,維護容錯移轉區域和區域。
下圖說明 eu-west-1 區域中具有高度可用負載平衡器的情況,並套用地區權重分佈。此圖表的目的地規則政策設定為將 60% 來自 eu-west-1a 的流量傳送至相同 AZ 中的 Pod,而 40% 來自 eu-west-1a 的流量應傳送至 eu-west-1b 中的 Pod。

將流量限制為可用區域和節點
搭配 Istio 使用服務內部流量政策
若要降低與外部傳入流量和 Pod 之間的內部流量相關的網路成本,您可以結合 Istio 的目的地規則和 Kubernetes Service 內部流量政策。將 Istio 目的地規則與服務內部流量政策結合的方式,主要取決於 3 件事:
-
微服務的角色
-
跨微服務的網路流量模式
-
應如何跨 Kubernetes 叢集拓撲部署微服務
下圖顯示巢狀請求的網路流程會是什麼樣子,以及上述政策如何控制流量。
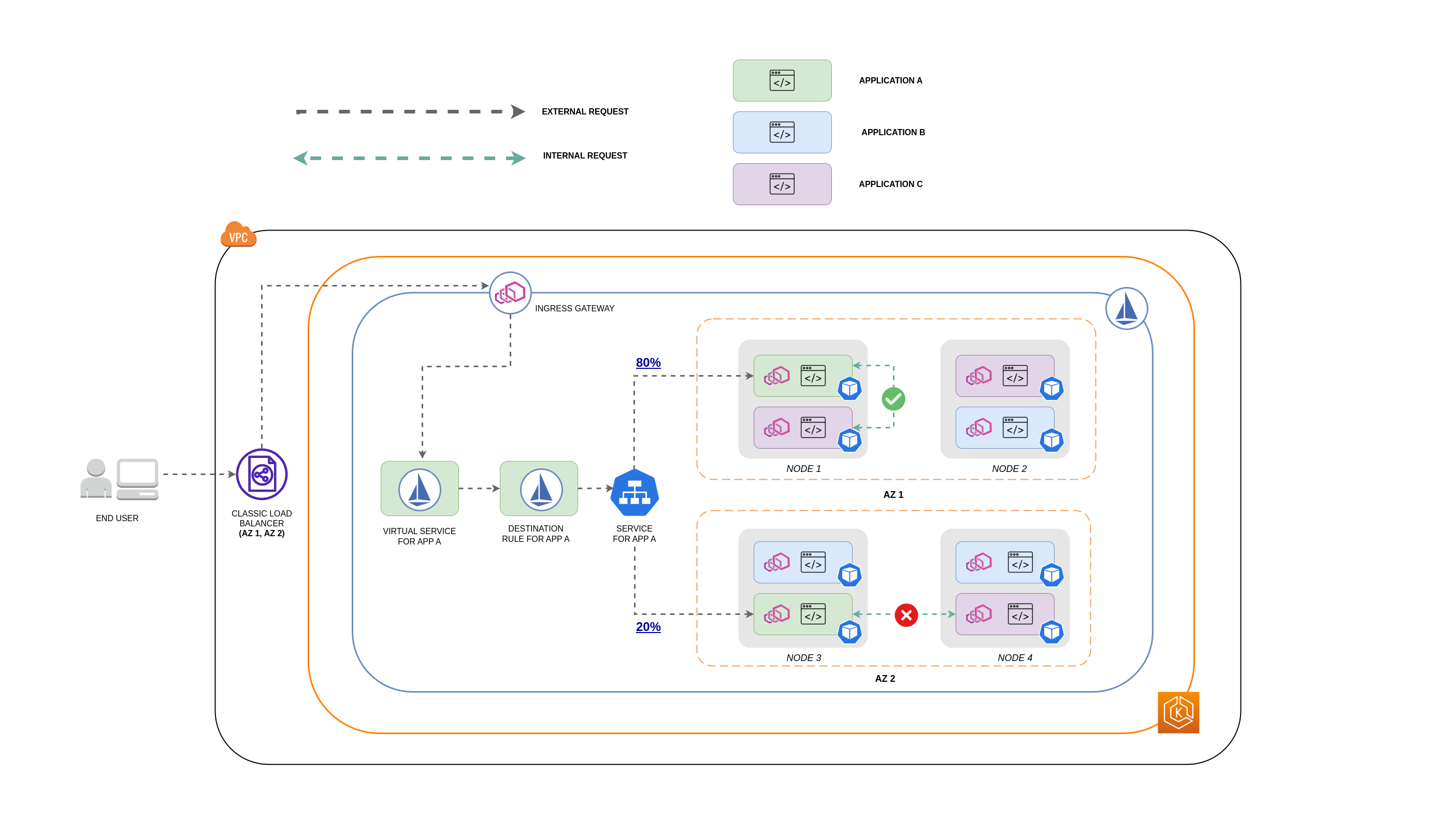
-
最終使用者向 APP A 提出請求,進而向 APP C 提出巢狀請求。 此請求會先傳送至高可用性的負載平衡器,其在 AZ 1 和 AZ 2 中具有執行個體,如上圖所示。
-
外部傳入請求接著會由 Istio Virtual Service 路由至正確的目的地。
-
請求路由後,Istio 目的地規則會根據其來源 (AZs 1 或 AZ 2) 控制流向個別 AZ 的流量。
-
接著流量會移至 Service for APP A,然後代理至個別的 Pod 端點。如圖所示,80% 的傳入流量會傳送至 AZ 1 中的 Pod 端點,而 20% 的傳入流量會傳送至 AZ 2。
-
然後,APP A 向 APP C 提出內部請求。 APP C 的服務已啟用內部流量政策 (
internalTrafficPolicy`:Local`)。 -
由於 APP C 可用的節點本機端點,從 APP A (NODE 1) 到 APP C 的內部請求成功。
-
從 APP A (NODE 3) 到 APP C 的內部請求失敗,因為 APP C 沒有可用的節點本機端點。 如圖所示,APP C 在 NODE 3 上沒有複本。 **
