在仔細考慮之後,我們決定停止 Amazon Kinesis Data Analytics for SQL 應用程式:
1. 從 2025 年 9 月 1 日起,我們不會為 Amazon Kinesis Data Analytics for SQL 應用程式提供任何錯誤修正,因為考慮到即將終止,我們將對其提供有限的支援。
2. 從 2025 年 10 月 15 日起,您將無法建立新的 Kinesis Data Analytics for SQL 應用程式。
3. 我們將自 2026 年 1 月 27 日起刪除您的應用程式。您將無法啟動或操作 Amazon Kinesis Data Analytics for SQL 應用程式。從那時起,Amazon Kinesis Data Analytics for SQL 將不再提供支援。如需詳細資訊,請參閱Amazon Kinesis Data Analytics for SQL 應用程式終止。
本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
遷移至 Managed Service for Apache Flink Studio 範例
在仔細考慮之後,我們決定停止 Amazon Kinesis Data Analytics for SQL 應用程式。為了協助您規劃和遷移 Amazon Kinesis Data Analytics for SQL 應用程式,我們將在 15 個月內逐漸停止該方案。這些是需要注意的重要日期,2025 年 9 月 1 日、2025 年 10 月 15 日和 2026 年 1 月 27 日。
-
從 2025 年 9 月 1 日起,我們不會為 Amazon Kinesis Data Analytics for SQL 應用程式提供任何錯誤修正,因為考慮到即將終止,我們將對其提供有限的支援。
-
從 2025 年 10 月 15 日起,您將無法建立新的 Amazon Kinesis Data Analytics for SQL 應用程式。
-
我們將自 2026 年 1 月 27 日起刪除您的應用程式。您將無法啟動或操作 Amazon Kinesis Data Analytics for SQL 應用程式。從那時起,Amazon Kinesis Data Analytics for SQL 應用程式將不再提供支援。如需詳細資訊,請參閱 Amazon Kinesis Data Analytics for SQL 應用程式終止。
我們建議您使用 Amazon Managed Service for Apache Flink。它結合了易於使用與進階分析功能,可讓您在幾分鐘內建置串流處理應用程式。
本節提供程式碼和架構範例,協助您將 Amazon Kinesis Data Analytics for SQL 應用程式工作負載移至 Managed Service for Apache Flink。
如需詳細資訊,請參閱此AWS 部落格文章:從 Amazon Kinesis Data Analytics for SQL 應用程式遷移至 Managed Service for Apache Flink Studio
若要將您的工作負載遷移至 Managed Service for Apache Flink Studio 或 Managed Service for Apache Flink,本節提供可用於常見使用案例的查詢翻譯。
探索這些範例之前,建議您先檢閱搭配使用 Studio 筆記本與 Managed Service for Apache Flink。
在 Managed Service for Apache Flink Studio 中重建 Kinesis Data Analytics for SQL 查詢
下列選項會將常用 SQL 型 Kinesis Data Analytics 應用程式查詢的轉譯提供給 Managed Service for Apache Flink Studio。
如果您想要將使用隨機分割森林的工作負載從 Kinesis Analytics for SQL 移動到 Managed Service for Apache Flink,此AWS 部落格文章
如需完整的教學課程,請參閱 Converting-KDASQL-KDAStudio/
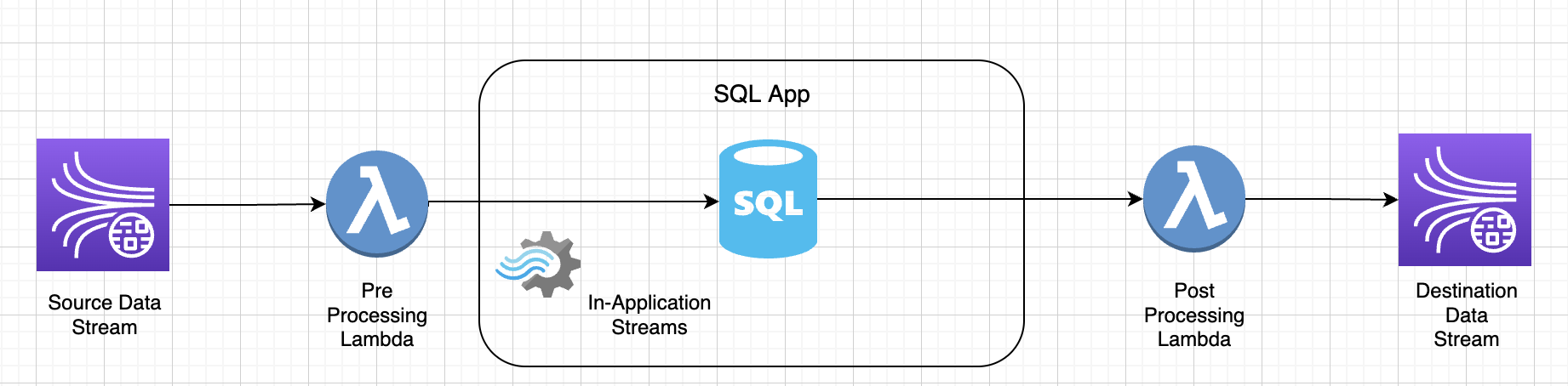
