Amazon Forecast 不再提供給新客戶。Amazon Forecast 的現有客戶可以繼續正常使用服務。進一步了解」
本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
預測可解釋性
Forecast Explainability 可協助您更了解資料集中的屬性如何影響特定時間序列 (項目和維度組合) 和時間點的預測。預測會使用稱為影響分數的指標來量化每個屬性的相對影響,並判斷它們是否增加或減少預測值。
例如,假設目標所為 sales 且有兩個相關屬性的預測案例:price 與 color。預測可能會發現項目的顏色對某些項目的銷售有很大的影響,但對其他項目的影響可忽略不計。它也可能發現,在夏季的促銷活動對銷售有很大的影響,但在冬季促銷影響不大。
若要啟用預測可解釋性,您的預測器必須至少包含下列其中一項:相關時間序列、項目中繼資料,或假日和天氣索引等其他資料集。如需更多資訊,請參閱限制和最佳實務。
若要檢視資料集中所有時間序列和時間點的彙總影響分數,請使用 Predictor 可解釋性,而非預測可解釋性。請參閱預測器可解釋性。
Python 筆記本
如需預測可解釋性的step-by-step指南,請參閱項目層級可解釋性
解讀影響分數
影響分數會衡量屬性對預測值的相對影響。例如,如果「價格」屬性的影響分數是「存放區位置」屬性的兩倍,您可以得出以下結論:項目的價格對預測值的影響是商店位置的兩倍。
影響分數也會提供屬性是否增加或減少預測值的相關資訊。在 主控台中,這由兩個圖形表示。具有藍條的屬性會增加預測值,而具有紅條的屬性則會減少預測值。
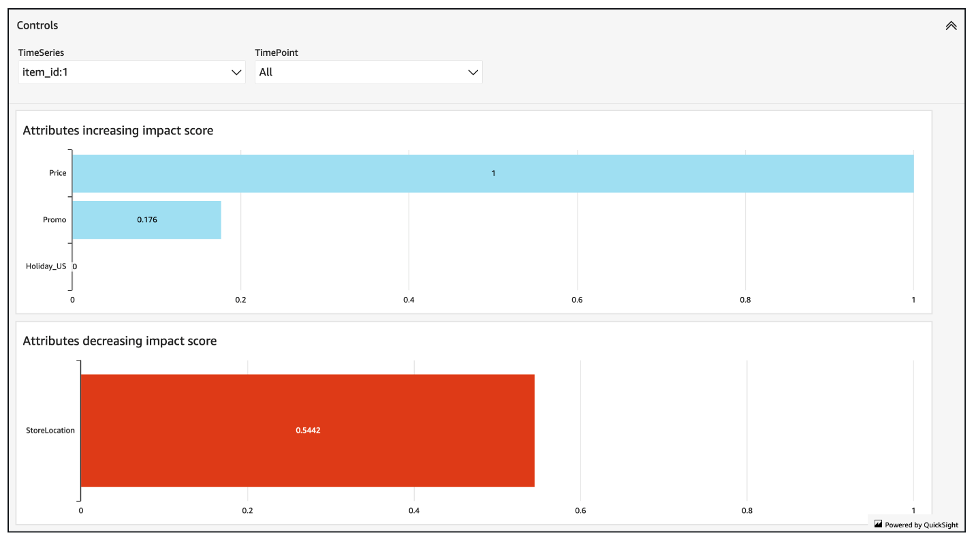
值得注意的是,影響力分數衡量的是屬性的相對影響,而不是絕對影響。因此,影響分數無法用於確定特定屬性是否可以改善模型的準確性。如果某個屬性的影響分數較低,不一定表示它對預測值的影響較低; 這表示與它對預測值的影響比預測器使用的其他屬性要小。
所有或部分影響分數可能為零。如果功能不會影響預測值、AutoPredictor 僅使用非 ML 演算法,或您未提供相關的時間序列或項目中繼資料,則可能會發生這種情況。
對於預測可解釋性,影響分數有兩種形式:標準化影響分數和原始影響分數。原始影響分數是以 Shapley 值為基礎,且不會擴展或繫結。標準化影響分數會將原始分數擴展到介於 -1 和 1 之間的值。
原始影響分數有助於合併和比較不同可解釋性資源的分數。例如,如果您的預測器包含超過 50 個時間序列或超過 500 個時間點,您可以建立多個預測可解釋性資源,以涵蓋更多時間序列或時間點的合併數量,並直接比較屬性的原始影響分數。不過,來自不同預測的預測可解釋性資源的原始影響分數無法直接比較。
在主控台中檢視影響分數時,您將只會看到標準化影響分數。匯出可解釋性將為您提供原始和標準化分數。
建立預測可解釋性
透過預測可解釋性,您可以探索屬性如何影響特定時間點特定時間序列的預測值。指定時間序列和時間點之後,Amazon Forecast 只會計算這些特定時間序列和時間點的影響分數。
您可以使用軟體開發套件 (SDK) 或 Amazon Forecast 主控台,為預測器啟用預測可解釋性。使用 SDK 時,請使用 CreateExplainability 操作。
指定時間序列
注意
時間序列是項目 (item_id) 和資料集中所有維度的組合
當您為預測可解釋性指定時間序列 (項目和維度組合) 時,Amazon Forecast 只會計算這些特定時間序列屬性的影響分數。
若要指定時間序列的清單,請上傳 CSV 檔案,以依其 item_id 和維度值識別時間序列。 S3 您最多可以指定 50 個時間序列。您還必須在結構描述中定義時間序列的屬性和屬性類型。
例如,零售商可能想知道促銷如何影響特定商店位置 (item_id) 中特定項目 () 的銷售store_location。在此使用案例中,您會指定時間序列,其為 item_id 和 store_location 的組合。
下列 CSV 檔案會選取下列五個時間序列:
-
Item_id:001,store_location:西雅圖
-
Item_id:001,store_location:New York
-