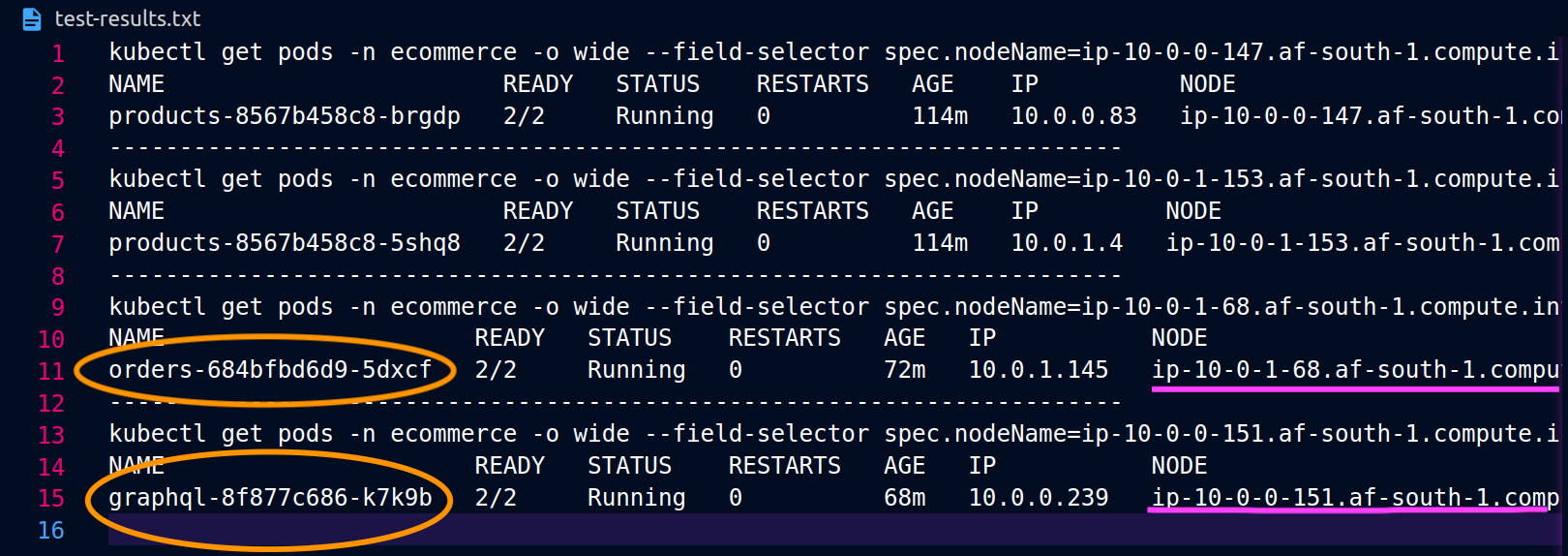
以下螢幕擷取畫面是從此方法的即時範例擷取。第一組螢幕擷取畫面示範對 的成功外部請求,graphql以及從 成功巢狀請求graphql到節點 上共置orders複本ip-10-0-0-151.af-south-1.compute.internal。


使用 Istio,您可以驗證和匯出代理知道的任何 【上游叢集】(https://www.envoyproxy.io/docs/envoy/latest/intro/arch_overview/intro/terminologygraphql代理知道的orders端點:
kubectl exec -it deploy/graphql -n ecommerce -c istio-proxy -- curl localhost:15000/clusters | grep orders
... orders-service.ecommerce.svc.cluster.local::10.0.1.33:3003::**rq_error::0** orders-service.ecommerce.svc.cluster.local::10.0.1.33:3003::**rq_success::119** orders-service.ecommerce.svc.cluster.local::10.0.1.33:3003::**rq_timeout::0** orders-service.ecommerce.svc.cluster.local::10.0.1.33:3003::**rq_total::119** orders-service.ecommerce.svc.cluster.local::10.0.1.33:3003::**health_flags::healthy** orders-service.ecommerce.svc.cluster.local::10.0.1.33:3003::**region::af-south-1** orders-service.ecommerce.svc.cluster.local::10.0.1.33:3003::**zone::af-south-1b** ...