在下列練習中,您將變更資料流程來使用 Amazon Managed Service for Apache Flink Studio。這也意味著從 Amazon Kinesis Data Firehose 切換到 Amazon Kinesis Data Streams。
首先,我們分享一個典型的 KDA-SQL 架構,接著展示如何使用 Amazon Managed Service for Apache Flink Studio 和 Amazon Kinesis Data Streams.替換此架構。或者,您也可以在此處
Amazon Kinesis Data Analytics-SQL 和 Amazon Kinesis Data Firehose
以下是 Amazon Kinesis Data Analytics SQL 架構流程:
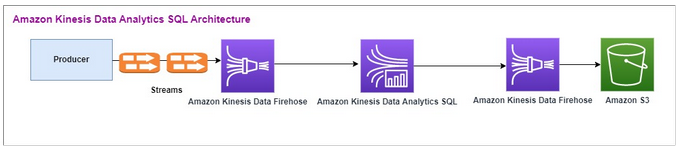
我們首先檢查傳統 Amazon Kinesis Data Analytics-SQL 和 Amazon Kinesis Data Firehose 的設置。此使用案例是交易市場,其中包括股票代號和價格在內的交易資料會從外部來源串流至 Amazon Kinesis 系統。Amazon Kinesis Data Analytics for SQL 使用輸入串流來執行輪轉時段等視窗查詢,以判斷每個股票代號在一分鐘時段內的交易量和 max、 min和 average交易價格。
Amazon Kinesis Data Analytics-SQL 已準備好從 Amazon Kinesis Data Firehose API 擷取資料。處理完畢後,Amazon Kinesis Data Analytics-SQL 會將處理過的資料傳送到另一個 Amazon Kinesis Data Firehose,然後將輸出儲存在 Amazon S3 儲存貯體中。
在這種情況下,您可以使用 Amazon Kinesis 資料產生器。Amazon Kinesis 資料產生器可讓您將測試資料傳送到 Amazon Kinesis Data Streams 或 Amazon Kinesis Data Firehose 交付串流。若要開始使用,請依照此處
執行 AWS CloudFormation 範本後,輸出區段將提供 Amazon Kinesis Data Generator URL。使用您在此處
以下是使用 Amazon Kinesis 資料產生器的範例承載。資料產生器之目標為 Amazon Kinesis Firehose 的輸入串流,以持續串流資料。Amazon Kinesis SDK 用戶端也可以從其他生產者傳送資料。
2023-02-17 09:28:07.763,"AAPL",5032023-02-17 09:28:07.763, "AMZN",3352023-02-17 09:28:07.763, "GOOGL",1852023-02-17 09:28:07.763, "AAPL",11162023-02-17 09:28:07.763, "GOOGL",1582
以下 JSON 用於生成一系列隨機的交易時間和日期,股票代號和股票價格:
date.now(YYYY-MM-DD HH:mm:ss.SSS), "random.arrayElement(["AAPL","AMZN","MSFT","META","GOOGL"])", random.number(2000)
選擇傳送資料後,生成器將開始傳送模擬資料。
外部系統會將資料串流到 Amazon Kinesis Data Firehose。使用 Amazon Kinesis Data Analytics for SQL 應用程式,您可以用標準 SQL 來分析串流資料。此服務可讓您針對串流來源撰寫和執行 SQL 程式碼,以執行時間序列分析、饋送即時儀表板,以及建立即時指標。Amazon Kinesis Data Analytics for SQL 應用程式可以從輸入串流上的 SQL 查詢建立目標串流,然後將目標串流傳送到另一個 Amazon Kinesis Data Firehose。目的地 Amazon Kinesis Data Firehose 可以將分析資料傳送到 Amazon S3 做為最終狀態。
Amazon Kinesis Data Analytics-SQL 舊版程式碼的基礎,是 SQL 標準的延伸模組。
