本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
Redshift 連線
您可以使用 AWS Glue for Spark 來讀取和寫入 Amazon Redshift 資料庫中的資料表。連線至 Amazon Redshift 資料庫時, AWS Glue 會使用 Amazon Redshift SQL COPY和 UNLOAD 命令,透過 Amazon S3 移動資料以達到最大輸送量。在 AWS Glue 4.0 和更新版本中,您可以使用適用於 Apache Spark 的 Amazon Redshift 整合來讀取和寫入 Amazon Redshift 特定的最佳化和功能,除了透過舊版連線時可用的功能之外。
了解 AWS Glue 如何讓 Amazon Redshift 使用者更輕鬆地遷移到 Glue AWS 以進行無伺服器資料整合和 ETL。
設定 Redshift 連線
若要在 Glue AWS 中使用 Amazon Redshift 叢集,您需要一些先決條件:
-
從資料庫讀取和寫入資料庫時用於暫存空間的 Amazon S3 目錄。
-
啟用 Amazon Redshift 叢集、Glue AWS 任務和 Amazon S3 目錄之間通訊的 Amazon VPC。
-
Glue 任務和 Amazon Redshift AWS 叢集的適當 IAM 許可。
設定 IAM 角色
設定 Amazon Redshift 叢集的角色
您的 Amazon Redshift 叢集需要能夠讀取和寫入 Amazon S3,才能與 Glue AWS 任務整合。若要允許這項功能,您可以將 IAM 角色與想要連線的 Amazon Redshift 叢集建立關聯。您的角色應具有允許從 Amazon S3 臨時目錄讀取和寫入該目錄的政策。您的角色應具有允許 redshift.amazonaws.com 服務 AssumeRole 的信任關係。
將 IAM 角色與 Amazon Redshift 建立關聯
先決條件:用於檔案暫存空間的 Amazon S3 儲存貯體或目錄。
-
確定您的 Amazon Redshift 叢集需要哪些 Amazon S3 許可。將資料移入和移出 Amazon Redshift 叢集時, AWS Glue 任務會針對 Amazon Redshift 發出 COPY 和 UNLOAD 陳述式。如果您的任務修改 Amazon Redshift 中的資料表, AWS Glue 也會發出 CREATE LIBRARY 陳述式。如需 Amazon Redshift 執行這些陳述式所需的特定 Amazon S3 許可資訊,請參閱 Amazon Redshift 文件:Amazon Redshift:存取其他 AWS 資源的許可。
在 IAM 主控台中,建立具有必要許可的 IAM 政策。如需有關建立政策的詳細資訊,請參閱建立 IAM 政策。
在 IAM 主控台中,建立角色和信任關係,以允許 Amazon Redshift 擔任該角色。遵循 IAM 文件中的指示為 AWS 服務建立角色 (主控台)
當系統要求選擇 AWS 服務使用案例時,請選擇「Redshift - Customizable」。
當系統要求您附加政策時,請選擇您先前定義的政策。
注意
如需設定 Amazon Redshift 角色的詳細資訊,請參閱《Amazon Redshift 文件》中的授權 Amazon Redshift 代表您存取其他 AWS 服務。
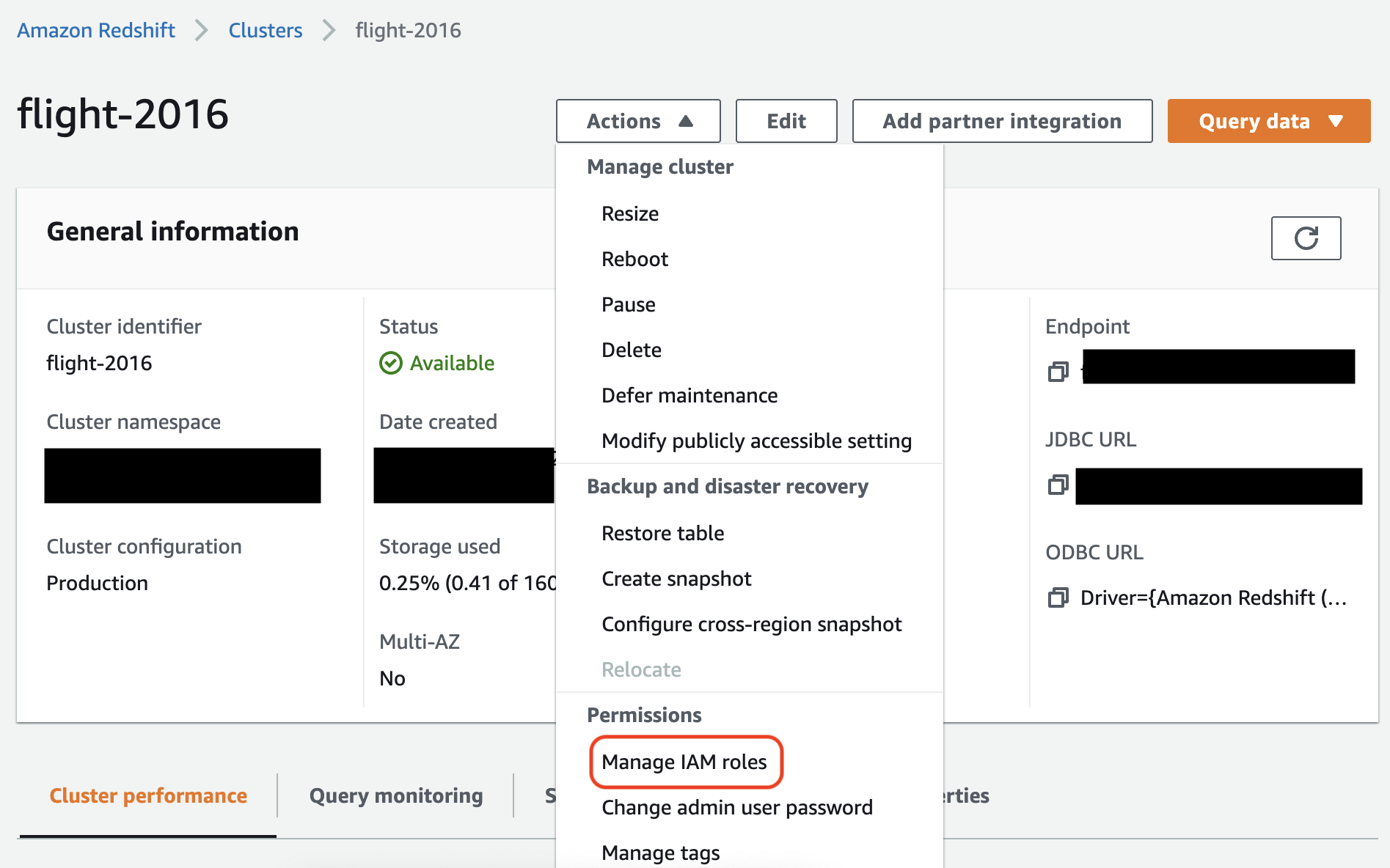
在 Amazon Redshift 主控台中,將角色與您的 Amazon Redshift 叢集建立關聯。請按照 Amazon Redshift 文件中的說明進行操作。
