本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
Amazon Keyspaces:運作方式
Amazon Keyspaces 消除管理 Cassandra 的管理開銷。若要了解原因,從 Cassandra 架構開始,然後將其與 Amazon Keyspaces 進行比較會很有幫助。
高階架構:Apache Cassandra 與 Amazon Keyspaces
傳統 Apache Cassandra 部署在由一或多個節點組成的叢集中。您負責管理每個節點,並在叢集擴展時新增和移除節點。
用戶端程式透過連線至其中一個節點並發出 Cassandra 查詢語言 (CQL) 陳述式來存取 Cassandra。CQL 類似於 SQL,這是關聯式資料庫中使用的常用語言。即使 Cassandra 不是關聯式資料庫,CQL 仍提供熟悉的界面,用於查詢和操作 Cassandra 中的資料。
下圖顯示簡單的 Apache Cassandra 叢集,由四個節點組成。
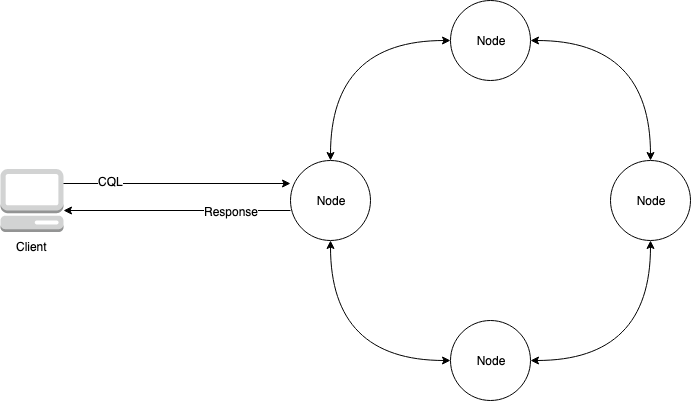
生產 Cassandra 部署可能包含數百個節點,在一個或多個實體資料中心的數百部實體電腦上執行。這可能會對需要佈建、修補和管理伺服器的應用程式開發人員造成操作負擔,以及安裝、維護和操作軟體。
使用 Amazon Keyspaces (適用於 Apache Cassandra),您不需要佈建、修補或管理伺服器,因此您可以專注於建置更好的應用程式。Amazon Keyspaces 為讀取和寫入提供兩種輸送量容量模式:隨需和佈建。您可以選擇資料表的輸送量容量模式,根據工作負載的可預測性和可變性來最佳化讀取和寫入的價格。
使用隨需模式時,您只需支付應用程式實際執行的讀取和寫入費用。您不需要事先指定資料表的輸送量容量。Amazon Keyspaces 會在應用程式流量上升或下降時,幾乎立即容納您的應用程式流量,使其成為具有不可預測流量之應用程式的理想選擇。
如果您有可預測的應用程式流量,佈建的容量模式可協助您最佳化輸送量價格,並可事先預測資料表的容量需求。使用佈建容量模式時,您可以指定您預期應用程式執行的每秒讀取和寫入次數。您可以啟用自動擴展,自動增加和減少資料表的佈建容量。
當您進一步了解工作負載的流量模式時,或如果您預期流量暴增,例如您預期會驅動大量資料表流量的主要事件,您可以每天變更一次資料表的容量模式。如需讀取和寫入容量佈建的詳細資訊,請參閱在 Amazon Keyspaces 中設定讀取/寫入容量模式。