在 Amazon Kinesis Data Analytics-SQL 中使用以下查詢。首先建立查詢輸出的目標串流。然後,您可以使用 PUMP Amazon Kinesis Data Analytics 儲存庫物件 (SQL 標準的延伸模組),提供持續執行的 INSERT INTO stream SELECT ... FROM 查詢功能,進而讓查詢結果持續輸入到具名串流中。
CREATE OR REPLACE STREAM "DESTINATION_SQL_STREAM" (EVENT_TIME TIMESTAMP, INGEST_TIME TIMESTAMP, TICKER VARCHAR(16), VOLUME BIGINT, AVG_PRICE DOUBLE, MIN_PRICE DOUBLE, MAX_PRICE DOUBLE); CREATE OR REPLACE PUMP "STREAM_PUMP" AS INSERT INTO "DESTINATION_SQL_STREAM" SELECT STREAM STEP("SOURCE_SQL_STREAM_001"."tradeTimestamp" BY INTERVAL '60' SECOND) AS EVENT_TIME, STEP("SOURCE_SQL_STREAM_001".ROWTIME BY INTERVAL '60' SECOND) AS "STREAM_INGEST_TIME", "ticker", COUNT(*) AS VOLUME, AVG("tradePrice") AS AVG_PRICE, MIN("tradePrice") AS MIN_PRICE, MAX("tradePrice") AS MAX_PRICEFROM "SOURCE_SQL_STREAM_001" GROUP BY "ticker", STEP("SOURCE_SQL_STREAM_001".ROWTIME BY INTERVAL '60' SECOND), STEP("SOURCE_SQL_STREAM_001"."tradeTimestamp" BY INTERVAL '60' SECOND);
上述 SQL 使用兩個時段 – tradeTimestamp 來自傳入的串流承載,ROWTIME.tradeTimestamp也稱為 Event Time或 client-side time。需要在分析中偏好使用此時間,因其為事件發生的時間。不過,許多事件來源 (例如行動電話和 Web 用戶端) 沒有可靠的時鐘,這可能會導致不正確的時間。此外,連線問題可能會導致串流上的記錄顯示順序與事件發生的順序不相同。
應用程式內串流也包含一個名為 ROWTIME 的特殊資料欄。當 Amazon Kinesis Data Analytics 在第一個應用程式內串流中插入資料列時,會儲存時間戳記。 ROWTIME 指的是 Amazon Kinesis Data Analytics 從串流來源讀取後,將記錄插入第一個應用程式內串流的時間戳記。接著整個應用程式中皆會保留此 ROWTIME 值。
SQL 會決定 60 秒間隔內的刻度計數為 volume、max、 min和 average 價格。
在時間類型的視窗查詢中,使用其中的任一個時間都有優點和缺點。選擇其中一個或多個時間,與根據使用案例情境來處理相關缺點的策略。
雙視窗策略使用兩個時間類型,包含 ROWTIME 與另一個其他時間,如事件時間。
-
將
ROWTIME當作第一個視窗,此視窗可控制查詢發出結果的頻率,如下列範例所示。這並非邏輯時間。 -
把其中一個其他時間當作邏輯時間,即您想要連結到分析的時間 此時間表示事件發生的時間。在下面的例子中,分析目標是按股票代號對記錄進行分組和返回計數。
Amazon Managed Service for Apache Flink Studio
在更新的架構中,您可以使用 Amazon Kinesis Data Streams 取代 Amazon Kinesis Data Firehose。Amazon Kinesis Data Analytics for SQL 應用程式已由 Amazon Managed Service for Apache Flink Studio 取代。Apache Flink 程式碼會在 Apache Zeppelin 筆記本中交互運行。Amazon Managed Service for Apache Flink Studio 會將彙總的交易資料傳送到 Amazon S3 儲存貯體來儲存。步驟如下所示:
