我們不再更新 Amazon Machine Learning 服務或接受新使用者。本文件可供現有使用者使用,但我們不再更新。如需詳細資訊,請參閱什麼是 Amazon Machine Learning。
本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
迴歸模型的深入解析
解譯預測
ML 迴歸模型的輸出為數值,是此模型對於目標的預測。例如您若要預測房價,模型就可能會預測出 254,013 一類的值。
注意
預測範圍可能會與訓練資料中的目標範圍不同。例如,假設您要預測房價,而且訓練資料中目標的值範圍介於 0 到 450,000 之間。預測的目標無須在同一個範圍,而且可以接受任何正確值 (大於 450,000) 或錯誤值 (小於零)。請務必規劃如何處理落在您應用程式容許範圍以外的預測值。
衡量 ML 模型準確性
對於迴歸工作,Amazon ML 使用業界標準的均方根誤差 (RMSE) 指標。這是預測的數值目標到真實的數值答案 (真實數值) 之間的差距。RMSE 的值愈小,模型的預測正確性愈佳。模型的預測若是十分正確,其 RMSE 會是 0。下列範例顯示包含了 N 筆記錄的評估資料:

基準 RMSE
Amazon ML 提供迴歸模型的基準指標。這是假設迴歸模型的 RMSE,預策的答案一律是目標的平均值。例如,若您要預測購屋者的年齡,而訓練資料中觀察到的平均年齡為 35,則基準模型的預測答案一律是 35。您依據此基準來比較您的 ML 模型,從而確認您的 ML 模型是否優於預測此固定答案的 ML 模型。
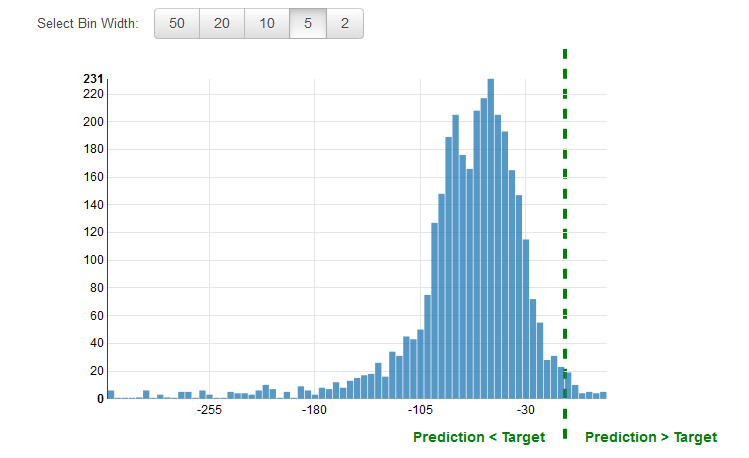
使用效能視覺化
解決回歸問題的常見做法是檢閱「殘差」。評估資料中觀察的殘差是真正目標和預測目標之間的差距。殘差代表模型無法預測的目標部分。正殘差表示模型低估目標 (實際目標大於預測目標)。負殘差表示高估 (實際目標小於預測目標)。當評估資料的殘差長條圖呈鐘形分佈並以零為中心,表示模型以隨機的方式出錯,並未系統性過度預測或不足預測目標值的任何特定範圍。若餘數未形成中心為零的鐘形,模型的預測誤差必有其特定的結構。將更多變數新增至模型可能有助於模型擷取目前模型未擷取到的模式。下圖顯示中心不是零的餘數。