Amazon Keyspaces (適用於 Apache Cassandra) 會將資料的三個副本存放在多個可用區域中
下圖顯示 Amazon Keyspaces 的架構。
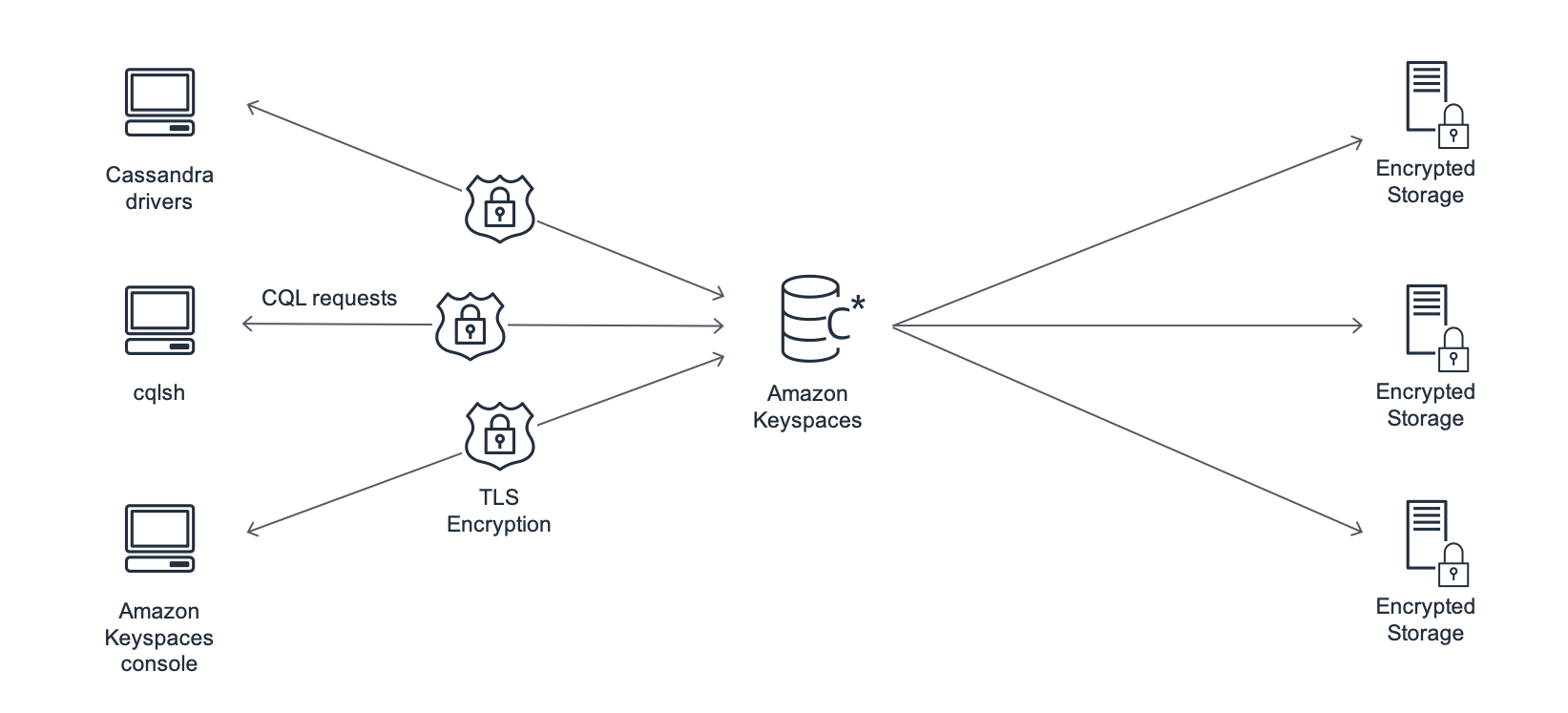
用戶端程式透過連線至預定端點 (主機名稱和連接埠號碼) 並發出 CQL 陳述式來存取 Amazon Keyspaces。如需可用端點的清單,請參閱 Amazon Keyspaces 的服務端點。
Cassandra 資料模型
如何為業務案例建立資料模型,對於從 Amazon Keyspaces 實現最佳效能至關重要。不良的資料模型可能會大幅降低效能。
即使 CQL 看起來與 SQL 類似,Cassandra 和關聯式資料庫的後端也非常不同,必須以不同的方式處理。以下是一些較重要的問題需要考慮:
- 儲存
-
您可以在資料表中視覺化 Cassandra 資料,其中每一列代表記錄,每一欄都代表該記錄內的欄位。
- 資料表設計:先查詢
-
CQL
JOIN中沒有 。因此,您應該設計具有資料形狀的資料表,以及如何針對業務使用案例存取它。這可能會導致重複資料的去標準化。您應該專門針對特定存取模式設計每個資料表。 - 分區
-
您的資料會存放在磁碟的分割區中。資料存放於 中的分割區數量,以及其在分割區間的分佈方式,取決於您的分割區索引鍵。如何定義分割區索引鍵可能會對查詢的效能產生重大影響。如需最佳實務做法,請參閱「如何在 Amazon Keyspaces 中有效使用分割區索引鍵」。
- 主索引鍵
-
在 Cassandra 中,資料會儲存為索引鍵/值對。每個 Cassandra 資料表都必須有一個主索引鍵,這是資料表中每一列的唯一索引鍵。主索引鍵是必要分割區索引鍵和選用叢集資料欄的複合。包含主索引鍵的資料在資料表中的所有記錄中必須是唯一的。
-
分割區索引鍵 – 需要主索引鍵的分割區索引鍵部分,並決定資料存放於叢集的哪個分割區。分割區索引鍵可以是單一資料欄,也可以是由兩個或多個資料欄組成的複合值。如果單一資料欄分割區索引鍵會導致單一分割區或具有大部分資料的極少分割區,因此包含大部分磁碟 I/O 操作,則您會使用複合分割區索引鍵。
-