此為 Amazon Managed Service for Apache Flink Studio 的架構流程:

建立 Kinesis Data Stream
使用主控台建立資料串流
登入 AWS Management Console 並開啟位於 https://https://console.aws.amazon.com/kinesis
的 Kinesis 主控台。 -
在導覽列中,展開區域選擇工具,然後選擇一個區域。
-
選擇 建立資料串流。
-
在建立 Kinesis 串流頁面上,輸入資料串流的名稱,然後接受預設的隨需容量模式。
在隨需模式下,您可以選擇建立 Kinesis 串流來建立資料串流。
建立串流時,在 Kinesis 串流頁面上,串流的狀態會是正在建立。當串流就緒可供使用後,其狀態將變成作用中。
-
選擇串流名稱。串流詳細資訊頁面會顯示串流組態的摘要以及監控資訊。
-
在 Amazon Kinesis 資料產生器中,將串流/交付串流變更為新的 Amazon Kinesis Data Streams:TRADE_SOURCE_STREAM。
JSON 和承載會與您用於 Amazon Kinesis Data Analytics-SQL 的相同。使用 Amazon Kinesis 資料產生器產生一些交易承載資料範例,並針對本練習將 TRADE_SOURCE_STREAM 資料串流設為目標:
{{date.now(YYYY-MM-DD HH:mm:ss.SSS)}}, "{{random.arrayElement(["AAPL","AMZN","MSFT","META","GOOGL"])}}", {{random.number(2000)}} -
AWS Management Console 前往 Managed Service for Apache Flink,然後選擇建立應用程式。
-
在左邊的導覽窗格中,選擇 Studio 筆記本,然後選擇建立 Studio 筆記本。
-
輸入 Studio 筆記本的名稱。
-
在 AWS Glue 資料庫中,提供現有的資料 AWS Glue 資料庫,以定義您的來源和目的地之中繼資料。如果您沒有 AWS Glue 資料庫,請選擇建立並執行下列動作:
-
在 AWS Glue 主控台中,從左側選單選擇資料目錄下的資料庫。
-
選擇建立資料型錄。
-
在建立資料庫頁面中輸入資料庫的名稱。在位置 - 選用區段中,選擇瀏覽 Amazon S3並選取 Amazon S3 儲存貯體。如果您還沒有設定好 Amazon S3 儲存貯體,您可以跳過此步驟,稍後再回來。
-
(選用)。輸入資料庫的說明。
-
選擇建立資料庫。
-
-
選擇建立筆記本。
-
建立您的筆記本後,選擇執行。
-
筆記本成功啟動後,選擇在 Apache Zeppelin 中開啟來啟動 Zeppelin 筆記本。
-
在 Zeppelin 筆記本頁面上,選擇建立新的筆記並將其命名為 MarketDataFeed。
Flink SQL 程式碼解釋如下,但首先,這是 Zeppelin 筆記本的畫面
Amazon Managed Service for Apache Flink Studio 程式碼
Amazon Managed Service for Apache Flink Studio 使用 Zeppelin 筆記本來運行程式碼。此範例以 Apache Flink 1.13 為基礎映射到 ssql 程式碼。Zeppelin 筆記本中的程式碼如下所示,一次一個區塊。
在您的 Zeppelin 筆記本運行任何程式碼前,必須運行 Flink 組態命令。如果您需要在執行程式碼 (ssql、Python 或 Scala) 後變更任何組態設定,則必須停止並重新啟動筆記本。在此範例中,您必須設定檢查點。需要檢查點,才能將資料串流到 Amazon S3 中的檔案。這可將串流至 Amazon S3 的資料排清到檔案中。下列陳述式會將間隔設定為 5000 毫秒。
%flink.conf execution.checkpointing.interval 5000
%flink.conf 表示此區塊為組態陳述式。如需 Flink 組態的詳細資訊,包括檢查點,請參閱 Apache Flink 檢查點
