本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
匯出支援 AWS 雲端 目的地的組態
使用者定義的 Greengrass 元件會在 Stream Manager SDK StreamManagerClient中使用 與串流管理員互動。當元件建立串流或更新串流時,它會傳遞代表串流屬性的MessageStreamDefinition物件,包括匯出定義。ExportDefinition 物件包含為串流定義的匯出組態。串流管理員使用這些匯出組態來判斷匯出串流的位置和方式。
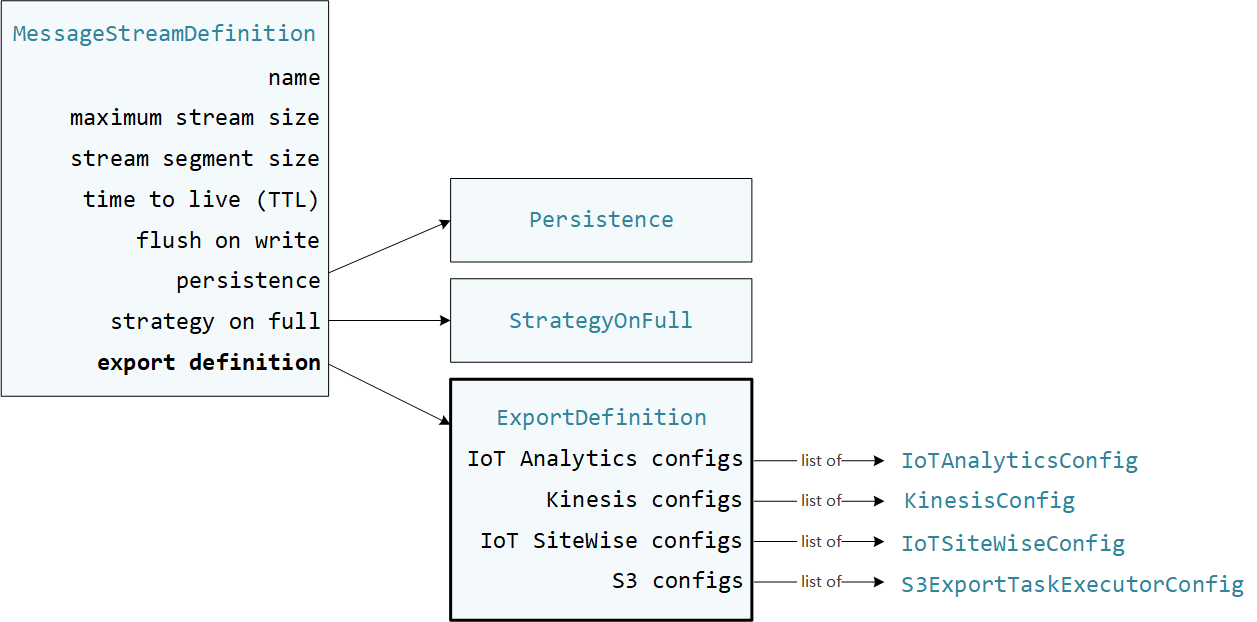
您可以在串流上定義零或多個匯出組態,包括單一目的地類型的多個匯出組態。例如,您可以將串流匯出至兩個 AWS IoT Analytics 頻道和一個 Kinesis 資料串流。
對於失敗的匯出嘗試,串流管理員會持續重試 AWS 雲端 以最多五分鐘的間隔將資料匯出至 。重試嘗試次數沒有上限。
注意
StreamManagerClient 也提供目標目的地,可用來將串流匯出至 HTTP 伺服器。此目標僅供測試之用。它不穩定或不支援在生產環境中使用。
您需負責維護這些 AWS 雲端 資源。
AWS IoT Analytics 頻道
串流管理員支援自動匯出至 AWS IoT Analytics。 AWS IoT Analytics 可讓您對資料執行進階分析,以協助做出商業決策並改善機器學習模型。如需詳細資訊,請參閱AWS IoT Analytics 《 使用者指南》中的什麼是 AWS IoT Analytics?。
在 Stream Manager SDK 中,您的 Greengrass 元件會使用 IoTAnalyticsConfig 來定義此目的地類型的匯出組態。如需詳細資訊,請參閱目標語言的 SDK 參考:
-
Python SDK 中的 IoTAnalyticsConfig
-
Java 開發套件中的 IoTAnalyticsConfig
-
Node.js SDK 中的 IoTAnalyticsConfig
要求
此匯出目的地有下列需求:
-
中的目標頻道 AWS IoT Analytics 必須與 Greengrass 核心裝置位於相同的 AWS 帳戶 和 AWS 區域 中。
-
必須授權核心裝置與 AWS 服務互動允許 以頻道為目標的
iotanalytics:BatchPutMessage許可。例如:您可以使用萬用字元
*命名機制,授予對資源的精細或條件式存取。如需詳細資訊,請參閱《IAM 使用者指南》中的新增和移除 IAM 政策。
匯出至 AWS IoT Analytics
若要建立匯出至 的串流 AWS IoT Analytics,您的 Greengrass 元件會建立包含一或多個IoTAnalyticsConfig物件的匯出定義串流。此物件會定義匯出設定,例如目標頻道、批次大小、批次間隔和優先順序。
當您的 Greengrass 元件從裝置接收資料時,它們會將包含資料 Blob 的訊息附加到目標串流。
然後,串流管理員會根據串流匯出組態中定義的批次設定和優先順序匯出資料。
Amazon Kinesis 資料串流
串流管理員支援自動匯出至 Amazon Kinesis Data Streams。Kinesis Data Streams 通常用於彙總大量資料,並將其載入資料倉儲或 MapReduce 叢集。如需詳細資訊,請參閱《Amazon Kinesis 開發人員指南》中的什麼是 Amazon Kinesis Data Streams?。 Amazon Kinesis
在 Stream Manager SDK 中,您的 Greengrass 元件會使用 KinesisConfig 來定義此目的地類型的匯出組態。如需詳細資訊,請參閱目標語言的 SDK 參考:
-
Python SDK 中的 KinesisConfig
-
Java 開發套件中的 KinesisConfig
-
