本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
區域
複雜模型的局部解釋性最流行的方法是基於沙普利加法解釋(SHAP)[8] 或集成漸變 [11]。每個方法都有許多特定於某個模型類型的變體。
對於樹木整體模型,請使用樹 SHAP
對於以樹為基礎的模型,動態編程允許快速而精確地計算每個特徵的 Shapley 值
對於神經網絡和可微分模型,請使用集成梯度和電導
整合漸層提供簡單的方式來計算神經網路中的特徵屬性。電導建立在整合漸層之上,可協助您解讀神經網路部分的屬性,例如圖層和個別神經元。請參閱 [3,11],實施網址為 https://captum.ai/
對於所有其他情況,請使用內核 SHAP
您可以使用內核 SHAP 來計算任何模型的特徵屬性,但它是計算完整 Shapley 值的近似值,並且在計算上保持昂貴的費用(請參閱 [8])。內核 SHAP 所需的計算資源隨著功能的數量而快速增長。這需要可以降低解釋保真度、重複性和穩定性的近似方法。Amazon SageMaker 澄清提供了部署預先建置容器的便利方法,以便在不同的執行個體中運算核心 SHAP 值。(舉個例子,請參閱 GitHub 存儲庫的公平性和可解釋性與 SageMaker 澄清
對於單樹模型,拆分變量和分葉值提供了一個可立即解釋的模型,並且先前討論的方法不提供額外的見解。同樣地,對於線性模型,係數提供了模型行為的清晰說明。(SHAP 和集成梯度方法都返回由係數確定的貢獻。)
SHAP 和集成基於漸變的方法都有弱點。SHAP 要求從所有圖徵組合的加權平均值導出屬性。如果圖徵之間存在強烈的相互作用,則以這種方式獲得的屬性在估計特徵重要性時可能會產生誤導。由於大型神經網路中存在大量的維度,因此很難解譯以整合漸層為基礎的方法,而且這些方法對基準點的選擇很敏感。更一般來說,模型可能會以意想不到的方式使用特徵來達到特定等級的效能,而這些效能也會隨著模型而有所不同-特徵重要性永遠是從屬於模型的