使用下列 Flink ssql 程式碼建立來源 Amazon Kinesis Data Streams 的輸入資料表。請注意,TRADE_TIME 字段會儲存由資料生成器創建的日期/時間。
%flink.ssql DROP TABLE IF EXISTS TRADE_SOURCE_STREAM; CREATE TABLE TRADE_SOURCE_STREAM (--`arrival_time` TIMESTAMP(3) METADATA FROM 'timestamp' VIRTUAL, TRADE_TIME TIMESTAMP(3), WATERMARK FOR TRADE_TIME as TRADE_TIME - INTERVAL '5' SECOND,TICKER STRING,PRICE DOUBLE, STATUS STRING)WITH ('connector' = 'kinesis','stream' = 'TRADE_SOURCE_STREAM', 'aws.region' = 'us-east-1','scan.stream.initpos' = 'LATEST','format' = 'csv');
您可以使用以下陳述式查看輸入串流:
%flink.ssql(type=update)-- testing the source stream select * from TRADE_SOURCE_STREAM;
在彙總資料傳送到 Amazon S3 之前,您可以用翻轉視窗選擇查詢在 Amazon Managed Service for Apache Flink 中直接檢視該資料。這會在一分鐘的時間範圍內彙總交易資料。請注意,%flink.ssql 陳述式必須具有 (類型 = 更新) 指定:
%flink.ssql(type=update) select TUMBLE_ROWTIME(TRADE_TIME, INTERVAL '1' MINUTE) as TRADE_WINDOW, TICKER, COUNT(*) as VOLUME, AVG(PRICE) as AVG_PRICE, MIN(PRICE) as MIN_PRICE, MAX(PRICE) as MAX_PRICE FROM TRADE_SOURCE_STREAMGROUP BY TUMBLE(TRADE_TIME, INTERVAL '1' MINUTE), TICKER;
然後,您可以在 Amazon S3 中建立目的地路由表。您必須使用浮水印。浮水印是一種進度指標,指出您確信不會再有延遲事件的時間點。浮水印是為了因應遲到的情形。間隔 ‘5’ Second 允許交易延遲 5 秒進入 Amazon Kinesis Data Stream,如果在視窗內有時間戳記,則仍會包含在內。如需詳細資訊,請參閱產生浮水印
%flink.ssql(type=update) DROP TABLE IF EXISTS TRADE_DESTINATION_S3; CREATE TABLE TRADE_DESTINATION_S3 ( TRADE_WINDOW_START TIMESTAMP(3), WATERMARK FOR TRADE_WINDOW_START as TRADE_WINDOW_START - INTERVAL '5' SECOND, TICKER STRING, VOLUME BIGINT, AVG_PRICE DOUBLE, MIN_PRICE DOUBLE, MAX_PRICE DOUBLE) WITH ('connector' = 'filesystem','path' = 's3://trade-destination/','format' = 'csv');
此陳述式會將資料插入到 TRADE_DESTINATION_S3。TUMPLE_ROWTIME 是翻轉視窗包容性上界的時間戳記。
%flink.ssql(type=update) insert into TRADE_DESTINATION_S3 select TUMBLE_ROWTIME(TRADE_TIME, INTERVAL '1' MINUTE), TICKER, COUNT(*) as VOLUME, AVG(PRICE) as AVG_PRICE, MIN(PRICE) as MIN_PRICE, MAX(PRICE) as MAX_PRICE FROM TRADE_SOURCE_STREAM GROUP BY TUMBLE(TRADE_TIME, INTERVAL '1' MINUTE), TICKER;