在 Amazon Redshift 主控台中選取反白顯示的選項,以進行此設定:
注意
根據預設, AWS Glue 任務會傳遞使用您指定執行任務的角色建立的 Amazon Redshift 臨時登入資料。我們不建議使用這些憑證。基於安全考量,這些憑證會在 1 小時後過期。
設定 Glue AWS 任務的角色
Glue AWS 任務需要角色才能存取 Amazon S3 儲存貯體。您不需要 Amazon Redshift 叢集的 IAM 許可,您的存取是由 Amazon VPC 中的連線和資料庫憑證來控制。
設定 Amazon VPC
設定 Amazon Redshift 資料存放區存取
登入 AWS Management Console ,並在 https://console.aws.amazon.com/redshiftv2/
:// 開啟 Amazon Redshift 主控台。 -
在左側導覽窗格中選擇叢集。
-
選擇您想要從 AWS Glue 存取的叢集名稱。
-
在 Cluster Properties (叢集屬性) 區段中,選擇 VPC security groups (VPC 安全群組) 中的安全群組,以允許 AWS Glue 使用。記錄所選的安全群組名稱,供日後參考。選擇安全群組後,將開啟 Amazon EC2 主控台安全群組清單。
-
選擇要修改的安全群組並導覽至 Inbound (傳入) 索引標籤。
-
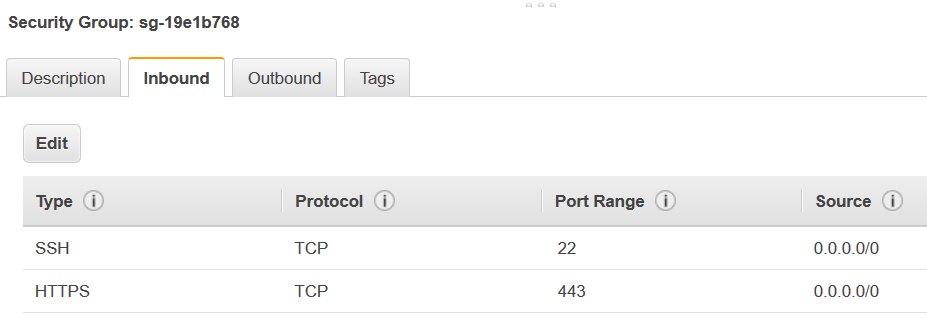
新增自我參考規則,以允許 AWS Glue 元件進行通訊。具體來說,新增或確認有類型
All TCP、通訊協定為TCP,連接埠範圍包含所有連接埠,且其來源與群組 ID 為相同安全群組名稱的規則。傳入規則類似如下:
Type 通訊協定 連接埠範圍 來源 所有 TCP
TCP
0–65535
database-security-group
例如:
-
同時新增一個規則,以用於傳出流量。您可以開啟傳出流量到所有連接埠,例如:
Type 通訊協定 連接埠範圍 目的地 所有流量
ALL
ALL
0.0.0.0/0
或建立 Type (類型)
All TCP、Protocol (通訊協定) 為TCP、Port Range (連接埠範圍) 包含所有連接埠,且其 Destination (目的地) 與 Group ID (群組 ID) 為相同安全群組名稱的自我參考規則。如果使用 Amazon S3 VPC 端點,也可以針對 Amazon S3 存取新增 HTTPS 規則。安全群組規則需s3-prefix-list-id,以允許該 VPC 至 Amazon S3 VPC 端點間的流量。例如:
Type 通訊協定 連接埠範圍 目的地 所有 TCP
TCP
0–65535
security-groupHTTPS
TCP
443
s3- 字首清單 ID
設定 AWS Glue
您需要建立提供 AWS Amazon VPC 連線資訊的 Glue Data Catalog 連線。
在主控台中設定 Amazon Redshift Amazon VPC 與 Glue AWS 的連線
-
依照下列步驟建立資料型錄連線:新增 AWS Glue 連線。建立連線之後,請保留連線名稱
connectionName,以便進行下一個步驟。選取連線類型時,請選取 Amazon Redshift。
選取 Redshift 叢集時,請依名稱選取您的叢集。
為叢集上的 Amazon Redshift 使用者提供預設連線資訊。
系統會自動進行 Amazon VPC 設定。
注意
當您透過 AWS SDK 建立 Amazon Redshift 連線時,您需要手動為 Amazon VPC 提供
PhysicalConnectionRequirements。 -