Node.js SDK 中的 KinesisConfig
要求
此匯出目的地有下列需求:
-
Kinesis Data Streams 中的目標串流必須與 Greengrass 核心裝置位於相同的 AWS 帳戶 和 AWS 區域 中。
-
(建議) 串流管理員 v2.2.1 可改善將串流匯出至 Kinesis Data Streams 目的地的效能。若要使用此最新版本的改進功能,請將串流管理員元件升級至 v2.2.1,並使用 Greengrass 權杖交換角色中的
kinesis:ListShards政策。 -
必須授權核心裝置與 AWS 服務互動允許 以資料串流為目標的
kinesis:PutRecords許可。例如:您可以使用萬用字元
*命名機制,授予對資源的精細或條件式存取。如需詳細資訊,請參閱《IAM 使用者指南》中的新增和移除 IAM 政策。
匯出至 Kinesis Data Streams
若要建立匯出至 Kinesis Data Streams 的串流,您的 Greengrass 元件會建立包含一或多個KinesisConfig物件的匯出定義串流。此物件會定義匯出設定,例如目標資料串流、批次大小、批次間隔和優先順序。
當您的 Greengrass 元件從裝置接收資料時,它們會將包含資料 Blob 的訊息附加到目標串流。然後,串流管理員會根據串流匯出組態中定義的批次設定和優先順序匯出資料。
串流管理員會為每個上傳至 Amazon Kinesis 的記錄產生唯一的隨機 UUID 做為分割區索引鍵。
AWS IoT SiteWise 資產屬性
串流管理員支援自動匯出至 AWS IoT SiteWise。 AWS IoT SiteWise 可讓您大規模收集、組織和分析工業設備的資料。如需詳細資訊,請參閱AWS IoT SiteWise 《 使用者指南》中的什麼是 AWS IoT SiteWise?。
在 Stream Manager SDK 中,您的 Greengrass 元件會使用 IoTSiteWiseConfig 來定義此目的地類型的匯出組態。如需詳細資訊,請參閱目標語言的 SDK 參考:
-
Python SDK 中的 IoTSiteWiseConfig
-
Java 開發套件中的 IoTSiteWiseConfig
-
Node.js SDK 中的 IoTSiteWiseConfig
注意
AWS 也提供 AWS IoT SiteWise 元件,提供預先建置的解決方案,可讓您用來從 OPC-UA 來源串流資料。如需詳細資訊,請參閱IoT SiteWise OPC UA 收集器。
需求
此匯出目的地有下列需求:
-
中的目標資產屬性 AWS IoT SiteWise 必須與 Greengrass 核心裝置位於相同的 AWS 帳戶 和 AWS 區域 中。
注意
如需 AWS 區域 AWS IoT SiteWise 支援的 清單,請參閱《 AWS 一般參考》中的AWS IoT SiteWise 端點和配額。
-
必須授權核心裝置與 AWS 服務互動允許 以資產屬性為目標的
iotsitewise:BatchPutAssetPropertyValue許可。下列範例政策使用iotsitewise:assetHierarchyPath條件索引鍵來授予目標根資產及其子資產的存取權。您可以從Condition政策中移除 ,以允許存取所有 AWS IoT SiteWise 資產或指定個別資產ARNs。您可以使用萬用字元
*命名機制,授予對資源的精細或條件式存取。如需詳細資訊,請參閱《IAM 使用者指南》中的新增和移除 IAM 政策。如需重要的安全性資訊,請參閱AWS IoT SiteWise 《 使用者指南》中的 BatchPutAssetPropertyValue 授權。
匯出至 AWS IoT SiteWise
若要建立匯出至 的串流 AWS IoT SiteWise,您的 Greengrass 元件會建立包含一或多個IoTSiteWiseConfig物件的匯出定義串流。此物件會定義匯出設定,例如批次大小、批次間隔和優先順序。