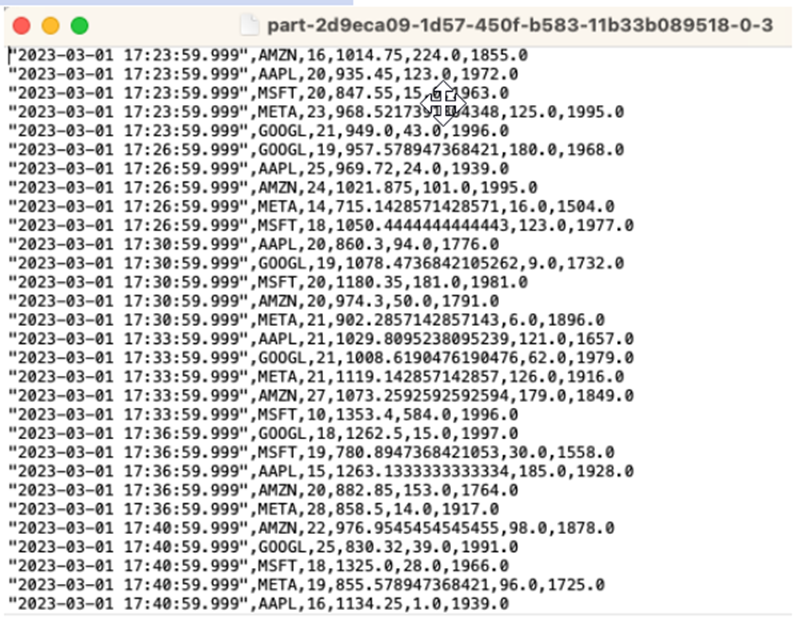
讓陳述式執行 10 到 20 分鐘,以便在 Amazon S3 中累積一些資料。然後中止你的陳述式。
此舉會關閉 Amazon S3 中的檔案,讓其成為可檢視狀態。
以下是內容的樣子:
您可以使用AWS CloudFormation 範本
AWS CloudFormation 會在您的帳戶中建立下列資源 AWS :
-
Amazon Kinesis Data Streams
-
Amazon Managed Service for Apache Flink Studio
-
AWS Glue 資料庫
-
Amazon S3 儲存貯體
-
適用於 Amazon Managed Service for Apache Flink Studio,可存取適當資源的 IAM 角色和政策
匯入筆記本,並使用 建立的新 Amazon S3 儲存貯體變更 Amazon S3 儲存貯體名稱 AWS CloudFormation。

查看更多
以下是一些額外的資源,您可以用來進一步了解如何使用 Managed Service for Apache Flink Studio:
該模式的目的是示範如何在 Kinesis Data Analytics-Studio Zeppelin 筆記本中運用 UDF,以處理 Kinesis 串流中的資料。Managed Service for Apache Flink Studio 使用 Apache Flink 提供進階分析功能,包括一次性處理語意、事件時段、使用使用者定義函數和客戶整合的可擴展性、命令式語言支援、持久的應用程式狀態、水平擴展、支援多個資料來源、可擴展整合等。這些對於確保資料串流處理的準確性,完整性,一致性和可靠性至關重要,且無法由 Amazon Kinesis Data Analytics for SQL 提供。
在此範例應用程式中,我們將示範如何利用 KDA-Studio Zeppelin 筆記本中的 UDF 來處理 Kinesis 串流中的資料。適用於 Kinesis Data Analytics 的 Studio 筆記本可讓您即時以互動方式查詢資料串流,並使用標準 SQL、Python 和 Scala 輕鬆建置和執行串流處理應用程式。只要在 中按幾下滑鼠 AWS Management Console,您就可以啟動無伺服器筆記本來查詢資料串流,並在幾秒鐘內取得結果。如需詳細資訊,請參閱搭配 Kinesis Data Analytics for Apache Flink 使用 Studio 筆記本。
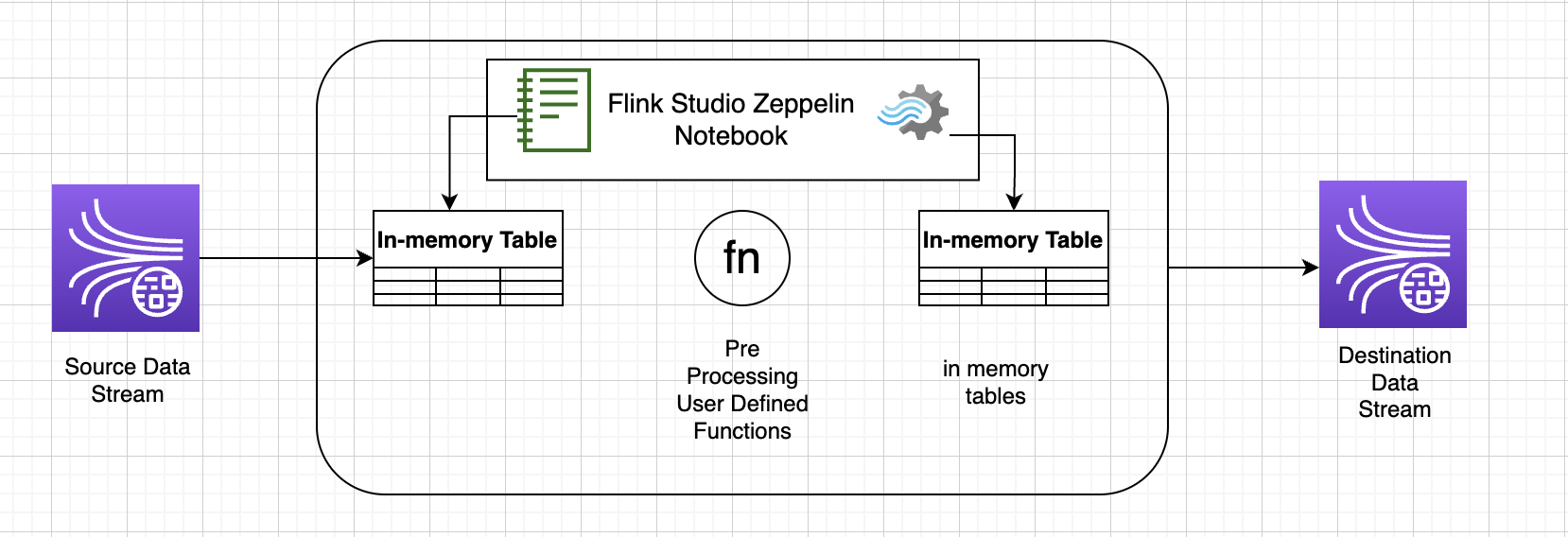
用於前/後處理 KDA-SQL 應用程式資料的 Lambda 函數:
使用 KDA-Studio Zeppelin 筆記本對資料進行前後處理的使用者定義函數
使用者定義的函數 (UDF)
若要將通用的商業邏輯重複使用到運算子中,不妨參考使用者定義函數來轉換資料串流。此舉可在 Managed Service for Apache Flink Studio 筆記本中完成,也可以將其當作外部引用的應用程式 JAR 文件。利用使用者定義的函數可以簡化轉換或資料擴充作業,這些作業可能會在串流資料上執行。
在筆記本中,您要引用一個簡單的 Java 應用程式 JAR,其具有匿名個人電話號碼的功能。您也可以編寫 Python 或 Scala UDF 以便在筆記本中使用。我們選擇了一個 Java 應用程式 JAR 來強調將應用程式 JAR 導入 Pyflink 筆記本的功能。
環境設定
若要遵循本指南並與串流資料互動,您將使用 AWS CloudFormation 指令碼來啟動下列資源:
-
Kinesis Data Streams 做為來源與目標
-
Glue 資料庫
-
IAM 角色
-
Managed Service for Apache Flink Studio 應用程式
-
啟動 Managed Service for Apache Flink Studio 應用程式的 Lambda 函數
-
執行上述 Lambda 函數的 Lambda 角色
-
用來叫用 Lambda 函數的自訂資源
在此處