在此情況下,graphql代理只會知道其共用節點之複本的orders端點。如果您從訂單 Service 中移除internalTrafficPolicy: Local設定,並重新執行如上述的命令,則結果會傳回分散在不同節點的複本的所有端點。此外,透過檢查個別端點rq_total的 ,您會注意到網路分佈中相對均勻的共用。因此,如果端點與在不同 AZs 中執行的上游服務相關聯,則跨區域的此網路分佈將產生更高的成本。
如上一節所述,您可以透過利用 Pod 親和性來共同定位經常通訊的 Pod。
... spec: ... template: metadata: labels: app: graphql role: api workload: ecommerce spec: affinity: podAffinity: requiredDuringSchedulingIgnoredDuringExecution: - labelSelector: matchExpressions: - key: app operator: In values: - orders topologyKey: "kubernetes.io/hostname" nodeSelector: managedBy: karpenter billing-team: ecommerce ...
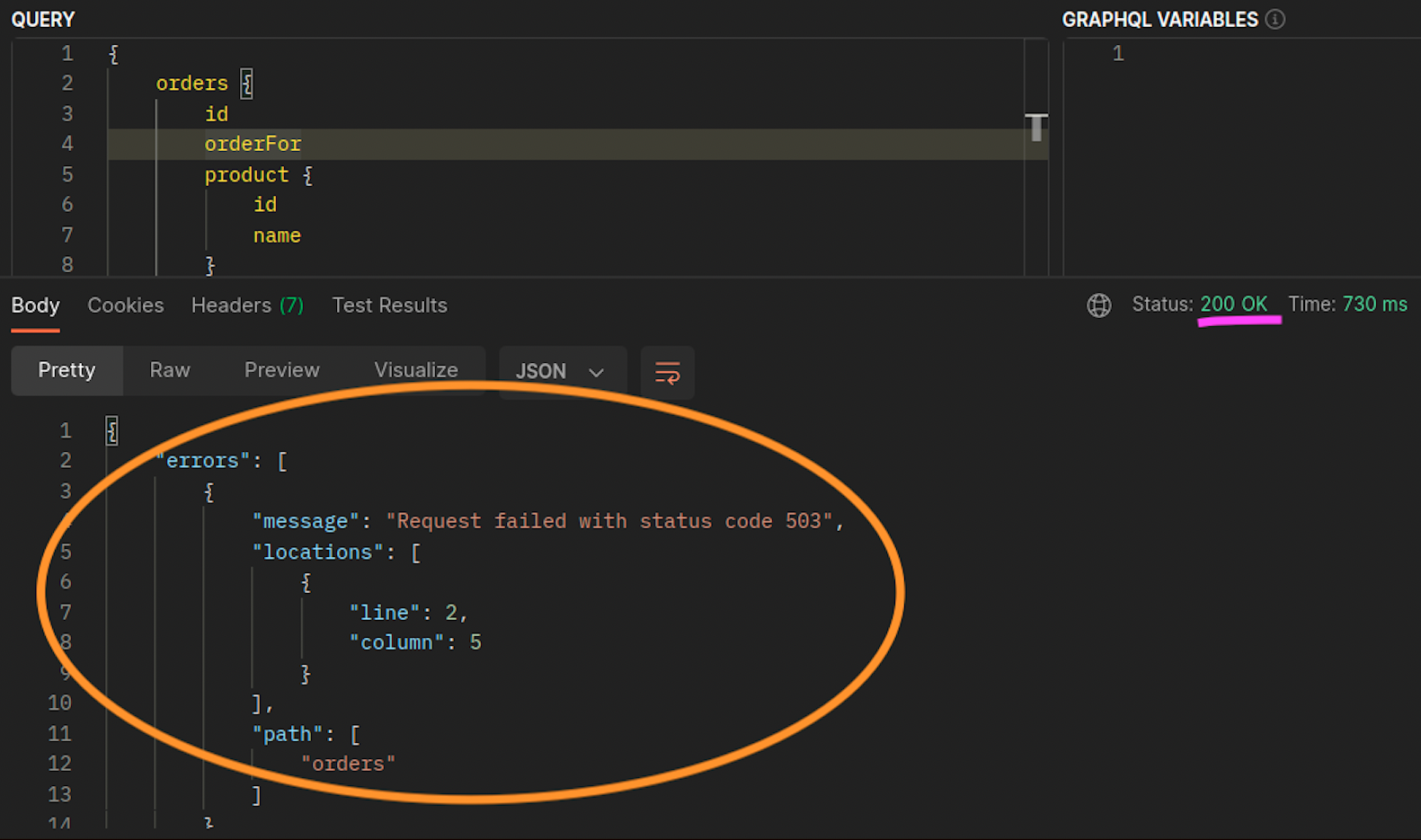
當 graphql和 orders 複本不存在於相同的節點 (ip-10-0-0-151.af-south-1.compute.internal) 時,對 的第一個請求graphql會成功,如下方 200 response code Postman 螢幕擷取畫面中的 所述,而來自 graphql的第二個巢狀請求會因 而orders失敗503 response code。
其他資源