在您的 AWS Glue 任務組態中,提供
connectionName作為其他網路連線。
範例:從 Amazon Redshift 資料表讀取
您可以從 Amazon Redshift 叢集和 Amazon Redshift Serverless 環境讀取。
先決條件:您想要讀取的 Amazon Redshift 資料表。請按照上一節 設定 Redshift 連線 中的步驟進行操作,之後您應該擁有用於臨時目錄、temp-s3-dir 和 IAM 角色 rs-role-name (在帳戶 role-account-id 中) 的 Amazon S3 URI。
範例:寫入 Amazon Redshift 資料表
您可以寫入 Amazon Redshift 叢集和 Amazon Redshift Serverless 環境。
先決條件:Amazon Redshift 叢集,並按照上一節 設定 Redshift 連線 中的步驟進行操作,之後您應該擁有用於臨時目錄、temp-s3-dir 和 IAM 角色 rs-role-name (在帳戶 role-account-id 中) 的 Amazon S3 URI。您還需要一個 DynamicFrame,其內容要寫入資料庫。
Amazon Redshift 連線選項參考
用於所有 AWS Glue JDBC 連線的基本連線選項,用於設定 等資訊url,user且在所有 JDBC 類型之間password保持一致。如需有關標準 JDBC 參數的詳細資訊,請參閱 JDBC 連線選項參考。
Amazon Redshift 連線類型需要一些額外的連接選項:
-
"redshiftTmpDir":(必要) 從資料庫複製時,可用來暫存臨時資料的 Amazon S3 路徑。 -
"aws_iam_role":(選用) IAM 角色的 ARN。Glue AWS 任務會將此角色傳遞給 Amazon Redshift 叢集,以授予完成任務指示所需的叢集許可。
Glue 4.0+ AWS 中可用的其他連線選項
您也可以透過 Glue AWS 連線選項,傳遞新 Amazon Redshift 連接器的選項。如需支援的連接器選項完整清單,請參閱 Amazon Redshift integration for Apache Spark (Apache Spark 的 Amazon Redshift 整合) 中的 Spark SQL 參數部分。
為方便起見,我們在此重申某些新選項:
| 名稱 | 必要 | 預設 | 描述 |
|---|---|---|---|
| autopushdown |
否 | TRUE | 擷取和分析 SQL 操作的 Spark 邏輯計畫,以套用述詞和查詢下推。這些操作會轉換成 SQL 查詢,然後在 Amazon Redshift 中執行以提高效能。 |
| autopushdown.s3_result_cache |
否 | FALSE | 快取 SQL 查詢以卸載記憶體中 Amazon S3 路徑對應的資料,因此不需要在相同的 Spark 工作階段中再次執行相同的查詢。僅在啟用 |
| unload_s3_format |
否 | PARQUET | PARQUET – 以 Parquet 格式卸載查詢結果。 TEXT – 以管道分隔的文字格式卸載查詢結果。 |
| sse_kms_key |
否 | N/A | 在 |
| extracopyoptions |
否 | N/A | 載入資料時要附加至 Amazon Redshift 請注意,由於這些選項會附加到 |
| csvnullstring (實驗性) |
否 | NULL | 使用 CSV |
這些新參數可以透過以下方式使用。
提升效能的全新選項
新的連接器引入了一些新的效能提升選項:
-
autopushdown:預設為啟用。 -