建立 AWS CloudFormation 堆疊
-
前往 AWS Management Console ,然後在 服務清單下選擇 CloudFormation。
-
在CloudFormation頁面上,選擇堆疊,並選擇用新資源建立堆疊 (標準)。
-
在建立堆疊頁面上,選擇上傳範本檔案,然後選擇您先前下載的
kda-flink-udf.yml檔案。選擇檔案,然後選擇下一步。 -
給模板一個名稱便於記憶,如
kinesis-UDF。如想要不同名稱的話可更新輸入參數,如輸入串流。選擇下一步。 -
在設定堆疊選項頁面上,視需要新增標籤,然後選擇下一步。
-
在檢閱頁面,勾選允許建立 IAM 資源的方塊,然後選擇提交。
AWS CloudFormation 堆疊可能需要 10 到 15 分鐘才能啟動,視您啟動的區域而定。一旦您看到整個堆疊的 CREATE_COMPLETE 狀態,就可以繼續。
使用 Managed Service for Apache Flink Studio 筆記本
適用於 Kinesis Data Analytics 的 Studio 筆記本可讓您即時以互動方式查詢資料串流,並使用標準 SQL、Python 和 Scala 輕鬆建置和執行串流處理應用程式。只要在 中按幾下滑鼠 AWS Management Console,您就可以啟動無伺服器筆記本來查詢資料串流,並在幾秒鐘內取得結果。
筆記本是基於 Web 的開發環境。使用筆記本,您不僅能獲得簡單的互動式開發體驗,還能使用 Apache Flink 提供的進階資料串流處理功能。Studio 筆記本使用 Apache Zeppelin 支援的筆記本,並使用 Apache Flink 做為串流處理引擎。Studio 筆記本無縫結合了這些技術,讓所有技能背景的開發人員都能存取資料串流的進階分析。
Apache Zeppelin 為您的 Studio 筆記本提供了完整的分析工具套件,包括以下專案:
-
資料視覺化
-
將資料匯出到檔案
-
控制輸出格式以便於分析
使用筆記本
-
前往 AWS Management Console ,然後在服務清單下選擇 Amazon Kinesis。
-
在左側導覽頁面上,選擇分析應用程式,然後選擇 Studio 筆記本。
-
確認 KinesisDataAnalyticsStudio 筆記本正在執行。
-
選擇筆記本,然後選擇在 Apache Zeppelin 中打開。
-
下載資料生產者 Zeppelin 筆記本
檔案,您可以使用該檔案讀取資料並將其載入 Kinesis 串流。 -
匯入
Data ProducerZeppelin 筆記本。確保您有在筆記本程式碼中修改輸入STREAM_NAME和REGION。輸入串流名稱可以在 AWS CloudFormation 堆疊輸出中找到。 -
選擇執行此段落按鈕,將樣本資料插入輸入 Kinesis 資料串流,以執行資料生產者筆記本。
-
當樣本資料載入時,下載 MaskPhoneNumber-互動式筆記本
,該筆記本會讀取輸入資料,從輸入串流中匿名化電話號碼,並將匿名數據儲存到輸出流中。 -
匯入
MaskPhoneNumber-interactiveZeppelin 筆記本。 -
執行筆記本中的每個段落。
-
在第 1 段中,您可以匯入使用者定義函數來匿名化電話號碼。
%flink(parallelism=1) import com.mycompany.app.MaskPhoneNumber stenv.registerFunction("MaskPhoneNumber", new MaskPhoneNumber()) -
在下一段,請建立記憶體內資料表來讀取輸入串流資料。請確定串流名稱和 AWS 區域正確無誤。
%flink.ssql(type=update) DROP TABLE IF EXISTS customer_reviews; CREATE TABLE customer_reviews ( customer_id VARCHAR, product VARCHAR, review VARCHAR, phone VARCHAR ) WITH ( 'connector' = 'kinesis', 'stream' = 'KinesisUDFSampleInputStream', 'aws.region' = 'us-east-1', 'scan.stream.initpos' = 'LATEST', 'format' = 'json'); -