當您的 Greengrass 元件從裝置接收資產屬性資料時,它們會將包含資料的訊息附加到目標串流。訊息是 JSON 序列化PutAssetPropertyValueEntry物件,其中包含一或多個資產屬性的屬性值。如需詳細資訊,請參閱附加訊息以取得 AWS IoT SiteWise 匯出目的地。
注意
當您傳送資料至 時 AWS IoT SiteWise,您的資料必須符合 BatchPutAssetPropertyValue動作的要求。如需詳細資訊,請參閱《AWS IoT SiteWise API 參考》中的 BatchPutAssetPropertyValue。
然後,串流管理員會根據串流匯出組態中定義的批次設定和優先順序匯出資料。
您可以調整串流管理員設定和 Greengrass 元件邏輯,以設計匯出策略。例如:
-
對於近乎即時的匯出,請設定低批次大小和間隔設定,並在接收資料時將資料附加至串流。
-
為了最佳化批次處理、減輕頻寬限制或將成本降至最低,您的 Greengrass 元件可以在將資料附加至串流之前,將單一資產屬性收到的timestamp-quality-value(TQV) 資料點合併。一種策略是在一個訊息中批次處理最多 10 個不同的屬性資產組合或屬性別名的項目,而不是為相同的屬性傳送多個項目。這有助於串流管理員保持在AWS IoT SiteWise 配額內。
Amazon S3 物件
串流管理員支援自動匯出至 Amazon S3。您可以使用 Amazon S3 來存放和擷取大量資料。如需詳細資訊,請參閱《Amazon Simple Storage Service 開發人員指南》中的什麼是 Amazon S3?。
在 Stream Manager SDK 中,您的 Greengrass 元件會使用 S3ExportTaskExecutorConfig 來定義此目的地類型的匯出組態。如需詳細資訊,請參閱目標語言的 SDK 參考:
-
Python SDK 中的 S3ExportTaskExecutorConfig
-
Java 開發套件中的 S3ExportTaskExecutorConfig
-
Node.js SDK 中的 S3ExportTaskExecutorConfig
要求
此匯出目的地有下列需求:
-
目標 Amazon S3 儲存貯體必須與 Greengrass 核心裝置 AWS 帳戶 位於相同的 中。
-
如果在 Greengrass 容器模式下執行的 Lambda 函數將輸入檔案寫入輸入檔案目錄,您必須將目錄掛載為具有寫入許可的容器中的磁碟區。這可確保檔案寫入根檔案系統,並在容器外部執行的串流管理員元件可見。
-
如果 Docker 容器元件將輸入檔案寫入輸入檔案目錄,您必須將目錄掛載為具有寫入許可的容器中的磁碟區。這可確保檔案寫入根檔案系統,並在容器外部執行的串流管理員元件可見。
-
必須授權核心裝置與 AWS 服務互動允許目標儲存貯體的下列許可。例如:
您可以使用萬用字元
*命名機制,授予對資源的精細或條件式存取。如需詳細資訊,請參閱《IAM 使用者指南》中的新增和移除 IAM 政策。
匯出至 Amazon S3
若要建立匯出至 Amazon S3 的串流,您的 Greengrass 元件會使用 S3ExportTaskExecutorConfig 物件來設定匯出政策。政策會定義匯出設定,例如分段上傳閾值和優先順序。對於 Amazon S3 匯出,串流管理員會上傳從核心裝置上的本機檔案讀取的資料。若要啟動上傳,您的 Greengrass 元件會將匯出任務附加至目標串流。匯出任務包含輸入檔案和目標 Amazon S3 物件的相關資訊。串流管理員會以任務附加至串流的順序執行任務。
注意
目標儲存貯體必須已存在於您的 中 AWS 帳戶。如果指定金鑰的物件不存在,串流管理員會為您建立物件。
串流管理員使用分段上傳閾值屬性、最小分段大小設定和輸入檔案的大小來決定如何上傳資料。分段上傳閾值必須大於或等於最小分段大小。如果您想要平行上傳資料,您可以建立多個串流。