Item_id:002, store_location: Seattle
-
Item_id:002,store_location:New York
-
Item_id:003, store_location: Denver
001, Seattle 001, New York 002, Seattle 002, New York 003, Denver
結構描述將第一欄定義為 item_id,第二欄定義為 store_location。
您可以使用預測主控台或預測軟體開發套件 (SDK) 來指定時間序列。
指定時間點
注意
如果您未指定時間點 ("TimePointGranularity": "ALL"),Amazon Forecast 會在計算影響分數時考慮整個預測期間。
當您指定預測可解釋性的時間點時,Amazon Forecast 會計算該特定時間範圍屬性的影響分數。您可以在預測期間內指定最多 500 個連續時間點。
例如,零售商可能想知道其屬性如何影響冬季的銷售。在此使用案例中,他們會指定僅跨越預測時間範圍中冬季期間的時間點。
您可以使用預測主控台或預測軟體開發套件 (SDK) 來指定時間點。
視覺化預測可解釋性
在主控台中建立預測可解釋性時,預測會自動視覺化您的影響分數。使用 CreateExplainability 操作建立預測可解釋性時,EnableVisualization設為「true」,該可解釋性資源的影響分數將在主控台中視覺化。
影響分數視覺化從可解釋性建立日期起持續 30 天。若要重新建立視覺化效果,請建立新的預測可解釋性。
匯出預測可解釋性
注意
匯出檔案可以直接從資料集匯入傳回資訊。如果匯入的資料含公式或命令,這會使檔案受到 CSV 注入的攻擊。因此,匯出的檔案可能會提示安全性警告。若要避免惡意活動,請在讀取匯出的檔案時停用連結和巨集。
預測可讓您將影響分數的 CSV 檔案匯出至 S3 位置。
匯出包含指定時間序列的原始和標準化影響分數,以及所有指定時間序列和所有指定時間點的標準化彙總影響分數。如果您未指定時間點,則已彙總預測期間所有時間點的影響分數。

您可以使用 Amazon Forecast 軟體開發套件 (SDK) 和 Amazon Forecast 主控台匯出 Forecast Explainability。
限制和最佳實務
使用 Forecast Explainability 時,請考慮下列限制和最佳實務。
-
預測可解釋性僅適用於從 AutoPredictor 產生的某些預測 - 您無法為從舊版預測器產生的預測啟用預測可解釋性 (AutoML 或手動選擇)。請參閱升級至 AutoPredictor。
-
預測可解釋性不適用於所有模型 - ARIMA (AutoRegressive Integrated Moving Average)、ETS (Exponential Smoothing State Space Model) 和 NPTS (非參數時間序列) 模型不包含外部時間序列資料。因此,即使您包含其他資料集,這些模型也不會建立可解釋性報告。
-
可解釋性需要屬性 - 您的預測器必須至少包含下列其中一項:相關時間序列、項目中繼資料、假日或天氣索引。
-
零的影響分數表示沒有影響 - 如果一或多個屬性的影響分數為零,則這些屬性對預測值沒有重大影響。如果 AutoPredictor 只使用非 ML 演算法,或者您沒有提供相關的時間序列或項目中繼資料,則分數也可以為零。
-
指定最多 50 個時間序列 - 每個預測可解釋性最多可指定 50 個時間序列。
-
指定最多 500 個時間點 - 每個預測可解釋性最多可指定 500 個連續時間點。
-
預測也會計算一些彙總影響分數 - 預測也會提供指定時間序列和時間點的彙總影響分數。
-
為單一預測建立多個預測可解釋性資源 - 如果您想要超過 50 個時間序列或 500 個時間點的影響分數,您可以批次建立可解釋性資源,以跨越更大的範圍。
-
比較不同預測可解釋性資源的原始影響分數 - 原始影響分數可以直接比較相同預測中可解釋性資源的原始影響分數。
-
Forecast Explainability 視覺化效果可在建立後 30 天內使用 - 若要在 30 天後檢視視覺化效果,請使用相同的組態建立新的 Forecast Explainability。