檢查資料是否已載入記憶體內資料表。
%flink.ssql(type=update) select * from customer_reviews -
調用用戶定義的功能以匿名化電話號碼。
%flink.ssql(type=update) select customer_id, product, review, MaskPhoneNumber('mask_phone', phone) as phoneNumber from customer_reviews -
現在,電話號碼已被遮罩,請創建一個帶遮罩號碼的檢視。
%flink.ssql(type=update) DROP VIEW IF EXISTS sentiments_view; CREATE VIEW sentiments_view AS select customer_id, product, review, MaskPhoneNumber('mask_phone', phone) as phoneNumber from customer_reviews -
驗證資料。
%flink.ssql(type=update) select * from sentiments_view -
為輸出 Kinesis 串流建立記憶體內資料表。請確定串流名稱和 AWS 區域正確無誤。
%flink.ssql(type=update) DROP TABLE IF EXISTS customer_reviews_stream_table; CREATE TABLE customer_reviews_stream_table ( customer_id VARCHAR, product VARCHAR, review VARCHAR, phoneNumber varchar ) WITH ( 'connector' = 'kinesis', 'stream' = 'KinesisUDFSampleOutputStream', 'aws.region' = 'us-east-1', 'scan.stream.initpos' = 'TRIM_HORIZON', 'format' = 'json'); -
在目標 Kinesis 串流中插入更新的記錄。
%flink.ssql(type=update) INSERT INTO customer_reviews_stream_table SELECT customer_id, product, review, phoneNumber FROM sentiments_view -
檢視和驗證來自目標 Kinesis 串流的資料。
%flink.ssql(type=update) select * from customer_reviews_stream_table
-
將筆記本提升為應用程式
現在您已經以互動方式測試筆記本程式碼,請將程式碼部署為具有持久狀態的串流應用程式。您必須先修改應用程式組態,以在 Amazon S3 中指定程式碼的位置。
-
在 上 AWS Management Console,選擇您的筆記本,然後在部署為應用程式組態 - 選用,選擇編輯。
-
在 Amazon S3 中的程式碼目的地中,選擇AWS CloudFormation 指令碼
建立的 Amazon S3 儲存貯體。該程序需要幾分鐘的時間。 -
您無法按原樣提升筆記。嘗試的話會出錯,因為
Select陳述式不受支援。若要避免這個問題,請下載MaskPhoneNumber - 串流 Zeppelin 筆記本。 -
匯入
MaskPhoneNumber-streamingZeppelin 筆記本。 -
開啟筆記,然後選擇 KinesisDataAnalyticsStudio 的動作。
-
選擇建立 MaskPhoneNumber - 串流並匯出至 S3。請務必重新命名應用程式名稱,且不要用特殊字元。
-
選擇建置和匯出。需要幾分鐘的時間來設定串流應用程式。
-
建置完成後,請選擇使用 AWS 主控台部署。
-
在下一頁檢閱設定,並確保選擇正確的 IAM 角色。接下來,選擇建立串流應用程式。
-
幾分鐘後,您會看到串流應用程式已成功建立的訊息。
如需部署具有持久狀態和限制之應用程式的詳細資訊,請參閱部署為具有持久狀態的應用程式。
清除
或者,您現在也可解除安裝 AWS CloudFormation 堆疊。此舉將刪除您之前設定的所有服務。