指定目標 Amazon S3 物件的金鑰可以在!{timestamp:預留位置中包含有效的 Java DateTimeFormattervalue}my-key/2020/12/31/data.txt。
my-key/!{timestamp:YYYY}/!{timestamp:MM}/!{timestamp:dd}/data.txt
注意
如果您想要監控串流的匯出狀態,請先建立狀態串流,然後將匯出串流設定為使用它。如需詳細資訊,請參閱監控匯出任務。
管理輸入資料
您可以編寫程式碼,讓 IoT 應用程式用來管理輸入資料的生命週期。下列工作流程範例示範如何使用 Greengrass 元件來管理此資料。
-
本機程序會從裝置或周邊接收資料,然後將資料寫入核心裝置上的目錄中的檔案。這些是串流管理員的輸入檔案。
-
Greengrass 元件會掃描目錄,並在建立新檔案時將匯出任務附加至目標串流。任務是 JSON 序列化
S3ExportTaskDefinition物件,可指定輸入檔案的 URL、目標 Amazon S3 儲存貯體和金鑰,以及選用的使用者中繼資料。 -
串流管理員會讀取輸入檔案,並依附加任務的順序將資料匯出至 Amazon S3。目標儲存貯體必須已存在於您的 中 AWS 帳戶。如果指定金鑰的物件不存在,串流管理員會為您建立物件。
-
Greengrass 元件會從狀態串流讀取訊息,以監控匯出狀態。匯出任務完成後,Greengrass 元件可以刪除對應的輸入檔案。如需詳細資訊,請參閱監控匯出任務。
監控匯出任務
您可以編寫程式碼,讓 IoT 應用程式用來監控 Amazon S3 匯出的狀態。您的 Greengrass 元件必須建立狀態串流,然後將匯出串流設定為將狀態更新寫入狀態串流。單一狀態串流可以從匯出至 Amazon S3 的多個串流接收狀態更新。
首先,建立要用作狀態串流的串流。您可以設定串流的大小和保留政策,以控制狀態訊息的生命週期。例如:
-
Memory如果您不想儲存狀態訊息,請將Persistence設定為 。 -
StrategyOnFull設定為 ,OverwriteOldestData以免遺失新的狀態訊息。
然後,建立或更新匯出串流以使用狀態串流。具體而言,請設定串流S3ExportTaskExecutorConfig匯出組態的狀態組態屬性。此設定會告知串流管理員將有關匯出任務的狀態訊息寫入狀態串流。在 StatusConfig 物件中,指定狀態串流的名稱和詳細程度。下列支援的值範圍從最詳細 (ERROR) 到最詳細 (TRACE)。預設值為 INFO。
-
ERROR -
WARN -
INFO -
DEBUG -
TRACE
下列工作流程範例顯示 Greengrass 元件如何使用狀態串流來監控匯出狀態。
-
如先前工作流程所述,Greengrass 元件會將匯出任務附加至設定為將有關匯出任務的狀態訊息寫入狀態串流的串流。附加操作會傳回代表任務 ID 的序號。
-
Greengrass 元件會從狀態串流循序讀取訊息,然後根據串流名稱和任務 ID 或根據訊息內容的匯出任務屬性來篩選訊息。例如,Greengrass 元件可以依匯出任務的輸入檔案 URL 進行篩選,該 URL 由訊息內容中的
S3ExportTaskDefinition物件表示。下列狀態碼表示匯出任務已達到已完成狀態:
-
Success。 上傳已成功完成。 -
Failure。 串流管理員遇到錯誤,例如,指定的儲存貯體不存在。解決問題後,您可以再次將匯出任務附加至串流。 -
Canceled。 任務已停止,因為串流或匯出定義已刪除,或任務的time-to-live(TTL) 期間已過期。
注意
任務也可能的狀態為
InProgress或Warning。當事件傳回不會影響任務執行的錯誤時,串流管理員會發出警告。例如,無法清除部分上傳會傳回警告。 -
-
匯出任務完成後,Greengrass 元件可以刪除對應的輸入檔案。
下列範例顯示 Greengrass 元件如何讀取和處理狀態訊息。