叢集資料欄 – 主索引鍵的選用叢集資料欄部分會決定如何在每個分割區中叢集和排序資料。如果您在主索引鍵中包含叢集資料欄,叢集資料欄可以有一或多個資料欄。如果叢集資料欄中有多個資料欄,排序順序取決於從左到右在叢集資料欄中列出的資料欄順序。
-
如需 NoSQL 設計和 Amazon Keyspaces 的詳細資訊,請參閱 NoSQL 設計的主要差異和設計原則。如需 Amazon Keyspaces 和資料建模的詳細資訊,請參閱 資料建模最佳實務:設計資料模型的建議。
從應用程式存取 Amazon Keyspaces
Amazon Keyspaces (適用於 Apache Cassandra) 實作 Apache Cassandra 查詢語言 (CQL) API,因此您可以使用您已使用的 CQL 和 Cassandra 驅動程式。更新您的應用程式就像更新您的 Cassandra 驅動程式或cqlsh組態以指向 Amazon Keyspaces 服務端點一樣簡單。如需所需登入資料的詳細資訊,請參閱 建立和設定 Amazon Keyspaces 的 AWS 登入資料。
注意
為了協助您開始使用,您可以在 GitHub
請考慮下列 Python 程式,此程式會連線至 Cassandra 叢集並查詢資料表。
from cassandra.cluster import Cluster #TLS/SSL configuration goes here ksp = 'MyKeyspace' tbl = 'WeatherData' cluster = Cluster(['NNN.NNN.NNN.NNN'], port=NNNN) session = cluster.connect(ksp) session.execute('USE ' + ksp) rows = session.execute('SELECT * FROM ' + tbl) for row in rows: print(row)
若要針對 Amazon Keyspaces 執行相同的程式,您需要:
-
新增叢集端點和連接埠:例如,主機可以替換為服務端點,例如
cassandra.us-east-2.amazonaws.com和連接埠號碼為:9142。 -
新增 TLS/SSL 組態:如需使用 Cassandra 用戶端 Python 驅動程式新增 TLS/SSL 組態以連線至 Amazon Keyspaces 的詳細資訊,請參閱 使用 Cassandra Python 用戶端驅動程式以程式設計方式存取 Amazon Keyspaces。