autopushdown.s3_result_cache:預設為停用。 -
unload_s3_format:預設為PARQUET。
如需有關使用這些選項的資訊,請參閱 Apache Spark 的 Amazon Redshift 整合。建議您在混合讀取和寫入操作時不要開啟
autopushdown.s3_result_cache,因為快取的結果可能包含過時的資訊。依預設,UNLOAD 命令的選項 unload_s3_format 會設定為 PARQUET,以提高效能並降低儲存成本。若要使用 UNLOAD 命令預設行為,請將選項重設為 TEXT。
新的讀取加密選項
預設情況下,從 Amazon Redshift 資料表讀取資料時,由 AWS Glue 使用之臨時資料夾中的資料會使用 SSE-S3 加密來加密。若要使用來自 AWS Key Management Service (AWS KMS) 的客戶受管金鑰來加密資料,您可以在("sse_kms_key" → kmsKey)其中設定 ksmKey 是金鑰 ID AWS KMS,而不是 3.0 AWS Glue版("extraunloadoptions" → s"ENCRYPTED KMS_KEY_ID '$kmsKey'")中的舊版設定選項。
datasource0 = glueContext.create_dynamic_frame.from_catalog( database = "database-name", table_name = "table-name", redshift_tmp_dir = args["TempDir"], additional_options = {"sse_kms_key":"<KMS_KEY_ID>"}, transformation_ctx = "datasource0" )
支援 IAM 型 JDBC URL
新的連接器支援 IAM 型 JDBC URL,因此您不需要傳入使用者/密碼或機密。透過 IAM 型 JDBC URL,連接器會使用任務執行時間角色來存取 Amazon Redshift 資料來源。
步驟 1:將下列最小必要政策附加至您的 AWS Glue 任務執行時間角色。
步驟 2:使用 IAM 型 JDBC URL (如下所示)。使用您要連線的 Amazon Redshift 使用者名稱指定新選項 DbUser。
conn_options = { // IAM-based JDBC URL "url": "jdbc:redshift:iam://<cluster name>:<region>/<database name>", "dbtable": dbtable, "redshiftTmpDir": redshiftTmpDir, "aws_iam_role": aws_iam_role, "DbUser": "<Redshift User name>" // required for IAM-based JDBC URL } redshift_write = glueContext.write_dynamic_frame.from_options( frame=dyf, connection_type="redshift", connection_options=conn_options ) redshift_read = glueContext.create_dynamic_frame.from_options( connection_type="redshift", connection_options=conn_options )
注意
DynamicFrame 目前只支援 GlueContext.create_dynamic_frame.from_options 工作流程中具有
DbUser 的 IAM 型 JDBC URL。
