本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
集中型目錄
下圖顯示集中式目錄如何連接資料湖中的資料生產者和資料消費者。
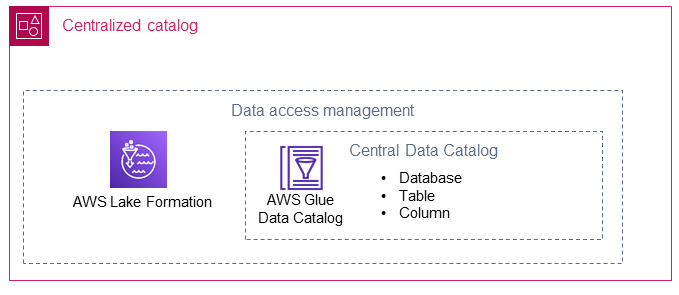
集中式目錄會存放和管理資料生產者帳戶的共用資料目錄。集中式目錄也會託管共用資料的技術中繼資料 (例如資料表名稱和結構描述),也是資料消費者存取資料的位置。
資料取用者可以從集中式目錄中的多個資料生產者存取資料,然後可以將此資料與自己的資料混合,以便進一步處理。使用集中式目錄可消除資料消費者直接與不同資料生產者連線的需求,並減少營運開銷。
由於集中式目錄可查看資料生產者和消費者的資料共用和資料消耗,因此它可以是套用集中式資料控管函數的理想位置 (例如,存取稽核)。
下列各節說明集中式目錄如何使用 AWS Lake Formation 和 AWS Glue。
AWS Lake Formation
AWS Lake Formation 有助於在 AWS Glue Data Catalog 中建立資料庫,以指向資料湖中多個資料生產者的位置。在集中式目錄中為 Lake Formation 建立 AWS Identity and Access Management (IAM) 角色。透過使用 Lake Formation,集中式目錄可以選擇性地與資料取用者共用資料資源 (例如資料庫、資料表或資料欄)。Lake Formation 受管資源會使用下列兩種方法之一與資料消費者共用:
-
具名資源方法 – 此方法跨帳戶共用受管資源。必須指定資料庫、資料表或資料欄名稱,並且可以將資源分享給組織、組織單位 (OU) 或 AWS 帳戶。為了降低共用和管理開銷,我們建議您盡可能在更高層級共用資源 (例如,在組織或 OU 中而非 AWS 帳戶)。不過,您必須確定此方法符合您組織的資料安全控制要求。
-
注意:此方法適用於具有應用程式類型的資料取用者,其中 AWS 服務取用資料生產者的資料。這類資料取用者的資料存取需求是應用程式驅動型、規範性且相對靜態。
-
-
Lake Formation 標籤型存取控制 (LF-TBAC) 方法 – LF-TBAC 特別適用於具有資料服務類型的資料取用者。不過,Lake Formation 標記的資源目前只能在 AWS 帳戶 層級共用,不能在組織或 OU 層級共用。
AWS Glue
您必須在 中 AWS Glue 為集中式目錄中的每個資料生產者建立資料庫。由於集中式目錄使用 AWS Glue 來託管來自所有資料生產者的資料庫,因此您必須確定資料庫名稱在所有資料生產者中都是唯一的,並反映資料生產者及其資料類型。例如,您可以使用下列資料庫命名結構: <Data_Producer>–<Environment>–<Data_Group>
-
<Data_Producer>– 資料生產者的名稱。 -
<Environment>– 資料湖環境,例如dev開發環境、sit系統整合測試環境或prod生產環境。 -
<Data_Group>– 資料群組的名稱,用於將資料從資料生產者分隔為邏輯群組。您可以使用來源系統名稱、ID 或縮寫做為名稱。資料庫描述也有助於描述資料庫的內容和用途。
您可以在資料生產者的資料上使用 AWS Glue 爬蟲程式,在集中式目錄的資料庫中維護其結構描述。如果資料生產者定期以相同頻率建立資料,您可以使用單一 AWS Glue 爬蟲程式。在所有其他情況下,您應該使用多個 AWS Glue 爬蟲程式來容納不同的爬蟲頻率。根據您的業務使用案例,爬蟲程式可以排程為預先定義的頻率或由事件啟動。
您也可以呼叫 AWS Glue API 來建立或更新結構描述, AWS Glue 以在 中維護資料表結構描述。雖然這可以提供彈性,但程式碼開發和維護需要額外的努力。請務必評估使用案例和商業價值,然後選擇符合您需求且額外負荷最低的選項。