建議
下圖顯示了幾種建議的方法,以視覺化前幾節中討論的局部解釋。對於表格數據,我們建議使用一個簡單的條形圖來顯示屬性,因此可以輕鬆比較它們並用於推斷模型如何進行預測。
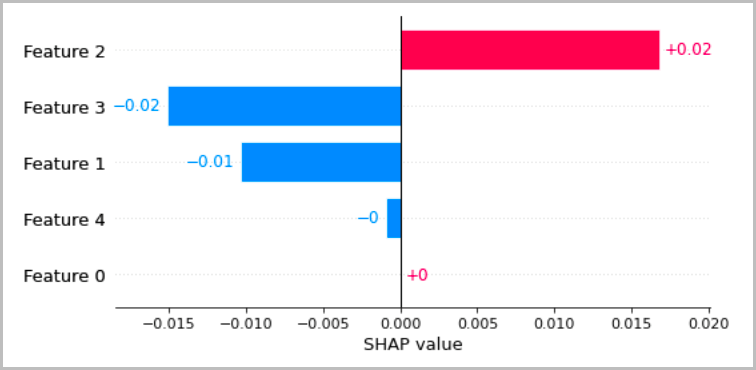
對於文本數據,嵌入令牌會導致大量的標量輸入。前幾節中建議的方法會為嵌入的每個維度和每個輸出產生歸因。為了將此信息提取到可視化中,可以對給定令牌的屬性進行求和。下列範例會顯示在 SQUDE 資料集上訓練之 BET 型問題答案模型的屬性總和。在這種情況下,預測和真實的標籤是單詞「法國」的標記。

否則,權杖屬性的向量規範可以指派為歸因值總計,如下列範例所示。

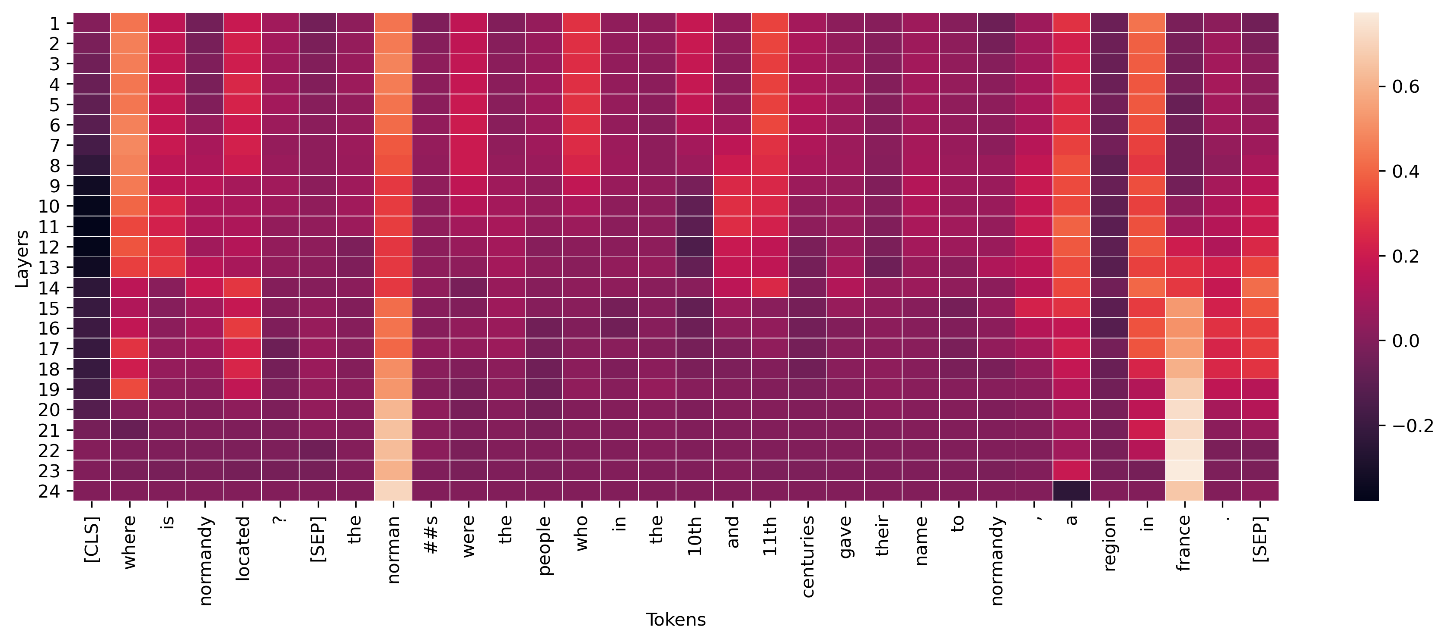
對於深度學習模型中的中間層,類似的彙總可以套用至視覺化的傳導,如下列範例所示。變壓器層的標記電導的這個向量規範顯示了結束標記預測(「法國」)的最終激活。
概念激活載體提供了一種更詳細地研究深度神經網絡的方法 [6]。此方法從已訓練過的網路中的圖層萃取圖徵,並在這些圖徵上訓練線性分類器,以對圖層中的資訊進行推論。例如,您可能想要判斷以 BET 為基礎的語言模型的哪一層包含有關語音部分的最多資訊。在這種情況下,您可以在每個圖層輸出上訓練線性 part-of-speech 模型,並粗略估計效能最佳的分類器與具有最多 part-of-speech 資訊的圖層相關聯。儘管我們不建議將其作為解釋神經網絡的主要方法,但它可以成為更詳細的研究和幫助網絡架構設計的一種選擇。