從 AWS Glue 3.0 版本遷移至第 4.0 版
在 AWS Glue 4.0 中,ETL 任務可存取新的 Amazon Redshift Spark 連接器和具有不同選項和組態的新 JDBC 驅動程式。新 Amazon Redshift 連接器和驅動程式在寫入時考量效能,並維持資料的交易一致性。這些產品會記錄在 Amazon Redshift 文件中。如需詳細資訊,請參閱:
資料表/欄名稱和識別符限制
新的 Amazon Redshift Spark 連接器和驅動程式對 Redshift 資料表名稱的要求更加嚴格。如需詳細資訊,請參閱 Names and identifiers (名稱和識別符) 以定義您的 Amazon Redshift 資料表名稱。任務書籤工作流程可能無法使用不符合規則和具有特定字元 (例如空格) 的資料表名稱。
如果舊版資料表名稱不符合名稱和識別符規則,並且看到書籤問題 (任務會重新處理舊版 Amazon Redshift 資料表資料),建議您重新命名資料表名稱。如需詳細資訊,請參閱 ALTER TABLE 範例。
Dataframe 中的預設 tempformat 變更
AWS Glue 3.0 版 Spark 連接器在寫入 Amazon Redshift 時將 tempformat 預設為 CSV。為了保持一致,在 AWS Glue 3.0 版本中,
DynamicFrame 仍然將 tempformat 預設為使用 CSV。如果之前已將 Spark Dataframe API 直接與 Amazon Redshift Spark 連接器搭配使用,您可以在 DataframeReader/Writer 選項中將 tempformat 明確設定為 CSV。否則,tempformat 會在新 Spark 連接器中預設為 AVRO。
行為變更:將 Amazon Redshift 資料類型 REAL 映射到 Spark 資料類型 FLOAT 而不是 DOUBLE
在 AWS Glue 3.0 版本中,Amazon Redshift REAL 會轉換為 Spark
DOUBLE 類型。新的 Amazon Redshift Spark 連接器已經更新行為,以便 Amazon Redshift
REAL 類型轉換為 Spark FLOAT 類型,並轉換回來。如果您仍有希望將 Amazon Redshift REAL 類型映射至 Spark DOUBLE 類型的舊版使用案例,則可以使用下列因應措施:
-
對於
DynamicFrame,將Float類型映射至具有DynamicFrame.ApplyMapping的Double類型。對於Dataframe,您需要使用cast。
程式碼範例:
dyf_cast = dyf.apply_mapping([('a', 'long', 'a', 'long'), ('b', 'float', 'b', 'double')])
處理 VARBYTE 資料類型
使用 AWS Glue 3.0 和 Amazon Redshift 資料類型時, AWS Glue 3.0 會將 Amazon Redshift 轉換為 VARBYTE Spark STRING類型。不過,最新的 Amazon Redshift Spark 連接器不支援 VARBYTE資料類型。若要解決此限制,您可以建立 Redshift 檢視,將VARBYTE資料欄轉換為支援的資料類型。然後,使用新的連接器從此檢視載入資料,而不是原始資料表,這可確保相容性,同時保持對VARBYTE資料的存取。
Redshift 查詢的範例:
CREATE VIEWview_nameAS SELECT FROM_VARBYTE(varbyte_column, 'hex') FROMtable_name
